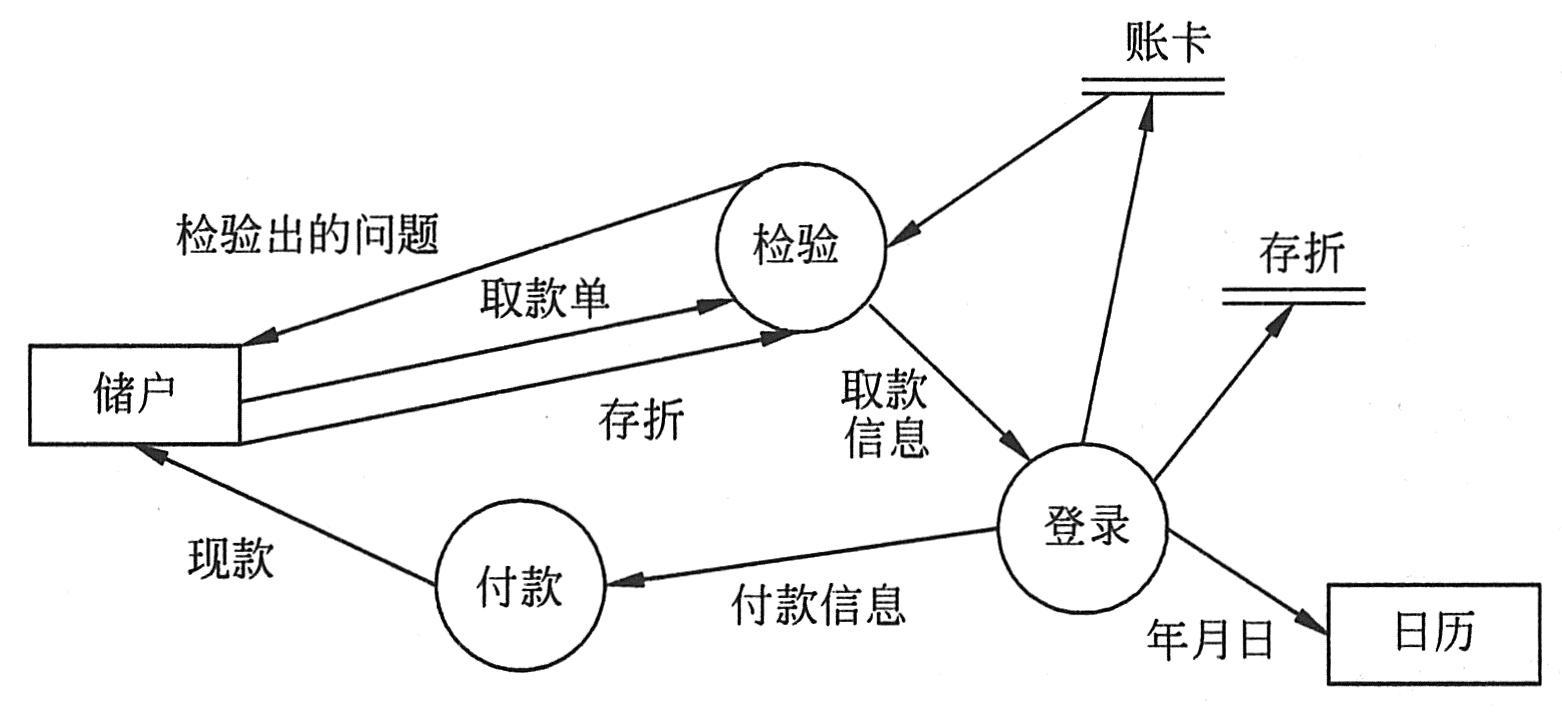
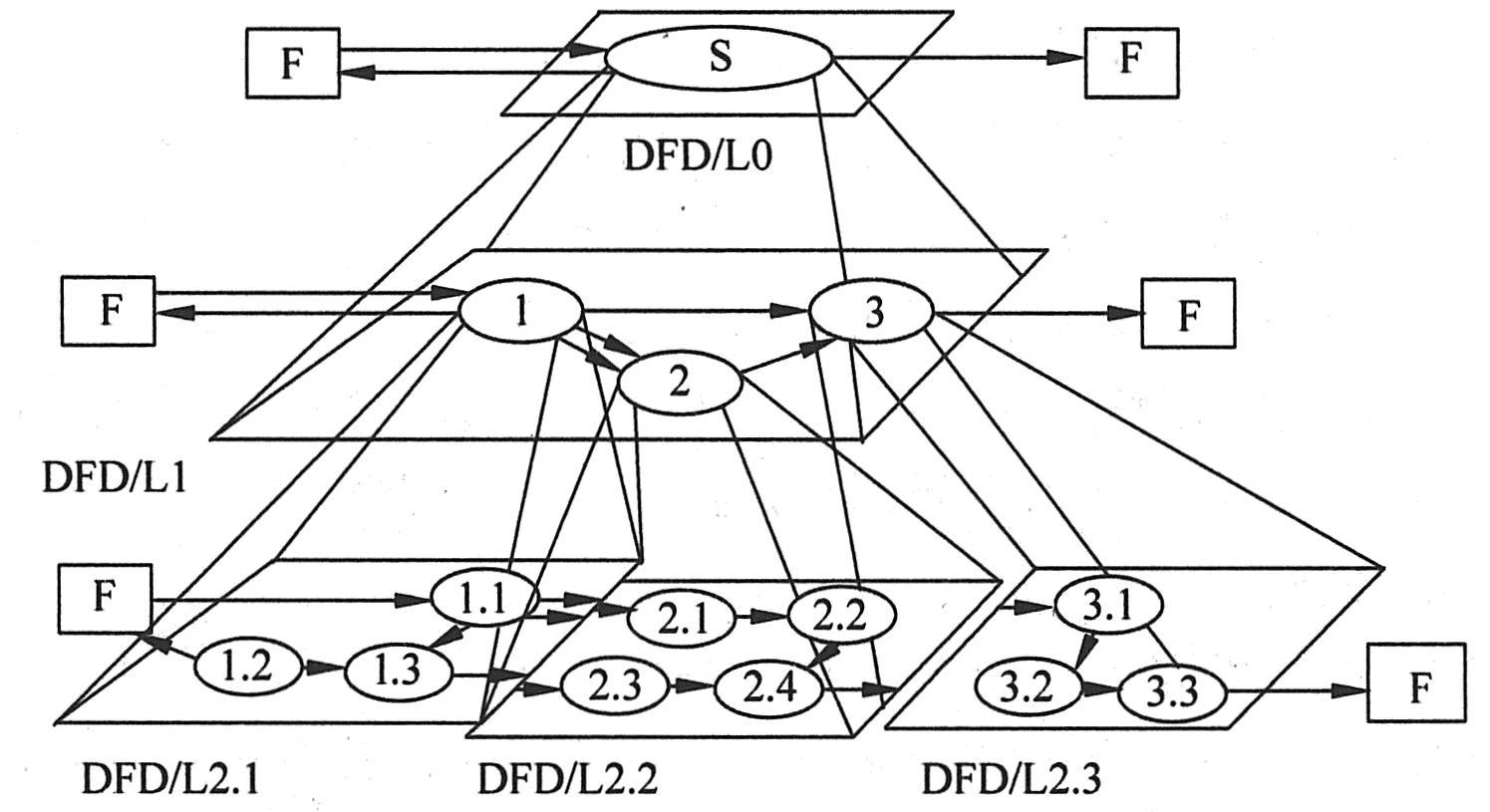
|
|
|
系统测试将软件与整个系统的硬件、外设、支持软件、数据和人员等结合起来,以需求规格说明为依据,在实际运行环境下进行测试。系统测试过程分为计划与准备、执行、返工与回归测试3个阶段,系统测试一般要完成功能测试、性能测试、恢复测试、安全测试、强度测试以及其他限制条件的测试。
|
|
|
|
系统测试由独立测试小组在测试组长的监督下进行,测试组长主要负责保证在质量控制和监督下使用测试技术执行系统测试。系统测试过程由一个独立的测试观察员来监控测试工作。
|
|
|
|
|
|
负载测试是通过测试系统在资源超负荷情况下的表现,以发现设计上的错误或验证系统的负载能力。负载测试的目标是确定并确保系统在超出最大预期工作量的情况下仍能正常运行。此外,负载测试还要评估性能特征,例如,响应时间、事务处理速率和其他与时间相关的方面。
|
|
|
|
|
|
(1)一次性加载。一次性加载某个数量的用户,在预定的时间段内持续运行。例如,在早晨上班的时间访问网站或登录网站的时间非常集中,基本属于扁平负载模式。
|
|
|
|
(2)递增加载。有规律地逐渐增加用户,每几秒增加一些新用户,交错上升。借助这种负载方式的测试,容易发现性能的拐点,即性能瓶颈。
|
|
|
|
(3)高低突变加载。某个时间用户数量很大,突然降到很低,过一段时间,又突然加到很高,反复几次。借助这种负载方式的测试,容易发现资源释放和内存泄露等问题。
|
|
|
|
(4)随机加载方式。由随机算法自动生成某个数量范围内变化的、动态的负载,这种方式可能是和实际情况最为接近的一种负载方式。虽然不容易模拟系统运行出现的瞬时高峰期,但可以模拟系统长时间的运行过程的状态。
|
|
|
|
|
|
压力测试又称为强度测试,是在强负载(加大数据量、大量并发用户等)下的测试,用于查看应用系统在峰值使用情况下的操作行为,目的是发现系统的功能隐患、系统是否具有良好的容错能力和可恢复能力。压力测试分为高负载下的长时间(如24小时以上)的稳定性压力测试和极限负载情况下导致系统崩溃的破坏性压力测试。
|
|
|
|
微软测试实践经验表明,如果软件产品通过72小时压力测试,则在72小时后出现问题的可能性微乎其微。所以,72小时成为微软产品压力测试的时间标志。
|
|
|
|
负载测试与压力测试是两个很容易混淆的概念。负载测试是通过逐步增加系统负载,测试其变化,看最后在满足性能的情况下,系统最多能接受多大负载的测试。压力测试是在满足性能的情况下,能使系统处于失效的状态,通俗来说,就是发现在什么条件下,系统的性能会变得不可接受。
|
|
|
|
|
|
|
|
②简单压力缺陷修正后,增加系统的压力直到系统崩溃。
|
|
|
|
因此,负载压力测试的主要目的是度量应用系统的性能和扩展性。在实施并发负载过程中,通过实时性能监测来确认和查找问题,并针对所发现的问题对系统性能进行优化。负载压力测试工具能够对整个企业架构进行测试,通过这些测试,企业能最大限度地缩短测试时间,优化性能和加速应用系统的发布周期。
|
|
|
|
|
|
软件可靠性是软件质量的一个重要标志。美国电气和电子工程师协会(IEEE)将软件可靠性定义为:系统在特定的环境下,在给定的时间内无故障地运行的概率。软件可靠性涉及软件的性能、功能、可用性、可服务性、可安装性,以及可维护性等多方面特性,是对软件在设计、生产以及在它所预定环境中具有所需功能的置信度的一个度量。
|
|
|
|
可靠性测试一般伴随着强壮性测试,是评估软件在运行时的可靠性,通过测试确认平均无故障时间(Mean Time to Failure,MTTF)、故障发生前平均工作时间(Mean-Time-To-First-Failure,MTTFF)或因故障而停机的时间(Mean Time To Repairs,MTTR)在一年中应不超过多少时间。可靠性测试强调随机输入,并通过模拟系统实现,很难通过实际系统的运行来实现。
|
|
|
|
|
|
安全性测试是测试系统在应付非授权的内部/外部访问、非法侵入或故意的损坏时的系统防护能力,检验系统有能力使可能存在的内/外部的伤害或损害的风险限制在可接受的水平内。可靠性通常包括安全性,但是软件的可靠性不能完全取代软件的安全性。安全性还涉及到数据加密、保密和存取权限等多个方面。
|
|
|
|
安全性测试需要设计一些测试用例试图突破系统的安全保密措施,检验系统是否有安全保密漏洞,验证系统的保护机制是否能够在实际中不受到非法的侵入。在安全测试过程中,测试者扮演成试图攻击系统的角色,尝试获取系统密码,利用能够瓦解任何防守的客户软件攻击系统;或者把系统“制服”,使别人无法访问。
|
|
|
|
安全性测试是要检验在系统中已经存在的系统安全性、保密性措施是否发挥作用,有无漏洞。破坏系统保护机构的主要方法有以下几种:
|
|
|
|
(1)正面攻击或从侧面、背面攻击系统中易受损坏的那些部分。
|
|
|
|
(2)以系统输入为突破口,利用输入的容错性进行正面攻击。
|
|
|
|
(3)申请和占用过多的资源压垮系统,以破坏安全措施,从而进入系统。
|
|
|
|
(4)故意使系统出错,利用系统恢复的过程,窃取用户口令及其他有用的信息。
|
|
|
|
(5)通过浏览残留在计算机各种资源中的垃圾(无用信息),以获取如口令、安全码和译码关键字等信息。
|
|
|
|
(6)浏览全局数据,期望从中找到进入系统的关键字。
|
|
|
|
(7)浏览那些逻辑上不存在,但物理上还存在的各种记录和资料等。
|
|
|
|
|
|
(1)检验和测试网络软件中涉及数据传输各部分的配量对安全的影响。
|
|
|
|
|
|
|
|
|
|
|
|
(6)HTML源码中是否有敏感的信息或没有必须出现的信息。
|
|
|
|
|
|
兼容性/配置测试用于测试软件与先前发布过的版本、有依赖关系的外部软件、运行的系统的各种版本和硬件平台的不同配置的兼容情况。
|
|
|
|
|
|
(1)检查版本是否兼容。检查新版本操作习惯与老版本是否兼容,目的是使老版本的用户很快地适应新版本的变化。
|
|
|
|
(2)检查数据格式是否兼容。数据格式有许多种形式,如文件格式、网络协议和共享数据等。例如,通信协议软件版本升级后,检查升级版本和老版本的通信协议是否一致等。
|
|
|
|
(3)检查系统调用的兼容性。检查系统的哪些功能依赖于系统调用,是否属于某个平台或版本独有,是否在不同平台上有差异。
|
|
|
|
(4)检查是否支持操作系统、数据库系统、硬件和软件平台。配置测试用例设计主要指软硬件环境配置的测试用例,检查计算机系统内各个设备或各种资源之间的相互关联和功能分配中的错误。
|
|
|
|
|
|
容错性测试是检查软件在异常条件下自身是否具有防护性措施或者灾难恢复手段。如当系统出错时,能否在指定时间间隔内修正错误并重新启动。可以把容错性测试看作是由系统异常处理测试和恢复测试组成的。
|
|
|
|
|
|
可用性是指系统正常运行的能力和用户接受的程度,一般用如下公式表示。
|
|
|
|
可用性=平均正常工作时间/(平均正常工作时间+平均修复时间)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
(9)硬件故障(硬盘、控制器、网络设备、服务器、电源、内存和CPU)。
|
|
|
|
(10)环境问题(电源、冷却、火、洪水、灰尘、自然灾害)。
|
|
|
|
|
|
(1)使用集群。集群是指将至少两个系统连接到一起,像一个系统那样工作。当某一系统出现失效时,集群提供即时故障转移服务。
|
|
|
|
(2)使用网络负载平衡。当检测某服务器失败后,网络负载平衡自动将通信量重新分发给仍然运行的服务器。
|
|
|
|
(3)使用服务级别协议。可用性指标的期望服务级别要求达到4个或5个“9”。例如,“该应用程序应每周运行7天,每天24小时,年可用性为99.99%”是指全年不能正常工作的时间仅仅只有52分钟,不足1个小时。
|
|
|
|
(4)提供实时的监视。监视系统的工作负荷和失败数据,实时监视对于发现趋势和改善服务至关重要。
|
|
|
|
|
|
(6)检查所有的安全计划。安全性是确保应用程序服务只对有权使用系统的用户可用,还意味着使得应用程序使用的所有分布式组件和资源受到保护。
|
|
|
|
|
|
文档测试是指对软件开发、测试和维护过程中产生的所有文档的测试,包括对需求规格分析说明书、详细设计报告、系统设计报告、用户手册以及与系统相关的一切文档的审阅和评测。例如,系统需求分析和系统设计说明书中的错误将直接导致编码的错误,用户手册作为软件的一部分,将直接影响用户对系统的使用效果。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|