|
|
|
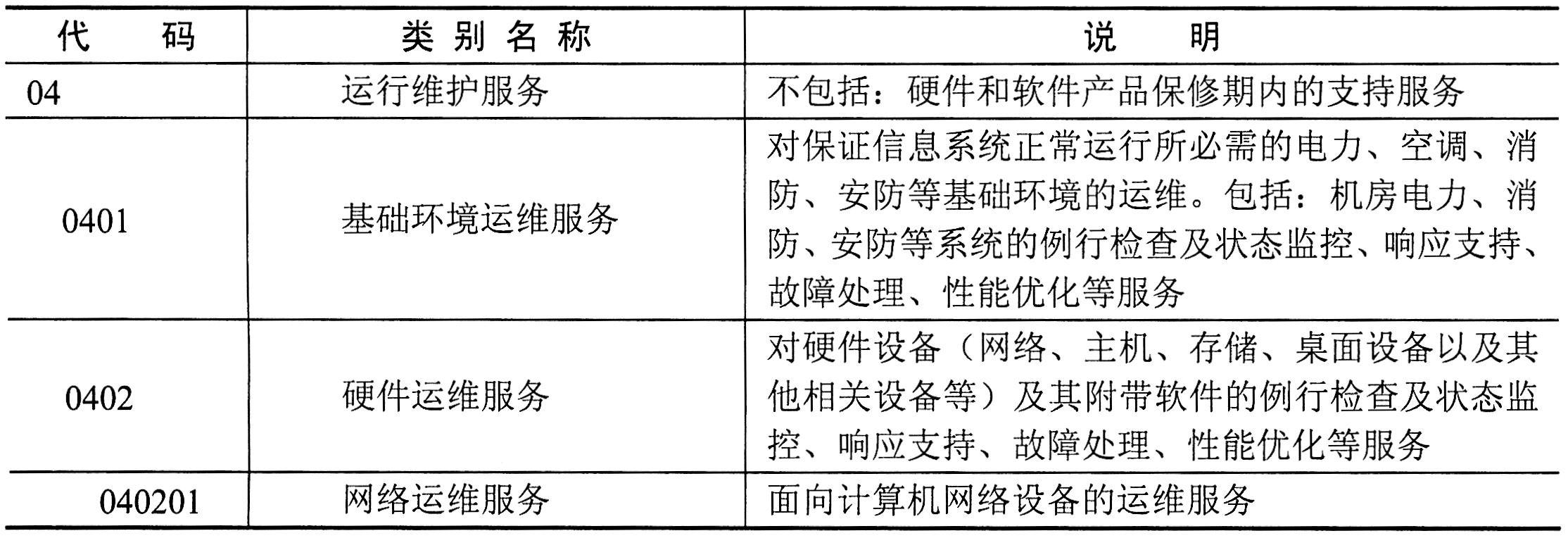
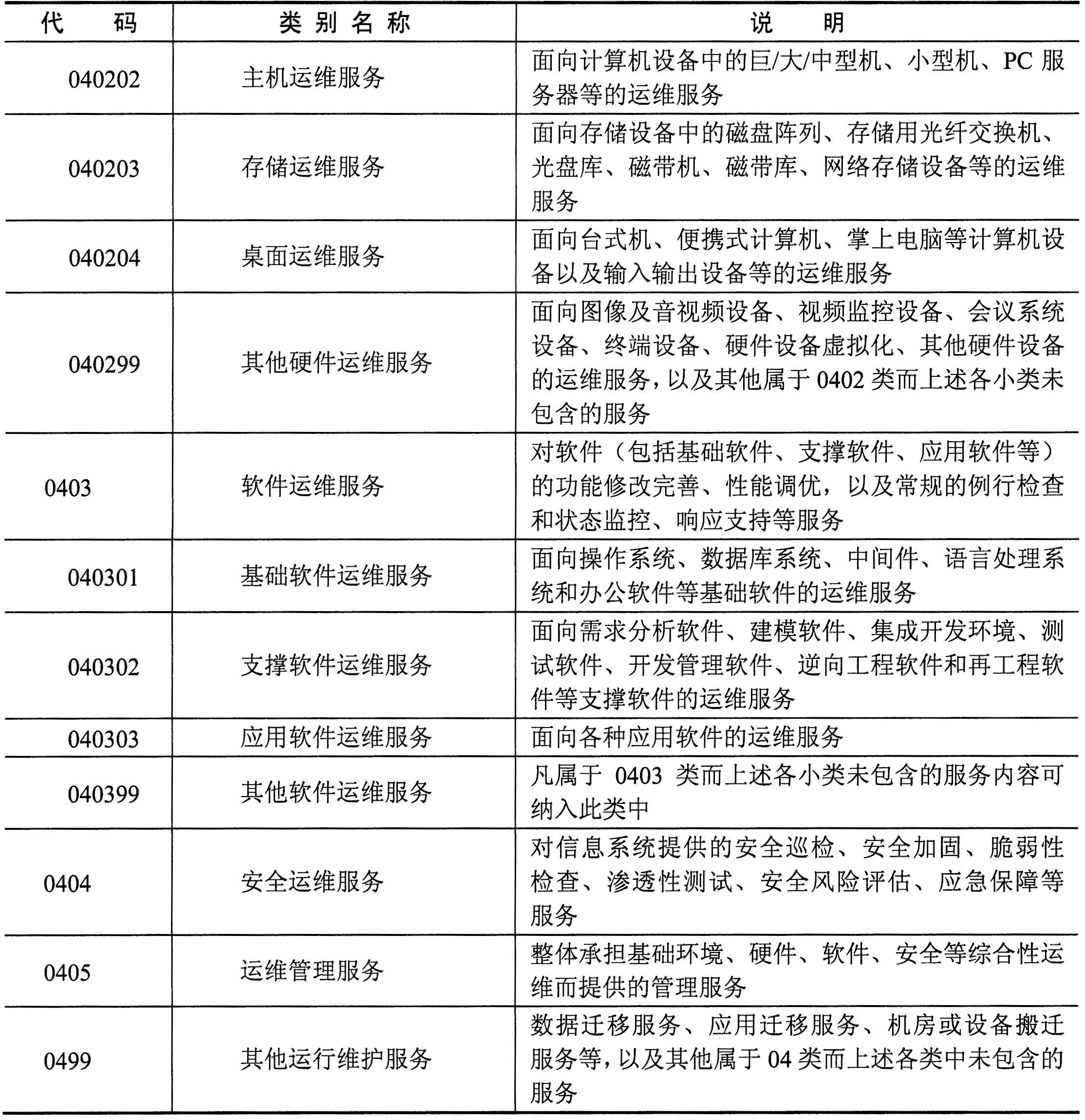
信息系统设施运维的专用工具主要包括在准备阶段的运维部署工具、过程中的运维配置工具和运维监控工具,优化改善过程中的日志分析工具及其他辅助专用工具等,具体如下表所示。
|
|
|
|
|
|
|
|
|
|
当系统环境稳定运行后,可采用运维配置工具辅助管理网络、服务器、应用程序、后台程序及各种服务,帮助运维人员更加方便地完成升级软件包、管理配置文件、系统服务、计划执行任务、添加新的配置、修复错误等重复工作。另一方面,随着IT产业向云计算迈进,配置管理工具除了在提高效率方面发挥作用外,也会成为一种更有效的使用云计算的方式。
|
|
|
|
当前主流的运维自动化配置管理工具大部分为开源软件,主要包括Puppet、Func、Chef、Cfengine及Capistrano等,其中以Puppet、Func和Chef最为常用,如下表所示。
|
|
|
|
|
|
|
|
|
|
信息系统设施运维通常采取基于反应的问题解决方案,但往往效率低下,而设施运维监控工具能够通过对各种设施的监测及数据的采集,及时对影响设施运行性能的事件(包括故障)发送告警,以便采取相应的处理措施,保证设施的正常安全运行。一个相对完善的运维监控工具应能够记录基础设施中运行的所有服务器和机器,能够在小问题变大之前发出警告;能从一个中心地点运行,而减少必须到每台物理设施才能解决问题的需求;能提供有关全系统状态、未解决问题等直观视图。
|
|
|
|
但是,没有任何的监控工具可以监视运维所需的一切内容,因此首先需要根据需求制定明确的监控策略。
|
|
|
|
|
|
为更好、更有效地保障系统上线后的稳定运行,对于信息系统设施中的硬件资源、性能、带宽、端口、进程、服务等都必须有一个可靠和可持续的监测策略和机制,需要明确定义监控的对象、方式,设定告警的优先级、标准等,具体策略包括以下内容。
|
|
|
|
(1)监控对象:在一个规模较大的网络中,监控的对象可能包括服务器、防火墙、交换机、路由器等设备及运行在各对象上的服务,不需要将所有的对象都放到监控系统中,监控策略的设计首先应明确监控对象。
|
|
|
|
(2)故障告警方式:对监控系统而言,一定要有合适的故障告警机制。目前常用的告警机制包括邮件、短信、MSN、Web页面显示等几种手段,这几种手段中,短信告警最佳。
|
|
|
|
(3)告警时效和间隔的选择:由于网络通信等不可控因素,可能存在故障误报的情况,不应将告警发送设置成一次探测不成功就发送。此外,故障告警开始发送以后,在收到确认排除前会持续发送,因此需要合理设置告警发送的间隔。
|
|
|
|
告警时效和间隔的策略参考建议:探测4次失败开始告警,告警间隔10分钟,总共发送8次,然后停止发送,假如第3次没有人去处理,监控工具电话通知,没有回应则取消该对象的监控,并记录该次事件。
|
|
|
|
(4)监控平台地点的选择:对于一个规模较大的网络,为解决南北互连问题一般会采取在多个地点建立数据中心的方法,这时需要对不同地理位置的服务器进行监控,也会遇到访问慢的问题。解决这个问题有几种方式:①选择一个到各个位置访问都顺畅的数据机房;②采取分布式监控平台,各处自己收集监控信息,然后到一处汇总;③各数据中心单独建立监控平台。
|
|
|
|
(5)定义告警优先级策略:对于监控到的事件,通常将访问网页出错、连接不到Socket等故障设置为优先告警。此外,对返回的延时、内容的信息,如访问网页的时间、访问网页取到的内容及其他数据指标等,可自定义告警条件,如对Ping监控的返回延时一般是10~30ms,当延时大于100ms时,表示网络或者服务器可能出现问题,引起网络响应慢,需要立即检查是否有流量过大或者服务器CPU太高等问题;当监控到磁盘空间超过一个阈值时,可能会引起数据库损坏,服务响应变慢等问题,需要告警进行检查和处理。
|
|
|
|
(6)定义告警信息内容标准:当服务器或应用发生故障时告警信息内容非常多,如告警运行业务名称、服务器IP、监控的线路、监控的服务错误级别、出错信息、发生时间等。预先定义告警内容及标准能使收到的告警内容具有规范性及可读性。这一点对于用短信接收告警内容特别有意义,短信内容最多是70个字符,要用70个字符完全明确故障内容比较困难,更需要预先定义内容规范。例如,“视频直播服务器10.0.211.65在2012-10-1813:00电信线路监控到第1次失败”,清晰明了地告知故障信息。
|
|
|
|
(7)通过邮件接收汇总报表:设计固定周期收到网站服务器监控的汇总报表邮件,运维人员只需花很少的时间就能大致了解网站和服务器状态。
|
|
|
|
(8)定义故障告警主次:对于监控同一台服务器的服务,需要定义一个主要监控对象,当主要监控对象出现故障时,只发送主要监控对象的告警,其他次要的监控对象暂停监控和告警。例如,用Ping来做主要监控对象,如果Ping不通出现Timeout,表示服务器已经宕机或者断网,这时只发送服务器Ping告警并持续监控Ping,因为再继续监控和告警其他服务已经没有必要。这样既能大大减少告警消息数量,又可以让监控更加合理、更加有效率。
|
|
|
|
(9)规范本地部署的监控脚本,并归纳总结:对在本地部署的监控脚本要进行统一规范的部署并记录到知识管理系统中以便沉淀及优化。
|
|
|
|
(10)实现对常见性故障业务自我修复功能:实现对常见性故障业务自我修复功能脚本进行统一部署,并对修复后的故障进行检查,一般告警检查频次不多于3次。
|
|
|
|
(11)对监控的业务系统进行分级:如设置类似“一级系统7×24小时告警,二级系统7×12小时告警,三级系统5×8小时告警”这样的业务系统分级标准。
|
|
|
|
|
|
当前主流的运维监控工具主要包括Nagios、Zabbix、Cacti、Gandia、Hyperic等,其中以Nagios、Zabbix和Cacti最为常用,如下表所示。
|
|
|
|
|
|
主要运维监控工具Nagios、Zabbix和Cacti
|
|
|
|
|
|
日志在信息系统中是一个非常广泛的概念,任何程序都有可能输出日志,如操作系统内核、各种应用服务器等。日志分析工具是运维人员在响应支持运维中进行问题定位的有效辅助工具,也可以作为优化改善中预防性改进的有效辅助,越来越为运维人员所重视。
|
|
|
|
当前主流的运维日志分析工具包括Splunk、Loggly、Airbrake、Graylog等,其中以Splunk和Loggly最为常用,如下表所示。
|
|
|
|
|
|
|
|
|
|
除了以上列举的运维专用工具之外,其他设施运维专用工外还包括信息资源管理工具(如glpi)、交互式拓扑绘制工具(如Network Notepad)、性能测试工具(如存储子系统读/写性能测试工具Iometer、网络性能测试工具Netperf)等。
|
|
|
|
(1)信息资源管理工具glpi。它是Linux环境下的资源管理器工具,通过glpi可以建立设施资产清单(计算机、软件、打印机等)数据库,其功能可以简化管理员的日常工作,如带有邮件提醒功能的工作跟踪系统等。
|
|
|
|
(2)交互式拓扑绘制工具Network Notepad。可以通过第三方工具自动发现网络拓扑,例如,使用CDP工具可以支持自动发现网络中所有思科的设备。在使用Network Notepad绘制网络拓扑图之前,应同时安装它的一些图形库,这些图形库中包含许多基本的网络设备图形,直接以拖曳的方式进行绘制即可。
|
|
|
|
(4)存储子系统读/写性能测试工具Iometer。Iometer是Windows系统下对存储子系统的读/写性能进行测试的软件,可以显示磁盘系统的最大I/O能力、磁盘系统的最大吞吐量、CPU使用率、错误信息等。用户可以通过设置不同的测试参数,如存取类型(如sequential、random)、读/写块大小(如64KB、256KB)、队列深度等,来模拟实际应用的读/写环境进行测试。
|
|
|
|
(5)网络性能测试工具Netperf。Netperf可以测试服务器网络性能,主要针对基于TCP或UDP的传输。Netperf根据应用的不同,可以进行不同模式的网络性能测试,即批量数据传输(bulkdata transfer)模式和请求/应答(request/response)模式。Netperf测试结果所反映的是一个系统能够以多快的速度向另外一个系统发送数据,以及另外一个系统能够以多快的速度接收数据。
|
|
|
|
Netperf工具以Client/Server方式工作。Server端是Netserver,用来侦听来自Client端的连接,Client端是Netperf,用来向Server端发起网络测试。在Client与Server之间,首先建立一个控制连接,传递有关测试配置的信息,以及测试的结果;在控制连接建立并传递了测试配置信息以后,Client与Server之间会再建立一个测试连接,用于来回传递特殊的流量模式,以测试网络的性能。
|
|
|
|
(6)端口扫描器Unicornscan。通过尝试连接用户系统分布式TCP/IP堆栈获得信息和关联关系的端口扫描器,该工具试图为研究人员提供一种可以刺激TCP/IP设备和网络并度量反馈的超级接口,主要功能包括带有所有TCP变种标记的异步无状态TCP扫描、异步无状态TCP标志捕获,通过分析反馈信息获取主动/被动远程操作系统、应用程序、组件信息等。
|
|
|