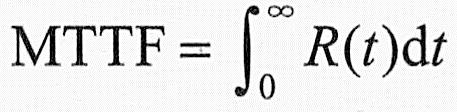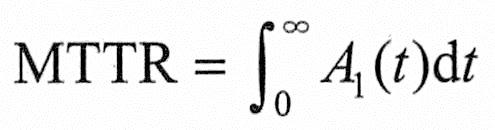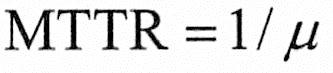|
|
|
在性能评估方面,主要考系统可靠性、容错系统、指令周期、响应时间与吞吐量等。
|
|
|
|
计算机系统性能指标以系统响应速度和作业吞吐量为代表。系统响应时间是指用户发出完整请求到系统完成任务给出响应的时间间隔。作业吞吐量是指单位时间内系统完成的任务量。若一个给定系统持续地收到用户提交的任务请求,则系统的响应时间将对作业吞吐量造成一定的影响。每个任务的响应时间越短,则系统的空闲资源越多,整个系统在单位时间内完成的任务量将越大;反之,响应时间越长,则系统的空闲资源越少,整个系统在单位时间内完成的任务量将越少。
|
|
|
|
|
|
与可靠性相关的概念主要有平均无故障时间、平均故障修复时间和平均故障间隔时间等。
|
|
|
|
|
|
可靠度为R(t)的系统的平均无故障时间(MTTF)定义为从t=0时到故障发生时系统持续运行时间的期望值,计算公式如下:
|
|
|
|
|
|
如果R(t)=e-λt,则MTTF=1/λ。其中λ为失效率,是指器件或系统在单位时间内发生失效的预期次数,在此处假设为常数。
|
|
|
|
例如,假设同一型号的1000台计算机在规定的条件下工作1000小时,其中有10台出现故障,那么这种计算机千小时的可靠度R为(1000-10)/1000=0.99,失效率为10/(10×1000)=1×10-5。因为平均无故障时间与失效率的关系为MTTF=1/λ,所以MTTF=105小时。
|
|
|
|
|
|
可用度为A(t)的系统平均故障修复时间(MTTR)可以用类似于求MTTF的方法求得。设A1(t)是在风险函数Z(t)=0且系统的初始状态为1状态的条件下A(t)的特殊情况,则:
|
|
|
|
|
|
此处假设修复率μ(t)=μ(常数),修复率是指单位时间内可修复系统的平均次数,则:
|
|
|
|
|
|
|
|
平均故障间隔时间(MTBF)常常与MTTF发生混淆。因为两次故障(失败)之间必然有修复行为,所以MTBF中应包含MTTR。对于可靠度服从指数分布的系统,从任一时刻t0到达故障的期望时间都是相等的,因此有:
|
|
|
|
|
|
在实际应用中,一般MTTR很小,所以通常认为MTBF≈MTTF。
|
|
|
|
|
|
对于系统的可靠性计算,需要掌握串联系统和并联系统的可靠性计算的方法。
|
|
|
|
|
|
假设一个系统由n个子系统组成,当且仅当所有的子系统都能正常工作时,系统才能正常工作,这种系统称为串联系统,如下图所示。
|
|
|
|
|
|
|
|
设系统中各个子系统的可靠性分别用R1,R2,…,Rn表示,则系统的可靠性为:
|
|
|
|
|
|
如果系统的各个子系统的失效率分别用λ1,λ2,…,λn来表示,则系统的失效率为:
|
|
|
|
|
|
|
|
假如一个系统由n个子系统组成,只要有一个子系统能够正常工作,系统就能正常工作,如下图所示。
|
|
|
|
|
|
|
|
系统中各个子系统的可靠性分别用R1,R2,…,Rn表示,则系统的可靠性为:
|
|
|
|
R=1-(1-R1)×(1-R2)×…×(1-Rn)
|
|
|
|
|
|
|
|
在并联系统中只有一个子系统是真正需要的,其余n-1个子系统称为冗余子系统,随着冗余子系统数量的增加,系统的平均无故障时间也增加了。
|
|
|
|
|
|
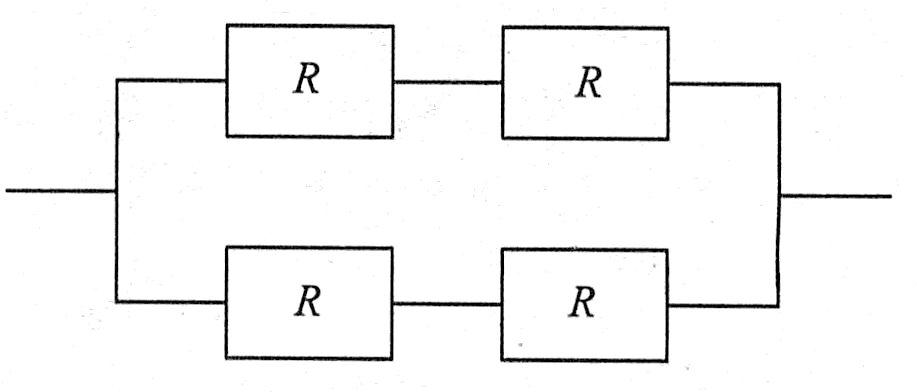
所谓混联系统,就是指由串联和并联两种结构混合组成的系统。例如,下图是一个典型的双重串并联系统的结构,可以简单地把它看成是两个部件的并联,而这并联的两个部件又分别由两个部件串联而成。
|
|
|
|
|
|
|
|
若构成系统的每个部件的可靠度为0.9,则两个部件串联后的可靠度为:
|
|
|
|
|
|
然后再计算两个可靠度为0.81的部件并联后的可靠度:
|
|
|
|
R=1-(1-0.81)×(1-0.81)=1-0.0361=0.9639
|
|
|
|
假设每个部件的失效率为0.1,则两个部件串联后的失效率为:
|
|
|
|
|
|
然后再计算两个失效率为0.2的部件并联后的失效率:
|
|
|
|
1/((1/0.2)×1+(1/0.2)×(1/2))=1/(5+2.5)=0.1333
|
|
|
|
该计算机系统的总失效率为0.1333,因为失效率的倒数即为平均无故障时间,从而可得出MTTF为7.5小时。
|
|
|
|
|
|
提高计算机可靠性的技术可以分为避错技术和容错技术。避错是指预防和避免系统在运行中出错。容错是指系统在其某一组件故障存在的情况下不失效,仍然能够正常工作的特性。简单地说,容错就是当计算机由于种种原因在系统中出现了数据、文件损坏或丢失时,系统能够自动将这些损坏或丢失的文件和数据恢复到发生事故以前的状态,使系统能够连续正常运行。容错功能一般通过冗余组件设计来实现。计算机系统的容错性通常可以从系统的可靠性、可用性和可测性等方面来衡量。
|
|
|
|
冗余技术是计算机容错技术的基础,一般可分为下列几种类型。
|
|
|
|
(1)硬件冗余。以检测或屏蔽故障为目的而增加一定硬件设备的方法。
|
|
|
|
(2)软件冗余。为了检测或屏蔽软件中的差错而增加一些在正常运行时所不需要的软件。
|
|
|
|
(3)信息冗余。除实现正常功能所需要的信息外,再添加一些信息,以保证运行结果正确性的方法。纠错码就是信息冗余的例子。
|
|
|
|
(4)时间冗余。使用附加一定时间的方法完成系统功能。这些附加的时间主要用在故障检测、故障屏蔽等方面。
|
|
|
|
在20世纪60年代,主要利用双处理机或双机的方法来达到容错的目的。例如把关键的元件(处理机、存储器等)或整个计算机设置两套:一套在系统运行时使用,另一套用做备份。根据系统的工作情况又可分为热备份和冷备份两种。
|
|
|
|
(1)热备份(双重系统):两套系统同时同步运行,当联机子系统检测到错误时,退出服务进行检修,而由热备份子系统接替工作。
|
|
|
|
(2)冷备份(双工系统):处于冷备份的子系统平时停机,或者运行与联机系统无关的运算,当联机子系统产生故障时,人工或自动进行切换,使冷备份系统成为联机系统。在冷备份时,不能保证从程序端点处精确地连续工作,因为备份机不能取得原来机器上当前运行的全部数据。
|
|
|
|
20世纪70年代中期出现了软件和硬件结构的容错方法。该方法在操作系统的层次上支持联机维修,即故障部分退出后运行、进行维修并重新投入运行都不影响正在运行的应用程序。该结构的特点是系统内包括双处理器、双存储器、双输入输出控制器、不间断工作的电源,以及与之适应的操作系统等。因此上述硬件的任何一部分发生故障都不会影响系统的继续工作。系统容错是在操作系统控制下进行的,在每个处理机上都保持了反映所有系统资源状态的表格,以及本机和其他处理机的工作进程。
|
|
|
|
|
|
在这个考点中,主要需掌握几个基本概念:时钟频率、时钟周期、机器周期、指令周期和指令执行速度。
|
|
|
|
时钟频率(时钟脉冲,主频)是计算机的基本工作脉冲,它控制着计算机的工作节奏。因此,计算机的时钟频率在一定程度上反映了机器速度。显然,对同一种机型的计算机而言,时钟频率越高,计算机的工作速度就越快。但是,由于不同的计算机硬件电路和器件不完全相同,因此其所需要的时钟频率范围也不一定相同。相同频率、不同体系结构的机器,其速度和性能可能会相差很多倍。
|
|
|
|
时钟周期也称为振荡周期,定义为时钟频率的倒数。时钟周期是计算机中最基本、最小的时间单位。在一个时钟周期内,CPU仅完成一个最基本的动作。
|
|
|
|
在计算机中,为了便于管理,常把一条指令的执行过程划分为若干个阶段,每一阶段完成一项工作。例如,取指令、存储器读和存储器写等,每一项工作被称为一个基本操作。完成一个基本操作所需要的时间称为机器周期。一般情况下,一个机器周期由若干个时钟周期组成。
|
|
|
|
指令周期是执行一条指令所需要的时间,一般由若干个机器周期组成。指令不同,所需的机器周期数也不同。对于一些简单的单字节指令而言,在取指令周期中,指令取出到指令寄存器后,立即译码执行,不再需要其他的机器周期。对于一些比较复杂的指令,例如转移指令和乘法指令,则需要两个或两个以上的机器周期。
|
|
|
|
为了帮助读者搞清楚这些概念之间的关系,下面通过一个例子来进行说明。
|
|
|
|
假设计算机A和计算机B采用同样的CPU,计算机A的主频为20MHz,计算机B的主频为60MHz。如果两个时钟周期组成一个机器周期,平均三个机器周期可完成一条指令,则有以下结论。
|
|
|
|
(1)计算机A的时钟周期为1/(20M)=50ns(1s=109ns)。因为“两个时钟周期组成一个机器周期”,所以一个机器周期为2×50ns=100ns。又因为“平均三个机器周期可完成一条指令”,所以平均指令周期为3×100ns=300ns。也就是说,指令平均执行速度为1/(300ns)≈3.33MIPS,其中MIPS的含义为“百万条指令/每秒”。
|
|
|
|
(2)因为计算机B的主频为60MHz,是计算机A主频的60/20=3倍,所以计算机B的平均指令执行速度应该比计算机A快两倍,即计算机B的指令平均执行速度为3.33×3≈10MIPS。
|
|
|