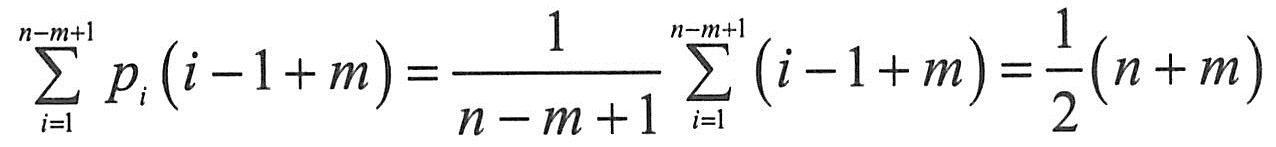|
|
|
字符串是一串文字及符号的简称,是一种特殊的线性表。字符串的基本数据元素是字符,计算机中非数值问题处理的对象经常是字符串数据,如在汇编和高级语言的编译程序中,源程序和目标程序都是字符串数据;在事务处理程序中,姓名、地址等一般也是作为字符串处理的。另外,串还具有自身的特性,常常把一个串作为一个整体来处理。这里简单介绍串的定义、基本运算和存储结构。
|
|
|
|
|
|
串是仅由字符构成的有限序列,是取值范围受限的线性表。一般记为S='a1a2…an',其中S是串名,单引号括起来的字符序列是串值。
|
|
|
|
|
|
|
|
.空格串:由一个或多个空格组成的串。虽然空格是一个空白符,但它也是一个字符,计算串长度时要将其计算在内。
|
|
|
|
.子串:由串中任意长度的连续字符构成的序列称为子串。含有子串的串称为主串。子串在主串中的位置指子串首次出现时,该子串的第一个字符在主串的位置。空串是任意串的子串。
|
|
|
|
.串相等:指两个串长度相等且对应位置上的字符也相同。
|
|
|
|
.串比较:两个串比较大小时以字符的ASCII码值作为依据。比较操作从两个串的第一个字符开始进行,字符的ASCII码值大者所在的串为大;若其中一个串先结束,则以串长较大者为大。
|
|
|
|
|
|
①赋值操作StrAssign(s,t):将串t的值赋给串s。
|
|
|
|
②连接操作Concat(s,t):将串t接续在串s的尾部,形成一个新串。
|
|
|
|
③求串长StrLength(s):返回串s的长度。
|
|
|
|
④串比较StrCompare(s,t):比较两个串的大小。返回值-1、0和1分别表示st三种情况。
|
|
|
|
⑤求子串SubString(s,start,len):返回串s中从start开始的、长度为len的字符序列。
|
|
|
|
|
|
|
|
(1)顺序存储。该方式是用一组地址连续的存储单元来存储串值的字符序列。由于串中的元素为字符,所以可通过程序语言提供的字符数组定义串的存储空间(即存储空间的容量固定),也可以根据串长的需要动态申请字符串的空间(即存储空间的容量可扩充或缩减)。
|
|
|
|
(2)链式存储。字符串也可以采用链表作为存储结构,当用链表存储串中的字符时,每个结点中可以存储一个字符,也可以存储多个字符,需要考虑存储密度问题。结点大小为4的块链如下图所示。
|
|
|
|
|
|
|
|
在链式存储结构中,结点大小的选择和顺序存储方法中数组空间大小的选择一样重要,它直接影响对串处理的效率。
|
|
|
|
通常情况下,字符串存储在一维字符数组中,每个字符串的末尾都有一个串结束符,在C/C++程序中以特殊字符“\0”作为结束标记。
|
|
|
|
|
|
大多数的程序语言在其开发资源包中都提供了字符串的赋值(拷贝)、连接、比较、求串长、求子串等基本运算,利用它们就可以实现关于串的其他运算。下面简要介绍求串长和串比较运算的实现。
|
|
|
|
【函数】求串长,即计算给定串中除结束标志字符'\0'之外的字符数目。
|
|
|
|
|
|
|
|
对于串s1和s2,比较过程为:从两个串的第一个字符开始,若串s1和s2的对应字符相同,则继续比较下一对字符;若串s1的对应字符大于s2的相同位置字符,则串s1大于s2,否则s1小于s2。返回值0表示s1和s2的长度及对应字符完全相同,其他返回值则表示两个串中第一个不同字符的编码差值。
|
|
|
|
|
|
|
|
子串(也称为模式串)在主串中的定位操作通常称为串的模式匹配,它是各种串处理系统中最重要的运算之一。
|
|
|
|
|
|
该算法也称为布鲁特一福斯算法,其基本思想是从主串的第一个字符起与模式串的第一个字符比较,若相等,则继续下一对字符的比较,否则从主串的第二个字符起与模式串的第一个字符重新开始比较,直至模式串中每个字符依次和主串中的一个连续的字符序列相等时为止,此时称为匹配成功,否则称为匹配失败。
|
|
|
|
【函数】以字符数组存储字符串,实现朴素的模式匹配算法。
|
|
|
|
|
|
假设主串的长度为n,模式串的长度为m,下面分析朴素模式匹配算法的时间复杂度,位置序号从1开始计算。设从主串的第i个位置开始与模式串匹配成功,而在前i-1趟匹配中,每趟不成功的匹配都是模式串的第一个字符与主串中相应的字符不相同,则在前i-1趟匹配中,字符的比较共进行了i-1次,因第i趟成功匹配的字符比较次数为m,所以总的字符比较次数为(i-1+m)且1≤i≤n-m+1。若在这n-m+1个起始位置上匹配成功的概率相同,则在最好情况下,匹配成功时字符间的平均比较次数为:
|
|
|
|
|
|
因此,在最好情况下匹配算法的时间复杂度为O(n+m)。而在最坏的情况下,每一趟不成功的匹配都是模式串的最后一个字符与主串中相应的字符不相等。若第i趟匹配时成功,则前i-1趟不成功的匹配加上最后一趟成功的匹配,每趟的字符比较次数都是m次,总共比较了i×m次。因此,最坏情况下的平均比较次数为:
|
|
|
|
|
|
由于n?m,所以该算法在最坏情况下的时间复杂度为O(n×m)。
|
|
|
|
|
|
改进的模式匹配算法又称为KMP算法(由D.E.Knuth、V.R.Pratt和J.H.Morris提出),其改进之处在于:每当匹配过程中出现相比较的字符不相等时,不需要回溯主串字符的位置指针,而是利用已经得到的“部分匹配”的结果,将模式串向后“滑动”尽可能远的距离,再继续进行比较。此算法可在O(n+m)的时间内完成。
|
|
|