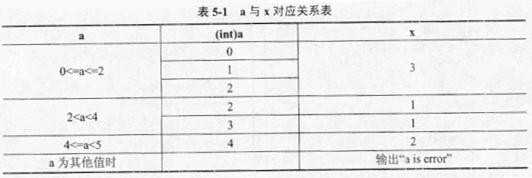
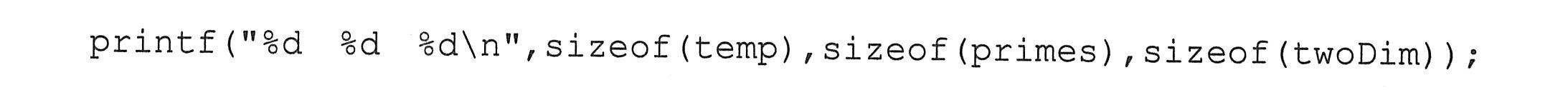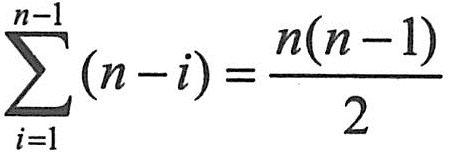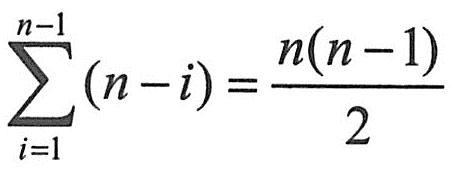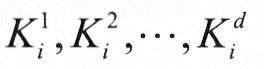|
|
|
|
|
简单排序包括直接插入排序、冒泡排序、简单选择排序等方法。
|
|
|
|
|
|
直接插入排序的基本操作是将一个记录插入到已排好序的有序表中,从而得到一个新的、记录数增1的有序表。
|
|
|
|
|
|
首先将第一个记录的关键字和第二个记录的关键字进行比较,若为逆序(即 r[1].key>r[2].key),则交换两个记录,接着比较第二个记录和第三个记录的关键字。依次类推,直至第n-1个记录和第n个记录的关键字进行过比较为止。这个过程称为第一趟冒泡排序,使得关键字最大的记录被安置到最后一个记录的位置上。然后进行第二趟冒泡排序,对前n-1个记录进行同样的操作,结果是使关键字次大的记录被安置到第n-1个记录的位置上。当进行完第n-1趟冒泡排序时,所有记录都已有序排列。
|
|
|
|
|
|
简单选择排序的基本思想是:在进行每趟排序时,从无序的记录中选择出关键字最小(或最大)的记录,将其插入到有序序列(初始时为空)的尾部。
|
|
|
|
|
|
希尔排序又称"缩小增量排序",是对直接插入排序方法的改进。希尔排序的基本思想是:先将整个待排记录序列分割成若干序列,然后分别进行直接插入排序,待整个序列中的记录基本有序时,再对全体记录进行一次直接插入排序。
|
|
|
|
|
|
快速排序是对冒泡排序的一种改进。先通过一趟排序将待排记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,然后分别对这两部分记录继续进行排序,使得整个序列有序。
|
|
|
|
|
|
|
|
对于n个元素的关键字序列{k1,k2,…,kn},当且仅当所有关键字都满足下列关系时称其为堆:
|
|
|
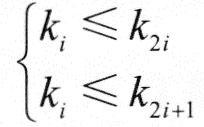 或 或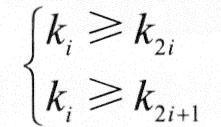
|
|
|
|
从序列元素间的关系来看,堆是一棵完全二叉树的层次序列。显然,堆顶元素为序列中n个元素的最小值(或最大值)。若堆顶为最小元素,则称为小根堆;若堆顶为最大元素,则称为大根堆。
|
|
|
|
|
|
对一组待排序记录的关键字,首先把它们按堆的定义排成一个堆序列,从而输出堆顶的最小关键字,然后将剩余的关键字再调整成新堆,便得到次小的关键字,如此反复进行,直到全部关键字排成有序序列。
|
|
|
|
|
|
归并排序是不断将多个小而有序的序列合成一个大而有序的序列的过程。其中最常用的归并排序是二路归并排序,它是将整个序列中的元素进行分组,相邻的两个元素为一组,然后分别为每个小组进行排序,随后将两个相邻的小组合成一个组,继续进行组内排序;直到所有元素被合并成一个组内,并使组内元素有序,此时排序结束。
|
|
|
|
|
|
基数排序的思想是按组成关键字的各个数位的值进行排序,它是分配排序的一种。基数排序把一个关键字Ki看成一个d元组,即
|
|
|
|
|
其中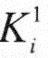 称为最高有效位,@ 称为最高有效位,@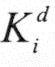 称为最低有效位。基数排序可以从最高有效位开始,也可以从最低有效位开始。 称为最低有效位。基数排序可以从最高有效位开始,也可以从最低有效位开始。
|
|
|
|
基数排序的基本思想是:设立r个队列(r为基数),队列的编号为0, 1, 2, …,r-1。首先按最低有效位的值,把n个关键字分配到这r个队列中;然后从小到大将各队列中的关键字再依次收集起来;接着再按次低有效位的值把刚收集起来的关键字再分配到r个队列中。重复上述收集过程,直至最高位有效。这样得到了一个从小到大有序的关键字序列。
|
|
|