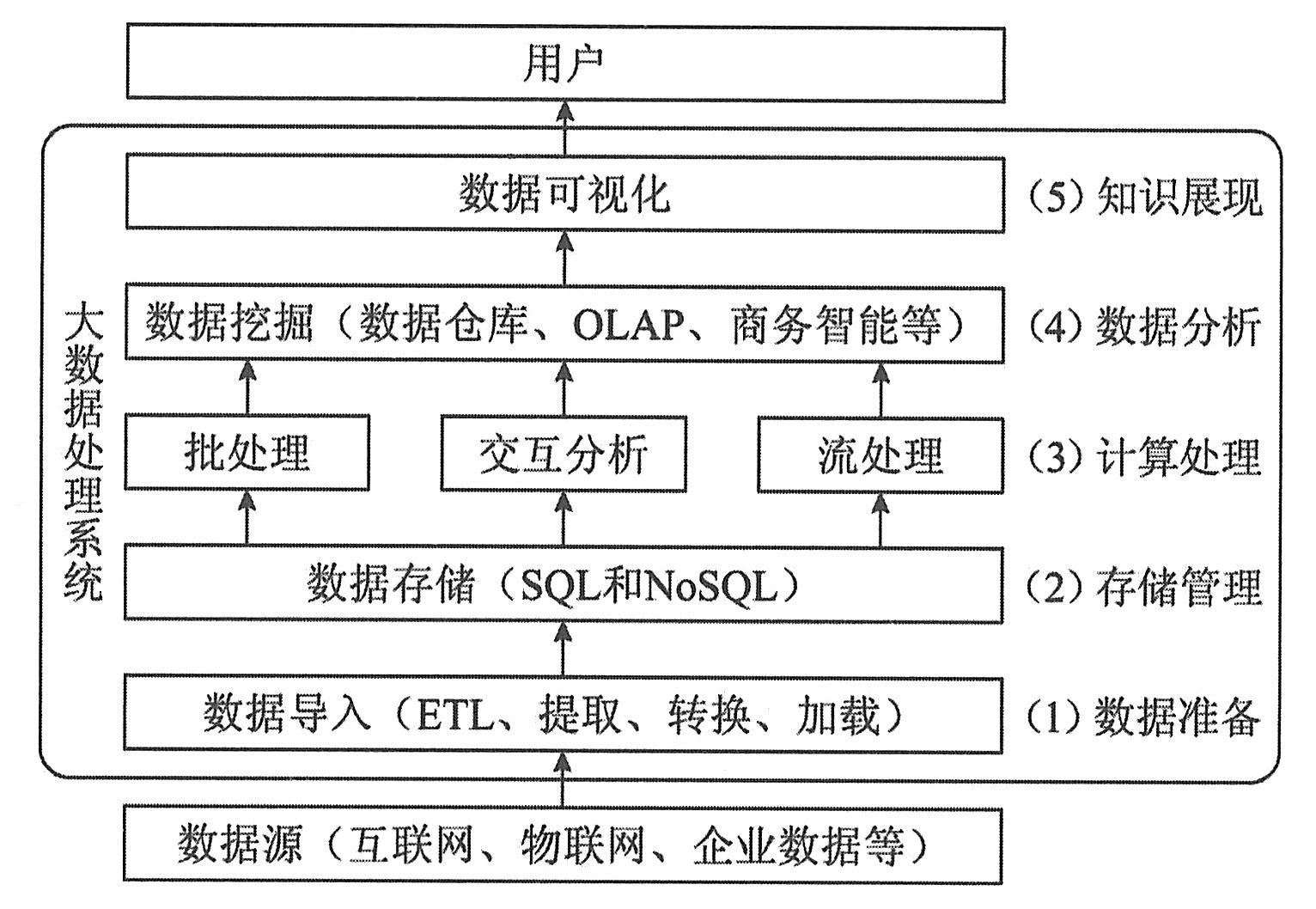
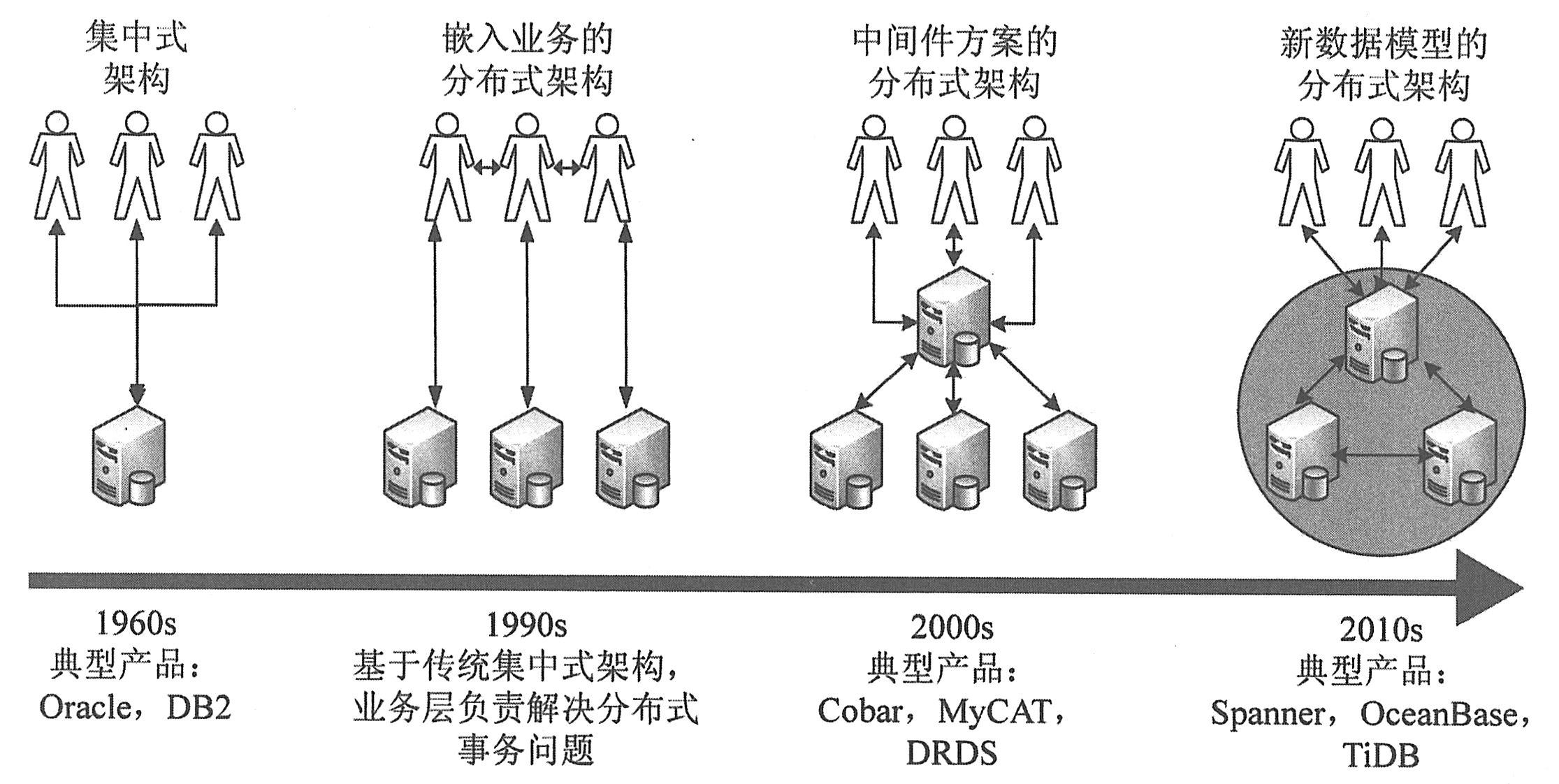
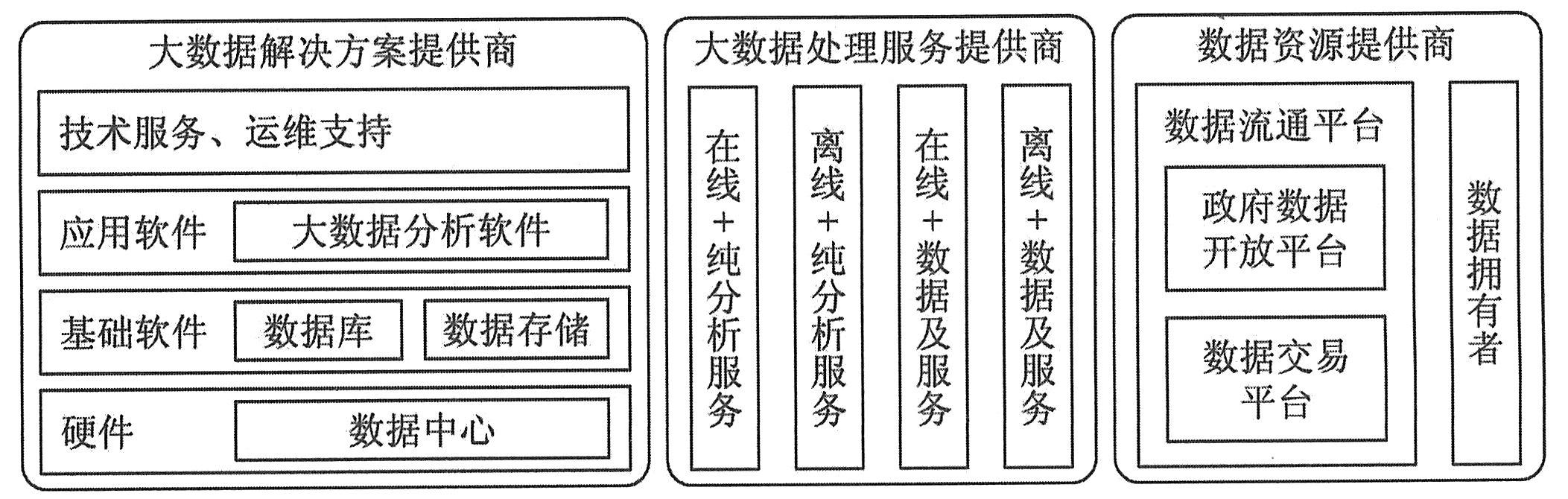
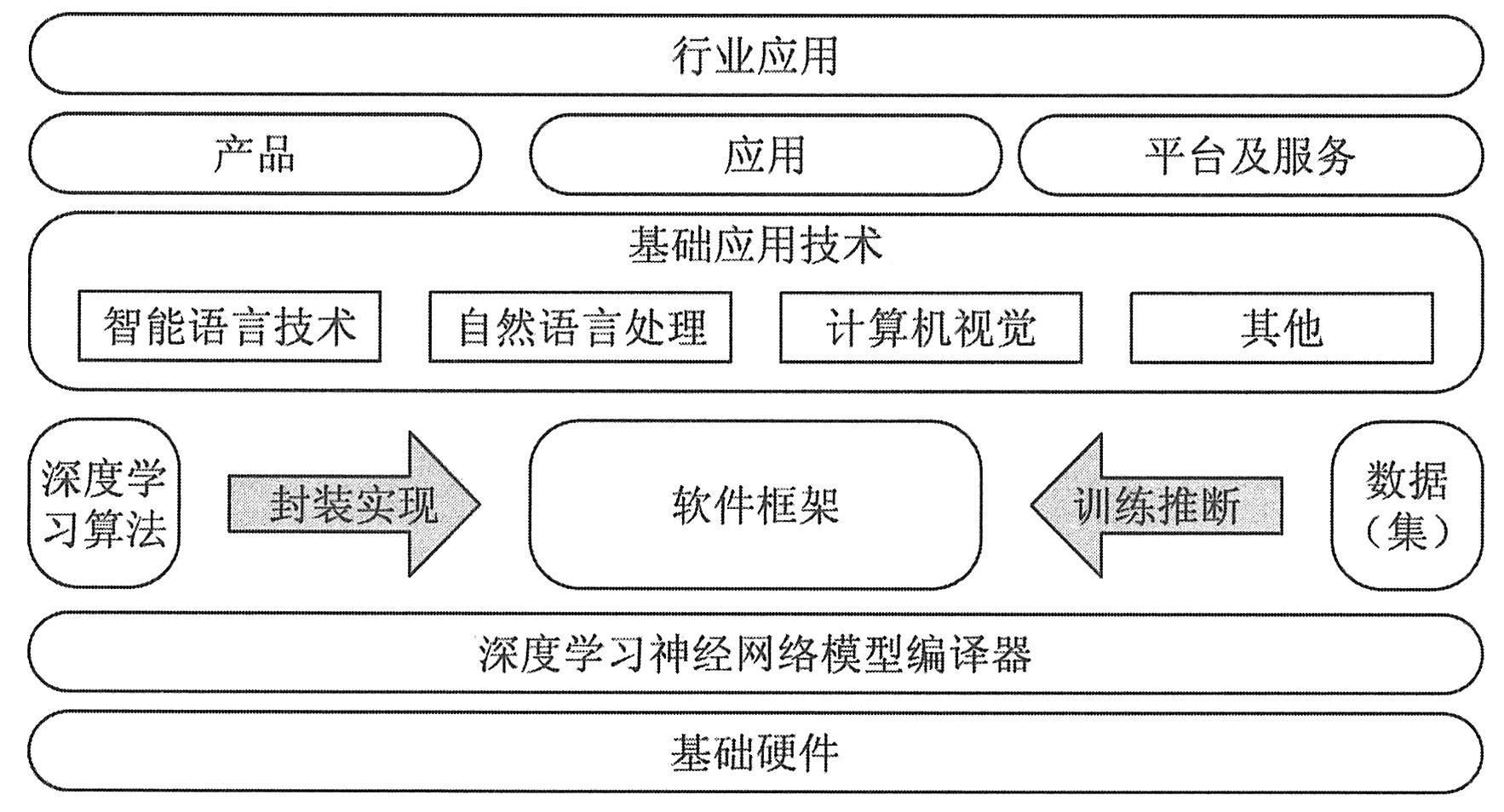
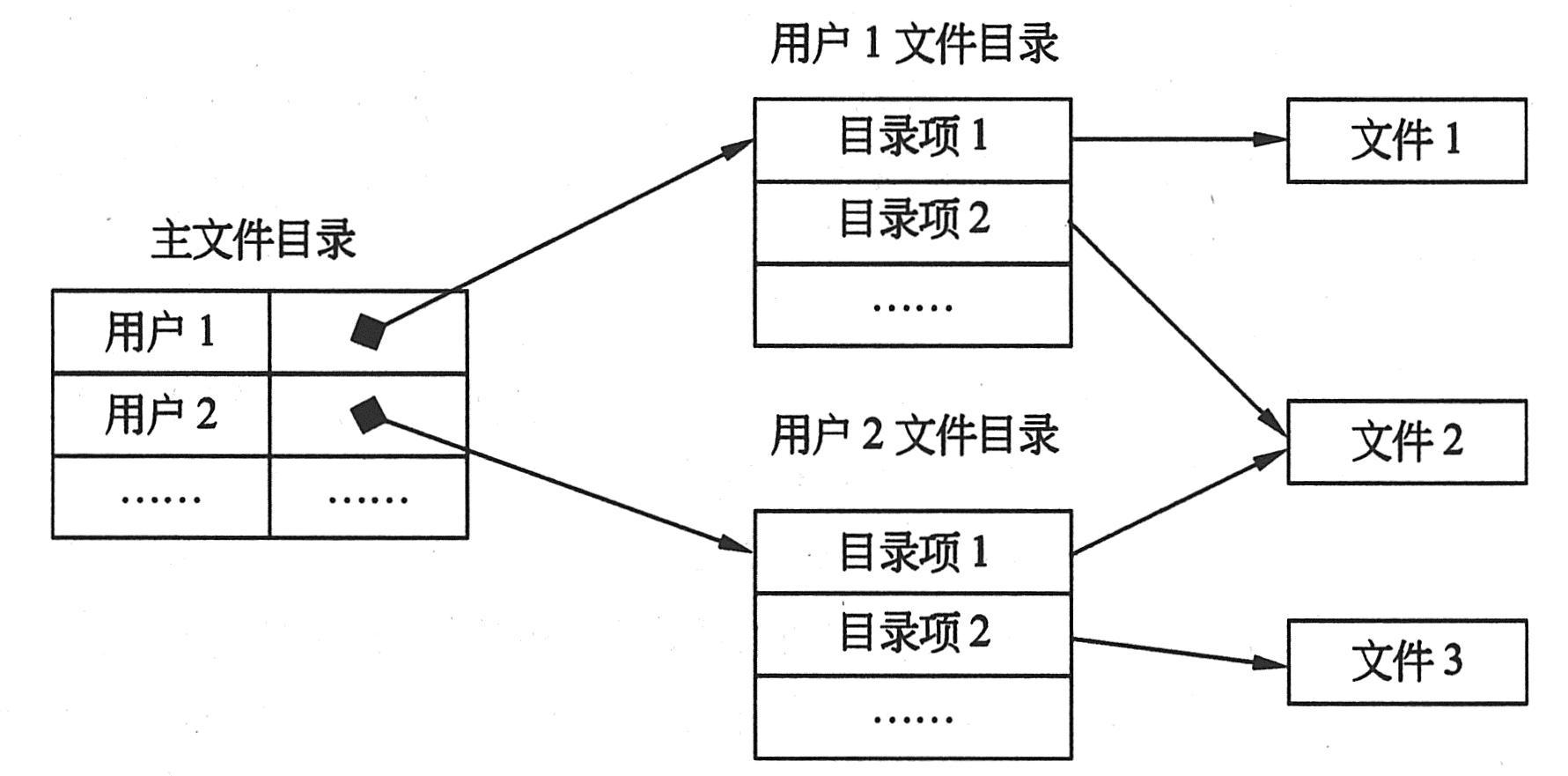
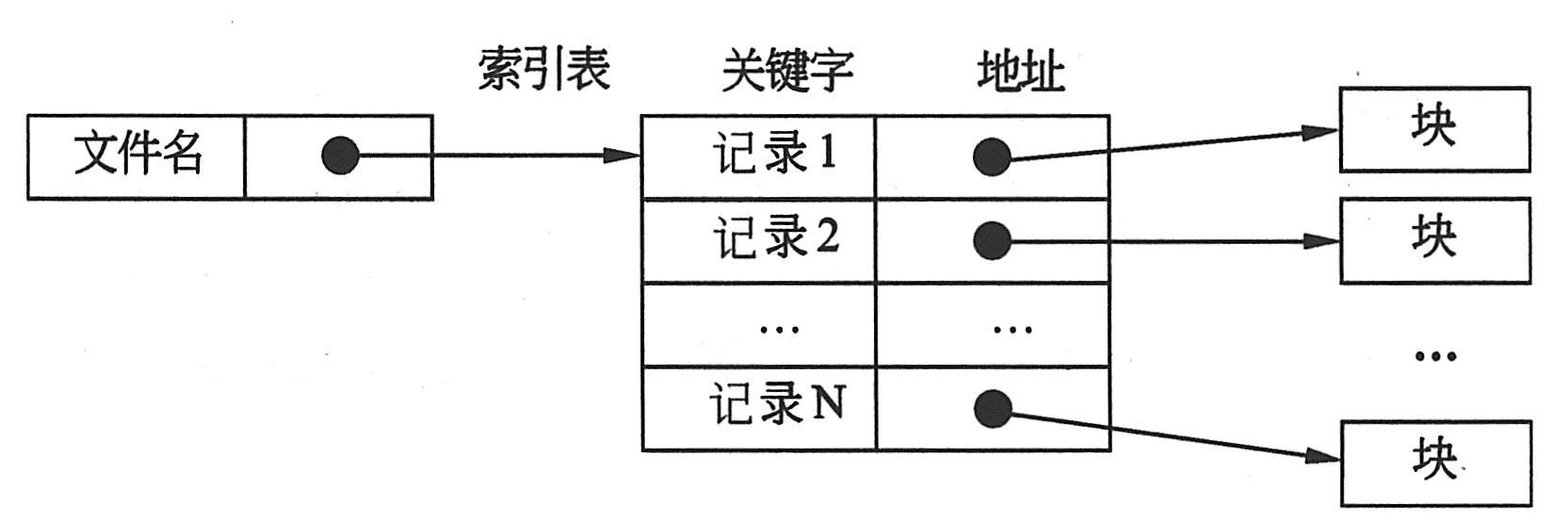
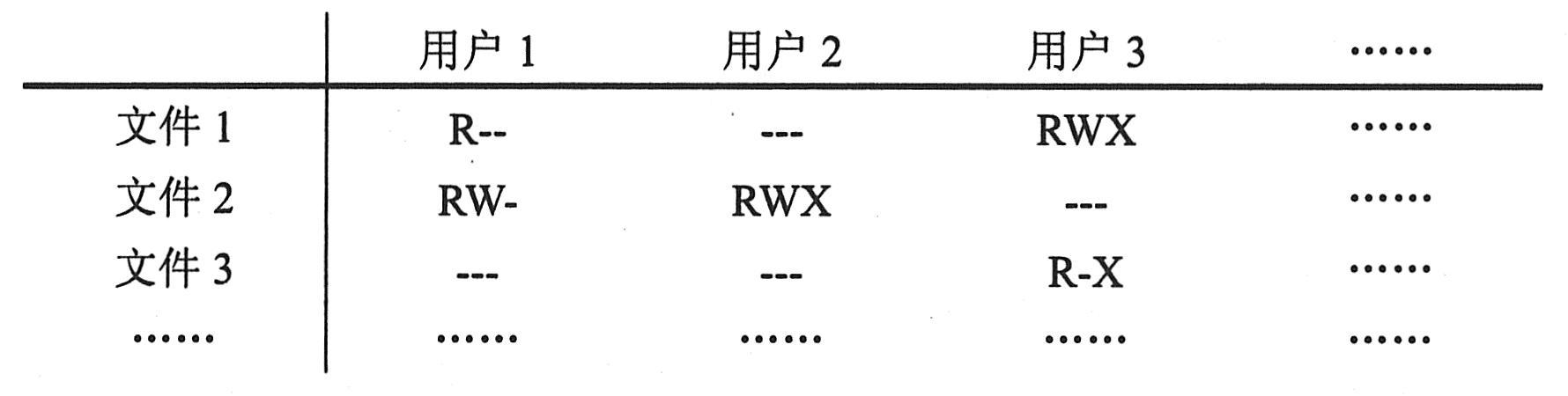
|
|
|
伴随着系统集成行业的高速发展,系统集成行业面临着越来越激烈的竞争,表现最为突出的现状之一就是系统集成公司频繁地参与各个系统集成项目的招投标活动。在现实工作中,系统集成项目的招标活动几乎完全由甲方主导,大多数情形下乙方只能被动地去满足甲方的招投标要求。造成乙方在投标活动中处于被动地位的主要原因固然是现在系统集成行业是典型的“买方市场”,但不可否认的事实是乙方对招投标法规理解不深入、不全面也是一个重要的原因。为了更好地参与市场竞争,学习和了解招投标法规对于系统集成行业的从业人员有着重要的指导意义。下面列举了《招投标法》六章内容的重点条款,考生应重点熟悉和理解。
|
|
|
|
|
|
第五条设区的市级以上地方人民政府可以根据实际需要,建立统一规范的招标投标交易场所,为招标投标活动提供服务。招标投标交易场所不得与行政监督部门存在隶属关系,不得以营利为目的。
|
|
|
|
|
|
第六条禁止国家工作人员以任何方式非法干涉招标投标活动。
|
|
|
|
|
|
第七条按照国家有关规定需要履行项目审批、核准手续的依法必须进行招标的项目,其招标范围、招标方式、招标组织形式应当报项目审批、核准部门审批、核准。项目审批、核准部门应当及时将审批、核准确定的招标范围、招标方式、招标组织形式通报有关行政监督部门。
|
|
|
|
第八条国有资金占控股或者主导地位的依法必须进行招标的项目,应当公开招标;但有下列情形之一的,可以邀请招标:
|
|
|
|
(一)技术复杂、有特殊要求或者受自然环境限制,只有少量潜在投标人可供选择;
|
|
|
|
(二)采用公开招标方式的费用占项目合同金额的比例过大。
|
|
|
|
有前款第二项所列情形,属于本条例第七条规定的项目,由项目审批、核准部门在审批、核准项目时作出认定;其他项目由招标人申请有关行政监督部门作出认定。
|
|
|
|
第九条除招标投标法第六十六条规定的可以不进行招标的特殊情况外,有下列情形之一的,可以不进行招标:
|
|
|
|
|
|
|
|
(三)已通过招标方式选定的特许经营项目投资人依法能够自行建设、生产或者提供;
|
|
|
|
(四)需要向原中标人采购工程、货物或者服务,否则将影响施工或者功能配套要求;
|
|
|
|
|
|
招标人为适用前款规定弄虚作假的,属于招标投标法第四条规定的规避招标。
|
|
|
|
第十五条公开招标的项目,应当依照招标投标法和本条例的规定发布招标公告、编制招标文件。
|
|
|
|
招标人采用资格预审办法对潜在投标人进行资格审查的,应当发布资格预审公告、编制资格预审文件。
|
|
|
|
依法必须进行招标的项目的资格预审公告和招标公告,应当在国务院发展改革部门依法指定的媒介发布。在不同媒介发布的同一招标项目的资格预审公告或者招标公告的内容应当一致。指定媒介发布依法必须进行招标的项目的境内资格预审公告、招标公告,不得收取费用。
|
|
|
|
编制依法必须进行招标的项目的资格预审文件和招标文件,应当使用国务院发展改革部门会同有关行政监督部门制定的标准文本。
|
|
|
|
第十六条招标人应当按照资格预审公告、招标公告或者投标邀请书规定的时间、地点发售资格预审文件或者招标文件。资格预审文件或者招标文件的发售期不得少于5日。
|
|
|
|
招标人发售资格预审文件、招标文件收取的费用应当限于补偿印刷、邮寄的成本支出,不得以营利为目的。
|
|
|
|
第十七条招标人应当合理确定提交资格预审申请文件的时间。依法必须进行招标的项目提交资格预审申请文件的时间,自资格预审文件停止发售之日起不得少于5日。
|
|
|
|
第十八条资格预审应当按照资格预审文件载明的标准和方法进行。
|
|
|
|
国有资金占控股或者主导地位的依法必须进行招标的项目,招标人应当组建资格审查委员会审查资格预审申请文件。资格审查委员会及其成员应当遵守招标投标法和本条例有关评标委员会及其成员的规定。
|
|
|
|
第十九条资格预审结束后,招标人应当及时向资格预审申请人发出资格预审结果通知书。未通过资格预审的申请人不具有投标资格。
|
|
|
|
|
|
第二十条招标人采用资格后审办法对投标人进行资格审查的,应当在开标后由评标委员会按照招标文件规定的标准和方法对投标人的资格进行审查。
|
|
|
|
第二十一条招标人可以对已发出的资格预审文件或者招标文件进行必要的澄清或者修改。澄清或者修改的内容可能影响资格预审申请文件或者投标文件编制的,招标人应当在提交资格预审申请文件截止时间至少3日前,或者投标截止时间至少15日前,以书面形式通知所有获取资格预审文件或者招标文件的潜在投标人;不足3日或者15日的,招标人应当顺延提交资格预审申请文件或者投标文件的截止时间。
|
|
|
|
第二十二条潜在投标人或者其他利害关系人对资格预审文件有异议的,应当在提交资格预审申请文件截止时间2日前提出;对招标文件有异议的,应当在投标截止时间1日前提出。招标人应当自收到异议之日起3日内作出答复;作出答复前,应当暂停招标投标活动。
|
|
|
|
第二十三条招标人编制的资格预审文件、招标文件的内容违反法律、行政法规的强制性规定,违反公开、公平、公正和诚实信用原则,影响资格预审结果或者潜在投标人投标的,依法必须进行招标的项目的招标人应当在修改资格预审文件或者招标文件后重新招标。
|
|
|
|
第二十四条招标人对招标项目划分标段的,应当遵守招标投标法的有关规定,不得利用划分标段限制或者排斥潜在投标人。依法必须进行招标的项目的招标人不得利用划分标段规避招标。
|
|
|
|
第二十五条招标人应当在招标文件中载明投标有效期。投标有效期从提交投标文件的截止之日起算。
|
|
|
|
第二十六条招标人在招标文件中要求投标人提交投标保证金的,投标保证金不得超过招标项目估算价的2%。投标保证金有效期应当与投标有效期一致。
|
|
|
|
依法必须进行招标的项目的境内投标单位,以现金或者支票形式提交的投标保证金应当从其基本账户转出。
|
|
|
|
|
|
第二十七条招标人可以自行决定是否编制标底。一个招标项目只能有一个标底。标底必须保密。
|
|
|
|
接受委托编制标底的中介机构不得参加受托编制标底项目的投标,也不得为该项目的投标人编制投标文件或者提供咨询。
|
|
|
|
招标人设有最高投标限价的,应当在招标文件中明确最高投标限价或者最高投标限价的计算方法。招标人不得规定最低投标限价。
|
|
|
|
第二十八条招标人不得组织单个或者部分潜在投标人踏勘项目现场。
|
|
|
|
第二十九条招标人可以依法对工程以及与工程建设有关的货物、服务全部或者部分实行总承包招标。以暂估价形式包括在总承包范围内的工程、货物、服务属于依法必须进行招标的项目范围且达到国家规定规模标准的,应当依法进行招标。
|
|
|
|
前款所称暂估价,是指总承包招标时不能确定价格而由招标人在招标文件中暂时估定的工程、货物、服务的金额。
|
|
|
|
第三十条对技术复杂或者无法精确拟定技术规格的项目,招标人可以分两阶段进行招标。
|
|
|
|
第一阶段,投标人按照招标公告或者投标邀请书的要求提交不带报价的技术建议,招标人根据投标人提交的技术建议确定技术标准和要求,编制招标文件。
|
|
|
|
第二阶段,招标人向在第一阶段提交技术建议的投标人提供招标文件,投标人按照招标文件的要求提交包括最终技术方案和投标报价的投标文件。
|
|
|
|
招标人要求投标人提交投标保证金的,应当在第二阶段提出。
|
|
|
|
第三十一条招标人终止招标的,应当及时发布公告,或者以书面形式通知被邀请的或者已经获取资格预审文件、招标文件的潜在投标人。已经发售资格预审文件、招标文件或者已经收取投标保证金的,招标人应当及时退还所收取的资格预审文件、招标文件的费用,以及所收取的投标保证金及银行同期存款利息。
|
|
|
|
第三十二条招标人不得以不合理的条件限制、排斥潜在投标人或者投标人。
|
|
|
|
招标人有下列行为之一的,属于以不合理条件限制、排斥潜在投标人或者投标人:
|
|
|
|
(一)就同一招标项目向潜在投标人或者投标人提供有差别的项目信息;
|
|
|
|
(二)设定的资格、技术、商务条件与招标项目的具体特点和实际需要不相适应或者与合同履行无关;
|
|
|
|
(三)依法必须进行招标的项目以特定行政区域或者特定行业的业绩、奖项作为加分条件或者中标条件;
|
|
|
|
(四)对潜在投标人或者投标人采取不同的资格审查或者评标标准;
|
|
|
|
(五)限定或者指定特定的专利、商标、品牌、原产地或者供应商;
|
|
|
|
(六)依法必须进行招标的项目非法限定潜在投标人或者投标人的所有制形式或者组织形式;
|
|
|
|
(七)以其他不合理条件限制、排斥潜在投标人或者投标人。
|
|
|
|
|
|
第三十四条与招标人存在利害关系可能影响招标公正性的法人、其他组织或者个人,不得参加投标。
|
|
|
|
单位负责人为同一人或者存在控股、管理关系的不同单位,不得参加同一标段投标或者未划分标段的同一招标项目投标。
|
|
|
|
|
|
第三十五条投标人撤回已提交的投标文件,应当在投标截止时间前书面通知招标人。招标人已收取投标保证金的,应当自收到投标人书面撤回通知之日起5日内退还。
|
|
|
|
投标截止后投标人撤销投标文件的,招标人可以不退还投标保证金。
|
|
|
|
第三十六条未通过资格预审的申请人提交的投标文件,以及逾期送达或者不按照招标文件要求密封的投标文件,招标人应当拒收。
|
|
|
|
招标人应当如实记载投标文件的送达时间和密封情况,并存档备查。
|
|
|
|
第三十七条招标人应当在资格预审公告、招标公告或者投标邀请书中载明是否接受联合体投标。
|
|
|
|
招标人接受联合体投标并进行资格预审的,联合体应当在提交资格预审申请文件前组成。资格预审后联合体增减、更换成员的,其投标无效。
|
|
|
|
联合体各方在同一招标项目中以自己名义单独投标或者参加其他联合体投标的,相关投标均无效。
|
|
|
|
第三十八条投标人发生合并、分立、破产等重大变化的,应当及时书面告知招标人。投标人不再具备资格预审文件、招标文件规定的资格条件或者其投标影响招标公正性的,其投标无效。
|
|
|
|
|
|
|
|
(一)投标人之间协商投标报价等投标文件的实质性内容;
|
|
|
|
|
|
|
|
(四)属于同一集团、协会、商会等组织成员的投标人按照该组织要求协同投标;
|
|
|
|
(五)投标人之间为谋取中标或者排斥特定投标人而采取的其他联合行动。
|
|
|
|
第四十条有下列情形之一的,视为投标人相互串通投标:
|
|
|
|
(一)不同投标人的投标文件由同一单位或者个人编制;
|
|
|
|
(二)不同投标人委托同一单位或者个人办理投标事宜;
|
|
|
|
(三)不同投标人的投标文件载明的项目管理成员为同一人;
|
|
|
|
(四)不同投标人的投标文件异常一致或者投标报价呈规律性差异;
|
|
|
|
|
|
(六)不同投标人的投标保证金从同一单位或者个人的账户转出。
|
|
|
|
|
|
|
|
(一)招标人在开标前开启投标文件并将有关信息泄露给其他投标人;
|
|
|
|
(二)招标人直接或者间接向投标人泄露标底、评标委员会成员等信息;
|
|
|
|
(三)招标人明示或者暗示投标人压低或者抬高投标报价;
|
|
|
|
|
|
(五)招标人明示或者暗示投标人为特定投标人中标提供方便;
|
|
|
|
(六)招标人与投标人为谋求特定投标人中标而采取的其他串通行为。
|
|
|
|
第四十二条使用通过受让或者租借等方式获取的资格、资质证书投标的,属于招标投标法第三十三条规定的以他人名义投标。
|
|
|
|
投标人有下列情形之一的,属于招标投标法第三十三条规定的以其他方式弄虚作假的行为:
|
|
|
|
|
|
|
|
(三)提供虚假的项目负责人或者主要技术人员简历、劳动关系证明;
|
|
|
|
|
|
|
|
|
|
第四十四条招标人应当按照招标文件规定的时间、地点开标。
|
|
|
|
|
|
投标人对开标有异议的,应当在开标现场提出,招标人应当当场作出答复,并制作记录。
|
|
|
|
第四十六条除招标投标法第三十七条第三款规定的特殊招标项目外,依法必须进行招标的项目,其评标委员会的专家成员应当从评标专家库内相关专业的专家名单中以随机抽取方式确定。任何单位和个人不得以明示、暗示等任何方式指定或者变相指定参加评标委员会的专家成员。
|
|
|
|
依法必须进行招标的项目的招标人非因招标投标法和本条例规定的事由,不得更换依法确定的评标委员会成员。更换评标委员会的专家成员应当依照前款规定进行。
|
|
|
|
评标委员会成员与投标人有利害关系的,应当主动回避。
|
|
|
|
有关行政监督部门应当按照规定的职责分工,对评标委员会成员的确定方式、评标专家的抽取和评标活动进行监督。行政监督部门的工作人员不得担任本部门负责监督项目的评标委员会成员。
|
|
|
|
第四十七条招标投标法第三十七条第三款所称特殊招标项目,是指技术复杂、专业性强或者国家有特殊要求,采取随机抽取方式确定的专家难以保证胜任评标工作的项目。
|
|
|
|
第四十八条招标人应当向评标委员会提供评标所必需的信息,但不得明示或者暗示其倾向或者排斥特定投标人。
|
|
|
|
招标人应当根据项目规模和技术复杂程度等因素合理确定评标时间。超过三分之一的评标委员会成员认为评标时间不够的,招标人应当适当延长。
|
|
|
|
评标过程中,评标委员会成员有回避事由、擅离职守或者因健康等原因不能继续评标的,应当及时更换。被更换的评标委员会成员作出的评审结论无效,由更换后的评标委员会成员重新进行评审。
|
|
|
|
第四十九条评标委员会成员应当依照招标投标法和本条例的规定,按照招标文件规定的评标标准和方法,客观、公正地对投标文件提出评审意见。招标文件没有规定的评标标准和方法不得作为评标的依据。
|
|
|
|
评标委员会成员不得私下接触投标人,不得收受投标人给予的财物或者其他好处,不得向招标人征询确定中标人的意向,不得接受任何单位或者个人明示或者暗示提出的倾向或者排斥特定投标人的要求,不得有其他不客观、不公正履行职务的行为。
|
|
|
|
第五十条招标项目设有标底的,招标人应当在开标时公布。标底只能作为评标的参考,不得以投标报价是否接近标底作为中标条件,也不得以投标报价超过标底上下浮动范围作为否决投标的条件。
|
|
|
|
第五十一条有下列情形之一的,评标委员会应当否决其投标:
|
|
|
|
|
|
|
|
(三)投标人不符合国家或者招标文件规定的资格条件;
|
|
|
|
(四)同一投标人提交两个以上不同的投标文件或者投标报价,但招标文件要求提交备选投标的除外;
|
|
|
|
(五)投标报价低于成本或者高于招标文件设定的最高投标限价;
|
|
|
|
(六)投标文件没有对招标文件的实质性要求和条件作出响应;
|
|
|
|
(七)投标人有串通投标、弄虚作假、行贿等违法行为。
|
|
|
|
第五十二条投标文件中有含义不明确的内容、明显文字或者计算错误,评标委员会认为需要投标人作出必要澄清、说明的,应当书面通知该投标人。投标人的澄清、说明应当采用书面形式,并不得超出投标文件的范围或者改变投标文件的实质性内容。
|
|
|
|
评标委员会不得暗示或者诱导投标人作出澄清、说明,不得接受投标人主动提出的澄清、说明。
|
|
|
|
第五十三条评标完成后,评标委员会应当向招标人提交书面评标报告和中标候选人名单。中标候选人应当不超过3个,并标明排序。
|
|
|
|
评标报告应当由评标委员会全体成员签字。对评标结果有不同意见的评标委员会成员应当以书面形式说明其不同意见和理由,评标报告应当注明该不同意见。评标委员会成员拒绝在评标报告上签字又不书面说明其不同意见和理由的,视为同意评标结果。
|
|
|
|
第五十四条依法必须进行招标的项目,招标人应当自收到评标报告之日起3日内公示中标候选人,公示期不得少于3日。
|
|
|
|
投标人或者其他利害关系人对依法必须进行招标的项目的评标结果有异议的,应当在中标候选人公示期间提出。招标人应当自收到异议之日起3日内作出答复;作出答复前,应当暂停招标投标活动。
|
|
|
|
第五十五条国有资金占控股或者主导地位的依法必须进行招标的项目,招标人应当确定排名第一的中标候选人为中标人。排名第一的中标候选人放弃中标、因不可抗力不能履行合同、不按照招标文件要求提交履约保证金,或者被查实存在影响中标结果的违法行为等情形,不符合中标条件的,招标人可以按照评标委员会提出的中标候选人名单排序依次确定其他中标候选人为中标人,也可以重新招标。
|
|
|
|
第五十六条中标候选人的经营、财务状况发生较大变化或者存在违法行为,招标人认为可能影响其履约能力的,应当在发出中标通知书前由原评标委员会按照招标文件规定的标准和方法审查确认。
|
|
|
|
第五十七条招标人和中标人应当依照招标投标法和本条例的规定签订书面合同,合同的标的、价款、质量、履行期限等主要条款应当与招标文件和中标人的投标文件的内容一致。招标人和中标人不得再行订立背离合同实质性内容的其他协议。
|
|
|
|
招标人最迟应当在书面合同签订后5日内向中标人和未中标的投标人退还投标保证金及银行同期存款利息。
|
|
|
|
第五十八条招标文件要求中标人提交履约保证金的,中标人应当按照招标文件的要求提交。履约保证金不得超过中标合同金额的10%。
|
|
|
|
第五十九条中标人应当按照合同约定履行义务,完成中标项目。中标人不得向他人转让中标项目,也不得将中标项目肢解后分别向他人转让。
|
|
|
|
中标人按照合同约定或者经招标人同意,可以将中标项目的部分非主体、非关键性工作分包给他人完成。接受分包的人应当具备相应的资格条件,并不得再次分包。
|
|
|
|
中标人应当就分包项目向招标人负责,接受分包的人就分包项目承担连带责任。
|
|
|
|
|
|
第六十一条投诉人就同一事项向两个以上有权受理的行政监督部门投诉的,由最先收到投诉的行政监督部门负责处理。
|
|
|
|
行政监督部门应当自收到投诉之日起3个工作日内决定是否受理投诉,并自受理投诉之日起30个工作日内作出书面处理决定;需要检验、检测、鉴定、专家评审的,所需时间不计算在内。
|
|
|
|
投诉人捏造事实、伪造材料或者以非法手段取得证明材料进行投诉的,行政监督部门应当予以驳回。
|
|
|
|
|
|
第六十三条招标人有下列限制或者排斥潜在投标人行为之一的,由有关行政监督部门依照招标投标法第五十一条的规定处罚:
|
|
|
|
(一)依法应当公开招标的项目不按照规定在指定媒介发布资格预审公告或者招标公告;
|
|
|
|
(二)在不同媒介发布的同一招标项目的资格预审公告或者招标公告的内容不一致,影响潜在投标人申请资格预审或者投标。
|
|
|
|
依法必须进行招标的项目的招标人不按照规定发布资格预审公告或者招标公告,构成规避招标的,依照招标投标法第四十九条的规定处罚。
|
|
|
|
一、第六十四条招标人有下列情形之一的,由有关行政监督部门责令改正,可以处10万元以下的罚款:
|
|
|
|
|
|
(二)招标文件、资格预审文件的发售、澄清、修改的时限,或者确定的提交资格预审申请文件、投标文件的时限不符合招标投标法和本条例规定;
|
|
|
|
|
|
|
|
招标人有前款第一项、第三项、第四项所列行为之一的,对单位直接负责的主管人员和其他直接责任人员依法给予处分。
|
|
|
|
第六十五条招标代理机构在所代理的招标项目中投标、代理投标或者向该项目投标人提供咨询的,接受委托编制标底的中介机构参加受托编制标底项目的投标或者为该项目的投标人编制投标文件、提供咨询的,依照招标投标法第五十条的规定追究法律责任。
|
|
|
|
第六十六条招标人超过本条例规定的比例收取投标保证金、履约保证金或者不按照规定退还投标保证金及银行同期存款利息的,由有关行政监督部门责令改正,可以处5万元以下的罚款;给他人造成损失的,依法承担赔偿责任。
|
|
|
|
第六十七条投标人相互串通投标或者与招标人串通投标的,投标人向招标人或者评标委员会成员行贿谋取中标的,中标无效;构成犯罪的,依法追究刑事责任;尚不构成犯罪的,依照招标投标法第五十三条的规定处罚。投标人未中标的,对单位的罚款金额按照招标项目合同金额依照招标投标法规定的比例计算。
|
|
|
|
投标人有下列行为之一的,属于招标投标法第五十三条规定的情节严重行为,由有关行政监督部门取消其1年至2年内参加依法必须进行招标的项目的投标资格:
|
|
|
|
|
|
|
|
(三)串通投标行为损害招标人、其他投标人或者国家、集体、公民的合法利益,造成直接经济损失30万元以上;
|
|
|
|
|
|
投标人自本条第二款规定的处罚执行期限届满之日起3年内又有该款所列违法行为之一的,或者串通投标、以行贿谋取中标情节特别严重的,由工商行政管理机关吊销营业执照。
|
|
|
|
法律、行政法规对串通投标报价行为的处罚另有规定的,从其规定。
|
|
|
|
第六十八条投标人以他人名义投标或者以其他方式弄虚作假骗取中标的,中标无效;构成犯罪的,依法追究刑事责任;尚不构成犯罪的,依照招标投标法第五十四条的规定处罚。依法必须进行招标的项目的投标人未中标的,对单位的罚款金额按照招标项目合同金额依照招标投标法规定的比例计算。
|
|
|
|
投标人有下列行为之一的,属于招标投标法第五十四条规定的情节严重行为,由有关行政监督部门取消其1年至3年内参加依法必须进行招标的项目的投标资格:
|
|
|
|
(一)伪造、变造资格、资质证书或者其他许可证件骗取中标;
|
|
|
|
|
|
(三)弄虚作假骗取中标给招标人造成直接经济损失30万元以上;
|
|
|
|
|
|
投标人自本条第二款规定的处罚执行期限届满之日起3年内又有该款所列违法行为之一的,或者弄虚作假骗取中标情节特别严重的,由工商行政管理机关吊销营业执照。
|
|
|
|
第六十九条出让或者出租资格、资质证书供他人投标的,依照法律、行政法规的规定给予行政处罚;构成犯罪的,依法追究刑事责任。
|
|
|
|
第七十条依法必须进行招标的项目的招标人不按照规定组建评标委员会,或者确定、更换评标委员会成员违反招标投标法和本条例规定的,由有关行政监督部门责令改正,可以处10万元以下的罚款,对单位直接负责的主管人员和其他直接责任人员依法给予处分;违法确定或者更换的评标委员会成员作出的评审结论无效,依法重新进行评审。
|
|
|
|
国家工作人员以任何方式非法干涉选取评标委员会成员的,依照本条例第八十一条的规定追究法律责任。
|
|
|
|
第七十一条评标委员会成员有下列行为之一的,由有关行政监督部门责令改正;情节严重的,禁止其在一定期限内参加依法必须进行招标的项目的评标;情节特别严重的,取消其担任评标委员会成员的资格:
|
|
|
|
|
|
|
|
|
|
|
|
(五)向招标人征询确定中标人的意向或者接受任何单位或者个人明示或者暗示提出的倾向或者排斥特定投标人的要求;
|
|
|
|
|
|
(七)暗示或者诱导投标人作出澄清、说明或者接受投标人主动提出的澄清、说明;
|
|
|
|
|
|
第七十二条评标委员会成员收受投标人的财物或者其他好处的,没收收受的财物,处3000元以上5万元以下的罚款,取消担任评标委员会成员的资格,不得再参加依法必须进行招标的项目的评标;构成犯罪的,依法追究刑事责任。
|
|
|
|
第七十三条依法必须进行招标的项目的招标人有下列情形之一的,由有关行政监督部门责令改正,可以处中标项目金额10%。以下的罚款;给他人造成损失的,依法承担赔偿责任;对单位直接负责的主管人员和其他直接责任人员依法给予处分:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
第七十四条中标人无正当理由不与招标人订立合同,在签订合同时向招标人提出附加条件,或者不按照招标文件要求提交履约保证金的,取消其中标资格,投标保证金不予退还。对依法必须进行招标的项目的中标人,由有关行政监督部门责令改正,可以处中标项目金额10‰以下的罚款。
|
|
|
|
第七十五条招标人和中标人不按照招标文件和中标人的投标文件订立合同,合同的主要条款与招标文件、中标人的投标文件的内容不一致,或者招标人、中标人订立背离合同实质性内容的协议的,由有关行政监督部门责令改正,可以处中标项目金额5‰以上10‰以下的罚款。
|
|
|
|
第七十六条中标人将中标项目转让给他人的,将中标项目肢解后分别转让给他人的,违反招标投标法和本条例规定将中标项目的部分主体、关键性工作分包给他人的,或者分包人再次分包的,转让、分包无效,处转让、分包项目金额5‰以上10‰以下的罚款;有违法所得的,并处没收违法所得;可以责令停业整顿;情节严重的,由工商行政管理机关吊销营业执照。
|
|
|
|
第七十七条投标人或者其他利害关系人捏造事实、伪造材料或者以非法手段取得证明材料进行投诉,给他人造成损失的,依法承担赔偿责任。
|
|
|
|
招标人不按照规定对异议作出答复,继续进行招标投标活动的,由有关行政监督部门责令改正,拒不改正或者不能改正并影响中标结果的,依照本条例第八十二条的规定处理。
|
|
|
|
第八十一条国家工作人员利用职务便利,以直接或者间接、明示或者暗示等任何方式非法干涉招标投标活动,有下列情形之一的,依法给予记过或者记大过处分;情节严重的,依法给予降级或者撤职处分;情节特别严重的,依法给予开除处分;构成犯罪的,依法追究刑事责任:
|
|
|
|
(一)要求对依法必须进行招标的项目不招标,或者要求对依法应当公开招标的项目不公开招标;
|
|
|
|
(二)要求评标委员会成员或者招标人以其指定的投标人作为中标候选人或者中标人,或者以其他方式非法干涉评标活动,影响中标结果;
|
|
|
|
|
|
第八十二条依法必须进行招标的项目的招标投标活动违反招标投标法和本条例的规定,对中标结果造成实质性影响,且不能采取补救措施予以纠正的,招标、投标、中标无效,应当依法重新招标或者评标。
|
|
|