|
|
|
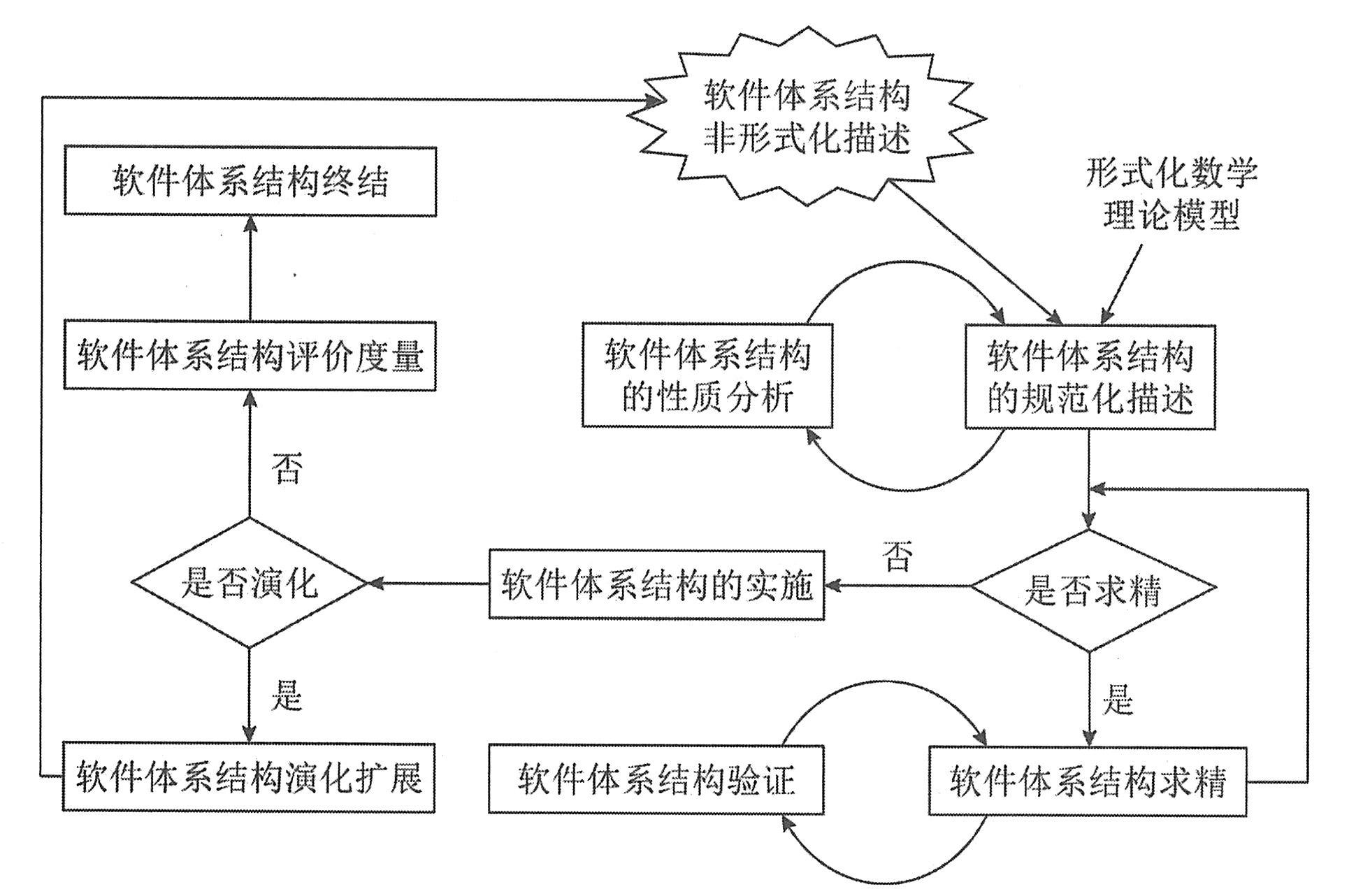
数据流图(Data Flow Diagram,DFD)是一种最常用的结构化分析工具,它从数据传递和加工的角度,以图形的方式刻画系统内数据的运动情况。数据流图是一种能全面地描述信息系统逻辑模型的主要工具,它可以用少数几种符号综合地反映出信息在系统中的流动、处理和存储的情况。数据流图具有抽象性和概括性。抽象性表现在它完全舍去了具体的物质,只剩下数据的流动、加工处理和存储;概括性表现在它可以把信息中的各种不同业务处理过程联系起来,形成一个整体。无论是手工操作部分还是计算机处理部分,都可以用它表达出来。因此,我们可以采用DFD这一工具来描述管理信息系统的各项业务处理过程。
|
|
|
|
|
|
数据流图用到4个基本符号,即外部实体、数据流、数据存储和处理逻辑,如下图所示。
|
|
|
|
|
|
|
|
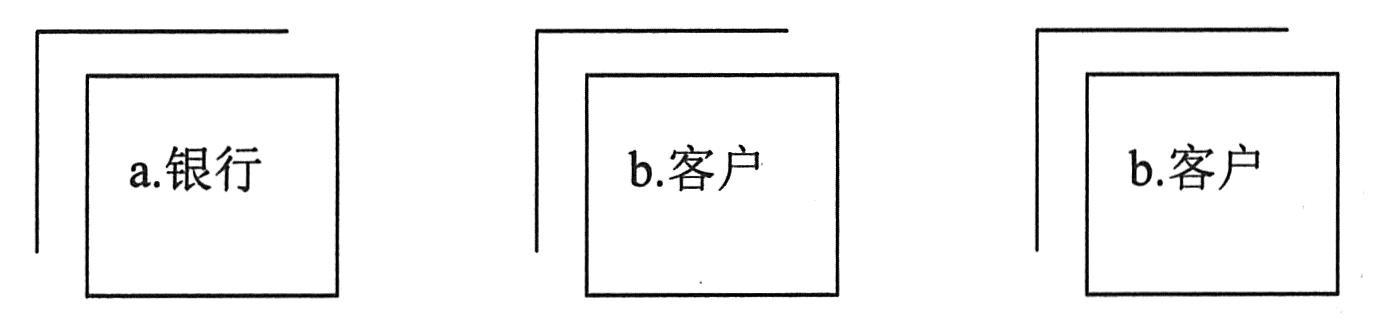
①外部实体。外部实体指不受系统控制,在系统以外又与系统有联系的事物或人,它表达了目标系统数据的外部来源或去处。例如,顾客、职工、供货单位,等等。外部实体也可以是另外一个信息系统。
|
|
|
|
外部实体用一个正方形,并在其左上角外边另加一个直角来表示,在正方形内写上该外部实体的名称。为了区分不同的外部实体,可以在正方形的左上角用一个字符表示。在数据流图中,为了减少线条的交叉,同一个外部实体在一张数据流图中可以出现多次,这是在该外部实体符号的右下角画斜线,表示重复。若重复的外部实体有多个,则相同的外部实体画数目相同的斜线,如下图所示。
|
|
|
|
|
|
|
|
②数据流。数据流表示数据的流动方向,用一个水平箭头或垂直箭头表示。数据流可以是订单、发票等。数据流一般不会是单纯的数据,而是由一些数据项组成。例如“发票”数据流由品名、规格、单位、单价、数量等数据项组成。
|
|
|
|
一般来说,对每个数据流要加以简单地描述,使用户和系统设计员能够理解一个数据流的含义。对数据流的描述写在箭头的上方,一些含义十分明确的数据流,也可以不加以说明,如下图所示。
|
|
|
|
|
|
|
|
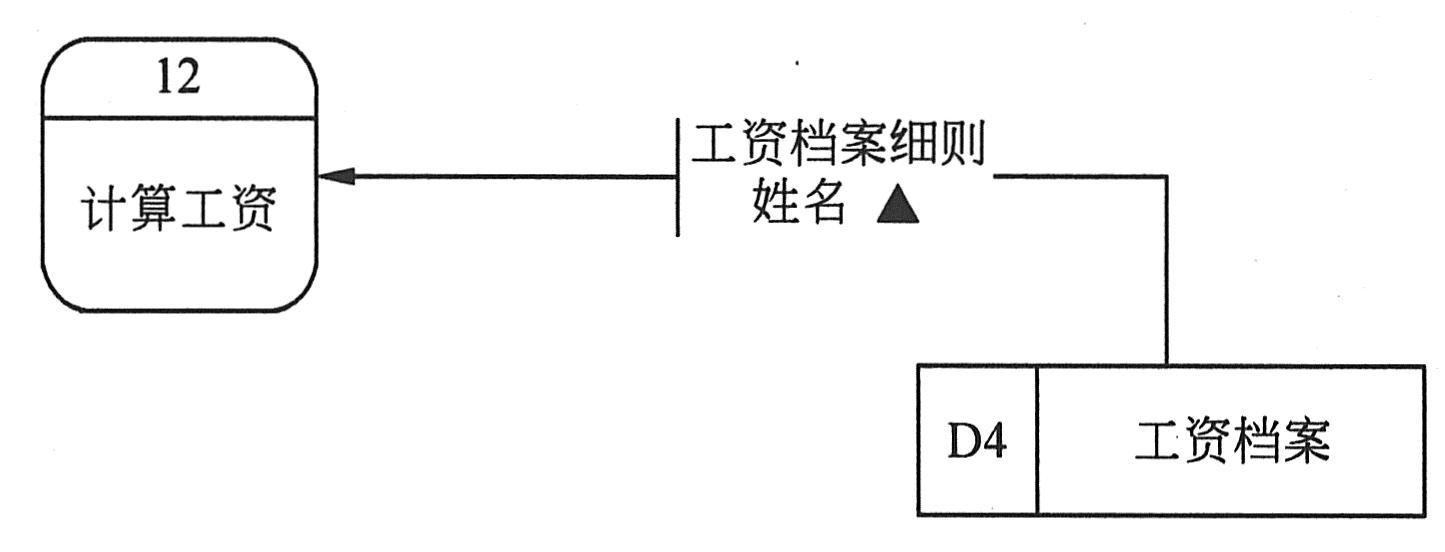
③数据存储。数据存储表示数据保存的地方。这里的“地方”并不是指保存数据的物理地点或物理介质,而是指数据存储的逻辑描述。所以这里的数据存储是逻辑意义上的数据存储环节,即系统信息处理功能需要的,不考虑存储的物理介质和技术手段的数据存储环节。
|
|
|
|
在数据流图中,数据存储用一个右边开口的长方形条来表示,图形右部填写存储的数据和数据集的名字,名字要恰当,以便用户理解。左边填写该数据存储的标识,用字母D和数字组成。同一数据存储可在一张数据流图中出现多次,这时在数据存储符号上画竖线,表示重复。
|
|
|
|
指向数据存储的箭头,表示送数据到数据存储(存放、改写等);从数据存储发出的箭头,表示从数据存储读取数据,如下图所示。
|
|
|
|
|
|
|
|
④处理逻辑(加工)处理逻辑指对数据的逻辑处理功能,也就是对数据的变换功能。它包括两方面的内容:一是改变数据结构;二是在原有数据内容基础上增加新的内容,形成新的数据。
|
|
|
|
在数据流图中,处理逻辑可以用一个带圆角的长方形来表示,长方形分为三个部分,如下图所示。
|
|
|
|
|
|
|
|
标识部分用来标明一个功能,一般用字符串表示,如P1,P1.1等。
|
|
|
|
功能描述部分是必不可少的,它直接表达这个处理逻辑的逻辑功能。一般用一个动词加一个作动词宾语的名词表示。不过要恰如其分地表达一个处理的功能,有时候需要下一番功夫。
|
|
|
|
功能执行部分表示这个功能由谁来完成,可以是一个人,也可以是一个部门,甚至可以是某个计算机程序。
|
|
|
|
|
|
由于数据流图在系统建设中的重要作用,绘制数据流图必须坚持正确的原则和运用科学的方法。绘制数据流图应遵循的主要原则如下。
|
|
|
|
①确定外部项。一张数据流图表示某个子系统或某个系统的逻辑模型。系统分析人员要根据调查材料,首先识别出那些不受所描述的系统的控制,但又影响系统运行的外部环境,这就是系统的数据输入的来源和输出的去处。要把这些因素都作为外部项确定下来。确定了系统和外部环境的界面,就可集中力量分析,确定系统本身的功能。
|
|
|
|
②自顶向下逐层扩展。信息系统庞大而复杂,具体的数据加工可能成百上千,关系错综复杂,不可能用一两张数据流图明确、具体地描述整个系统的逻辑功能,自顶向下的原则为我们绘制数据流图提供了一条清晰的思路和标准化的步骤。
|
|
|
|
③合理布局。数据流图的各种符号要布局合理,分布均匀、整齐、清晰,使读者一目了然。这才便于交流,避免产生误解。一般要把系统数据主要来源的外部项尽量安排在左方,而要把数据主要去处的外部项尽量安排在右边,数据流的箭头线尽量避免交叉或过长,必要时可用重复的外部项和重复的数据存储符号。
|
|
|
|
④数据流图只反映数据流向、数据加工和逻辑意义上的数据存储,不反映任何数据处理的技术过程、处理方式和时间顺序,也不反映各部分相互联系的判断与控制条件等技术问题。这样,只从系统逻辑功能上讨论问题,便于和用户交流。
|
|
|
|
⑤数据流图绘制过程,就是系统的逻辑模型的形成过程,必须始终与用户密切接触、详细讨论、不断修改,也要和其他系统建设者共同商讨以求一致意见。
|
|
|
|
|
|
对每个系统都有一个逐步熟悉和深化的过程,因此在画数据流图时难免会有这样或那样的错误,这就需要对数据流图做进一步的改进。一般可从下面两个方面着手。
|
|
|
|
|
|
.数据是否守恒,即输入数据与输出数据是否匹配。数据不守恒的情况有两种。一种是某个处理过程产生输出数据,但没有输入数据给该处理过程,这肯定是某些数据流被遗漏了。另一种是有输入数据给处理过程,但没有输出数据,这种情况不一定是错误,但必须认真加以推敲:为什么将这些数据输入给这个处理过程,而处理过程却不利用它产生输出?如果确实是不必要的,就可将它去掉,以简化处理逻辑之间的联系。
|
|
|
|
.数据存储的使用是否恰当。在一套数据流图中的任何一个数据存储,必定有流入的数据流和流出的数据流,即写文件和读文件,缺少任何一种都意味着遗漏了某些处理逻辑。
|
|
|
|
.父图和子图是否平衡。父图中某一处理框的输入、输出数据流必须出现在相应的子图中,否则就会出现父图与子图的不平衡。父图和子图的数据流不平衡是一种常见的错误现象。尤其是在对子图进行修改时(如添加或删除某些数据流),必须仔细检查其父图是否要做相应的修改,以保持数据流的平衡。父图与子图的关系,类似于全国地图与各省地图的关系。在全国地图上标出主要的铁路、河流,在各省地图上标得则更详细,除了有全国地图上与该省相关的铁路、河流之外,还有一些次要的铁路、公路、河流等。
|
|
|
|
.任何一个数据流至少有一端是处理框。换句话说,数据流不能从外部实体直接到数据存储,也不能从数据存储直接到外部实体,也不能在外部实体之间或数据存储之间流动。初学者往往容易违反这一规定,常常在数据存储与外部实体之间画数据流。其实,记住数据流是处理功能的输入或输出,就不会出现此类错误。
|
|
|
|
|
|
数据流图是系统分析员进行业务调查,与用户沟通的重要工具。因此,数据流图应该简明易懂。这也有利于后面的设计,有利于对系统规格说明书进行维护。可以从以下几个方面提高易理解性。
|
|
|
|
.简化处理间的联系。结构化分析的基本手段是“分解”,其目的是控制复杂性。合理的分解是将一个复杂的问题分成相对独立的几个部分,每个部分可被单独理解。在数据流图中,将一个处理逻辑分解成若干个子处理逻辑,并使各子处理逻辑尽可能地相对独立、处理逻辑间的数据流尽可能地少、每个处理逻辑的输入和输出数据流数目尽可能地少,这样每一个处理逻辑就比较容易被单独地理解,因而一个复杂的处理逻辑也就被几个较简单的子处理逻辑代替了。
|
|
|
|
.保持分解的均匀性。理想的分解是将一个加工分成大小均匀的几个子加工。如果在一张数据流图上,某几个已经是不必再分解的基本加工,而另一些加工却还要进一步分解三四层,这样的分解就不均匀。不均匀的分解是不容易被理解的。因为其中一些已是细节,而另一些仍然是较高层次上的抽象。在这种情况下应考虑重新分解,应努力避免特别不均匀的分解。
|
|
|
|
.适当命名。给数据流图中的各个成分取一个适当的名字无疑是提高其易理解性的重要手段之一。比如处理框的命名应能准确地表达其功能,理想的命名由一个具体的动词加一个具体的名词(宾语)组成,在下层尤其应该如此。例如“计算总工作量”、“开发票”。而最好将“存储和打印提货单”分成两个。“处理订货单”则不太好,“处理”是空洞的动词,没有说明究竟做什么。如果难以为某个成分取合适的名字,那么往往是分解不当的迹像,这时可以考虑重新分解。
|
|
|
|
数据流图也常常需要重新分解。例如画到某一层时意识到上一层或上几层所犯的错误,这时就需要对它们重新分解。重新分解可按下述步骤进行:
|
|
|
|
.把需要重新分解的数据流图的所有子图拼接成一张图。
|
|
|
|
.把新拼接成的图分成几个部分,使各部分之间的联系最少。
|
|
|
|
.重新建立父图,即把第②步所得的每一部分画成一个处理框。
|
|
|
|
.重新建立各张子图,这只需要把第②步所得的图沿各个部分边界分开即可。
|
|
|
|
|
|
|
|
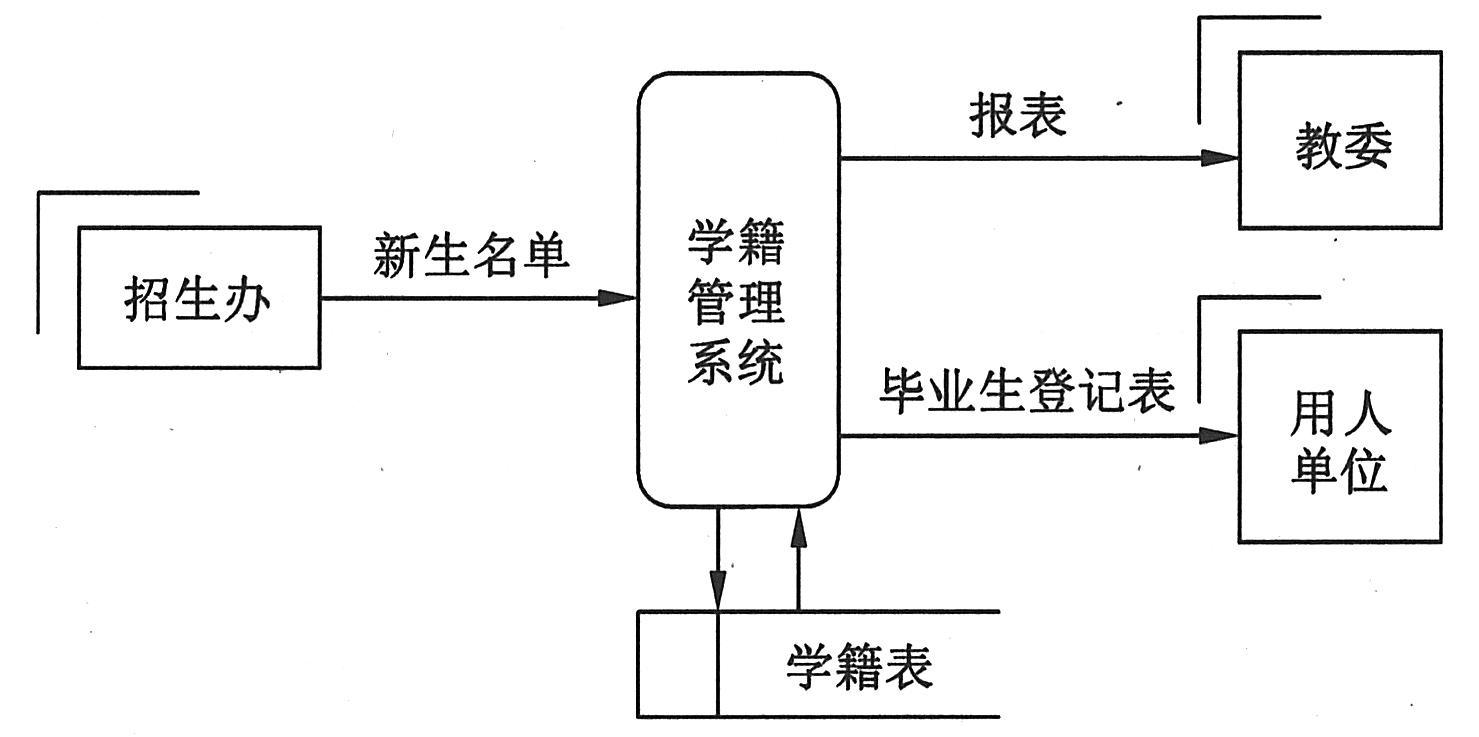
下面我们以高等学校学籍管理系统为例,说明画数据流图的方法。学籍管理是一项十分严肃而复杂的工作。它要记录学生从入学到离校,整个在校期间的情况,学生毕业时把学生的情况提供给用人单位。学校还要向上级主管部门报告学籍的变动情况。
|
|
|
|
下图一所示概括描述了系统的轮廓、范围,标出了最主要的外部实体和数据流。它是进一步分析的出发点。学籍管理包括学生学习成绩管理、学生奖惩管理、学生异动管理三个部分。由此,下图一可以展开为下图二。虚线框是下图一中处理逻辑的放大。下面以“成绩管理”为例,说明逐层分解的思路。
|
|
|
|
|
|
|
|
|
|
|
|
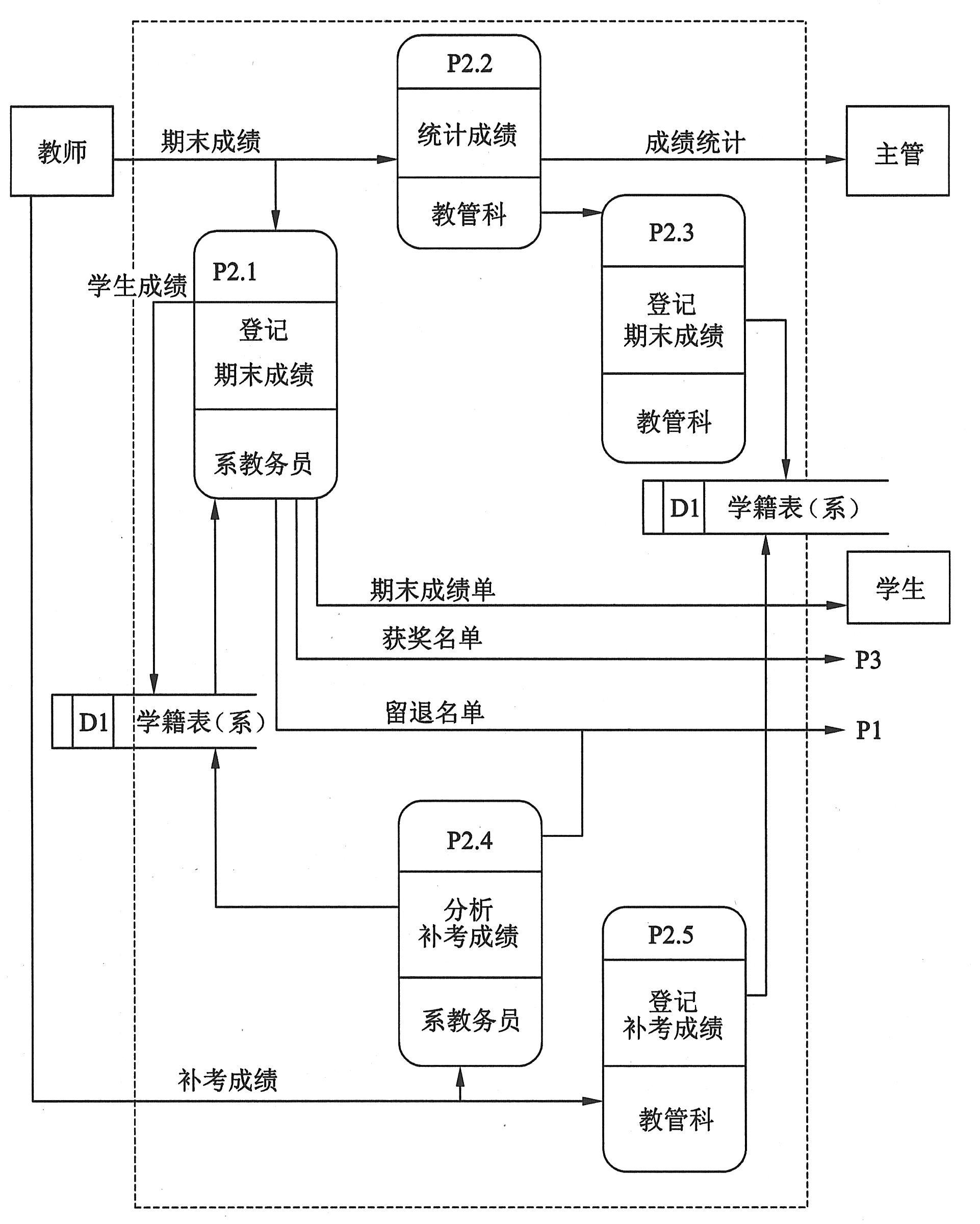
某校现在实行校、系两级管理学习成绩。学校教学管理科、系教务员都登记学生成绩。任课教师把学生成绩单一式两份分别送系教务员和学校教学管理科。系教务员根据成绩单登录学籍表,学期结束时,给学生发成绩通知,根据学籍管理条例确定每个学生升级、补考、留级、退学的情况。教学管理科根据收到的成绩单登录教管科存的学籍表,统计各年级各科成绩分布,报主管领导。补考成绩也做类似处理,这样P2框扩展成下图。
|
|
|
|
|
|
|
|
在上图中的一些处理,有的框还需要进一步展开,如P2.1框,但在这里我们不再一一展开。
|
|
|