|
|
|
Cache的功能是提高CPU数据输入输出的速率,突破所谓的“冯.诺依曼瓶颈”,即CPU与存储系统间数据传送带宽限制。高速存储器能以极高的速率进行数据的访问,但因其价格高昂,如果计算机的内存完全由这种高速存储器组成则会大大增加计算机的成本。通常在CPU和内存之间设置小容量的高速存储器Cache。Cache容量小但速度快,内存速度较低但容量大,通过优化调度算法,系统的性能会大大改善,仿佛其存储系统容量与内存相当而访问速度近似Cache。
|
|
|
|
|
|
使用Cache改善系统性能的依据是程序的局部性原理。依据局部性原理,把内存中访问概率高的内容存放在Cache中,当CPU需要读取数据时就首先在Cache中查找是否有所需内容,如果有,则直接从Cache中读取;若没有,再从内存中读取该数据,然后同时送往CPU和Cache。如果CPU需要访问的内容大多都能在Cache中找到(称为访问命中),则可以大大提高系统性能。
|
|
|
|
如果以h代表对Cache的访问命中率(“1-h”称为失效率,或者称为未命中率),t1表示Cache的周期时间,t2表示内存的周期时间,以读操作为例,使用“Cache+主存储器”的系统的平均周期为t3。则:
|
|
|
|
|
|
系统的平均存储周期与命中率有很密切的关系,命中率的提高即使很小也能导致性能上的较大改善。
|
|
|
|
例如,设某计算机主存的读/写时间为100ns,有一个指令和数据合一的Cache,已知该Cache的读/写时间为10ns,取指令的命中率为98%,取数的命中率为95%。在执行某类程序时,约有1/5指令需要存/取一个操作数。假设指令流水线在任何时候都不阻塞,则设置Cache后,每条指令的平均访存时间约为:
|
|
|
|
(2%×100ns+98%×10ns)+1/5×(5%×100ns+95%×10ns)=14.7ns
|
|
|
|
|
|
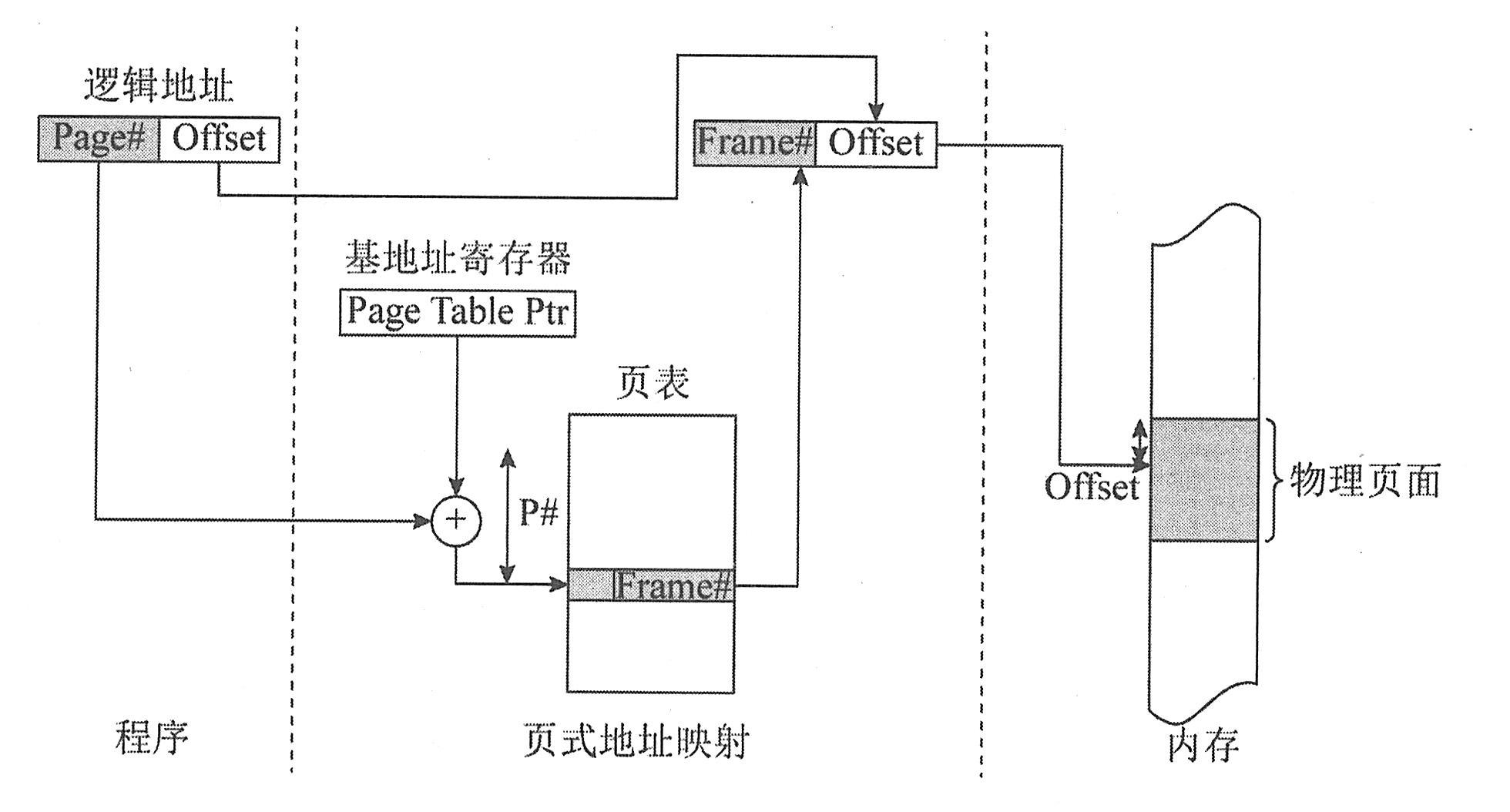
当CPU发出访存请求后,存储器地址先被送到Cache控制器以确定所需数据是否已在Cache中,若命中则直接对Cache进行访问。这个过程被称为Cache的地址映射(映像)。在Cache的地址映射中,主存和Cache将均分成容量相同的块(页)。常见的映射方法有直接映射、全相联映射和组相联映射。
|
|
|
|
(1)直接映射。直接映射方式以随机存取存储器作为Cache存储器,硬件电路较简单。直接映射是一种多对一的映射关系,但一个主存块只能够复制到Cache的一个特定位置上去。
|
|
|
|
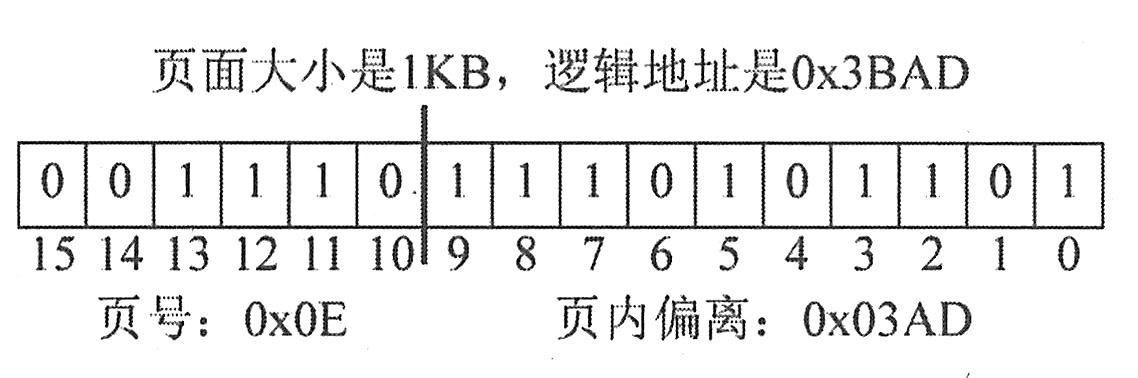
例如,某Cache容量为16KB(即可用14位表示),每块的大小为16B(即可用4位表示),则说明其可分为1024块(可用10位表示)。则主存地址的最低4位为Cache的块内地址,然后接下来的中间10位为Cache块号。如果内存地址为1234E8F8H的话(一共32位),那么最后4位就是1000(对应十六进制数的最后一位“8”),而中间10位,则应从E8F(1110 1000 1111)中获取,得到10 1000 1111。因此,内存地址为1234E8F8H的单元装入的Cache地址为10 1000 1111 1000。
|
|
|
|
直接映射方式的优点是比较容易实现,缺点是不够灵活,有可能使Cache的存储空间得不到充分利用。例如,假设Cache有8块,则主存的第1块与第17块同时复制到Cache的第1页,即使Cache其他页面空闲,也有一个主存页不能写入Cache。
|
|
|
|
(2)全相联映射。全相联映射使用相联存储器组成的Cache存储器。在全相联映射方式中,主存的每一页可以映射到Cache的任一页。如果淘汰Cache中某一页的内容,则可调入任一主存页中的内容,因而较直接映射方式灵活。
|
|
|
|
在全相联映射方式中,主存地址不能直接提取Cache页号,而是需要将主存页标记与Cache各页的标记逐个比较,直到找到标记符合的页(访问Cache命中),或者全部比较完后仍无符合的标记(访问Cache失败)。因此这种映射方式速度很慢,失掉了高速缓存的作用,这是全相联映射方式的最大缺点。如果让主存页标记与各Cache标记同时比较,则成本又太高。全相联映像方式因比较器电路难于设计和实现,只适用于小容量Cache。
|
|
|
|
(3)组相联映射。组相联映射是直接映射和全相联映射的折中方案。它将Cache中的块再分成组,通过直接映射方式决定组号,通过全相联映射的方式决定Cache中的块号。在组相联映射方式中,主存中一个组内的块数与Cache的分组数相同。
|
|
|
|
例如:容量为64块的Cache采用组相联方式映像,每块大小为128个字,每4块为一组。若主存容量为4096块,且以字编址,那么主存地址应该为多少位?主存区号(组号)为多少位?这样的题目,首先根据主存与Cache块的容量需一致,即每个内存块的大小也是128个字,因此共有128×4096个字(219个字),即主存地址需要19位。因为Cache分为16组,所以主存需要分为4096/16=256组,即28组,因此主存组号需8位。
|
|
|
|
在组相联映射中,由于Cache中每组有若干可供选择的页,因而它在映像定位方面较直接映像方式灵活;每组页数有限,因此付出的代价不是很大,可以根据设计目标选择组内页数。
|
|
|
|
|
|
当Cache产生了一次访问未命中之后,相应的数据应同时读入CPU和Cache。但是当Cache已存满数据后,新数据必须淘汰Cache中的某些旧数据。最常用的淘汰算法有随机淘汰法、先进先出法(First In and First Out, FIFO)和近期最少使用淘汰法(Least Recently Used, LRU)。其中平均命中率最高的是LRU算法。
|
|
|
|
|
|
因为需要保证缓存在Cache中的数据与内存中的内容一致,相对读操作而言,Cache的写操作比较复杂,常用的有以下几种方法。
|
|
|
|
(1)写直达(write through)。当要写Cache时,数据同时写回内存,有时也称为写通。
|
|
|
|
(2)写回(write back)。CPU修改Cache的某一行后,相应的数据并不立即写入内存单元,而是当该行从Cache中被淘汰时,才把数据写回到内存中。
|
|
|
|
(3)标记法。对Cache中的每一个数据设置一个有效位。当数据进入Cache后,有效位置1;而当CPU要对该数据进行修改时,数据只需写入内存并同时将该有效位清0。当要从Cache中读取数据时需要测试其有效位:若为1则直接从Cache中取数,否则从内存中取数。
|
|
|