|
|
|
要想在一个实际网络中实现组播数据包的转发,必须在各个互连设备上运行可互操作的组播路由协议。组播路由协议可分为三类:密集模式协议(如DVMRP, PIM-DM)、稀疏模式协议(如PIM-SM, CBT)和链路状态协议(MOSPF),下面分别介绍各个协议的工作原理。
|
|
|
|
距离向量组播路由协议(Distance Vector Multicast Routing Protocol, DVMRP)
|
|
|
|
DVMRP由单播路由协议RIP扩展而来,两者都使用距离向量算法得到网络的拓扑信息,不同之处在于RIP根据路由表前向转发数据,而DVMRP则是基于RPF。为了使新加入的组播成员能及时收到组播数据,DVMPR采用定时发送数据包给所有的LAN的方法,然而这种方法导致大量路由控制数据包的扩散,这部分开销限制了网络规模的扩大。另一方面,DVMRP使用跳数作为计量尺度,其上限为32跳,这对网络规模也是一个限制。目前提出了分层DVMRP,即对组播网络划分区域,在区域内的组播可以按照任何协议进行,而对于跨区域的组播则由边界路由器在DVMRP协议下进行,这样可大大减少路由开销。
|
|
|
|
开放式组播最短路径优先协议(Multicast Open Shortest Path First, MOSPF)
|
|
|
|
MOSPF是一种基于链路状态的路由协议,是对单播OSPF协议的扩展。
|
|
|
|
|
|
①MOSPF区域内组播路由:用于了解各网段中的组播成员,构造(源网络S,组G)对的SPT;
|
|
|
|
②MOSPF区域间组播路由:用于汇总区域内成员关系,并在自治系统(AS)主干网(区域0)上发布组成员关系记录通告,实现区域间组播包的转发。
|
|
|
|
③MOSPF AS间组播路由:用于跨AS的组播包转发。
|
|
|
|
区域内MOFPF利用了链路状态数据库,对单播OSPF数据格式进行扩充,定义了新的链路状态通告(Link State Advertisement, LSA),使得MOSPF路由器了解哪些多播组在哪些网络上。路由器使用Dijkstra算法构造(源网络S,组G)对的SPT。MOSPF与DVMRP相比,路由开销较小,链路利用率高,然而Dijkstra算法计算量很大,为了减少路由器的计算量,MOSPF执行一种按需计算方案,即只有当路由器收到组播源的第一个组播数据包后,才对(S,G)SPT计算,否则利用转发缓存(cache)中的(S,G)SPT。
|
|
|
|
MOSPF继承了OSPF对网络拓扑的变化响应速度快的优点,但拓扑变动使所有路由器的缓存失效重新计算SPT,因而消耗大量路由器CPU资源。这就决定了MOSPF不适合高动态性网络(组成员关系变化大、链路不稳定),而适用于网络连接状态比较稳定的环境。另外,对于有大量组播源子网络的网络而言,MOSPF的扩展性问题引起了人们的关注,有待于进一步研究。
|
|
|
|
协议无关组播(Protocol Independent Multicast, PIM)
|
|
|
|
PIM由IDMR(域间组播路由)工作组设计,顾名思义,PIM不依赖于某一特定单播路由协议,它可利用各种单播路由协议建立的单播路由表完成RPF检查功能,而不是维护一个分离的组播路由表实现组播转发。由于PIM无须收发组播路由更新,所以与其他组播协议相比,PIM开销降低了许多。PIM的设计出发点是在Internet范围内同时支持SPT和共享树,并使两者之间灵活转换,因而集中了它们的优点提高了组播效率。PIM定义了两种模式:密集模式(Dense-Mode, DM)和稀疏模式(Sparse-Mode, SM)。
|
|
|
|
|
|
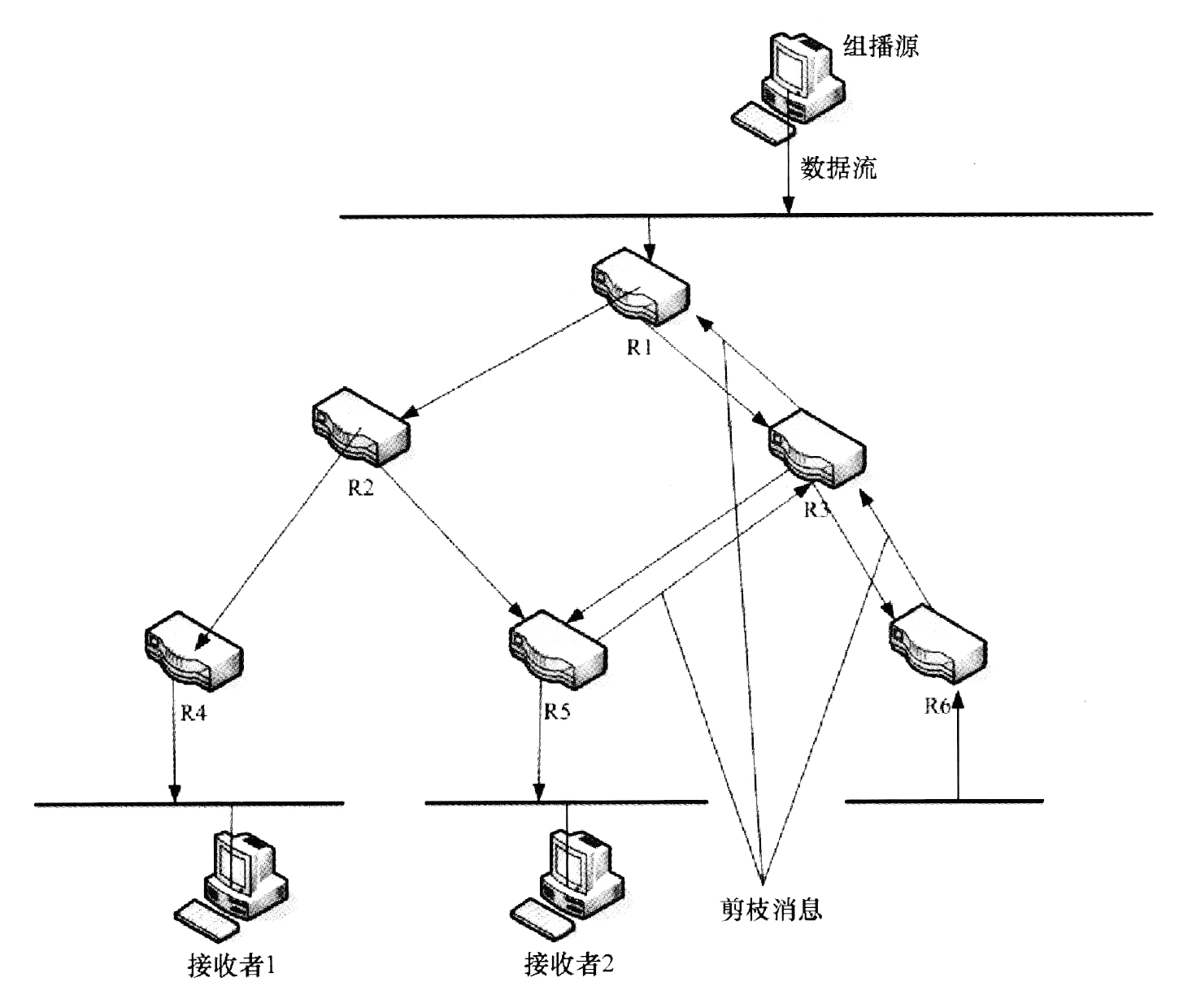
PIM-DM与DVMRP很相似,都属于密集模式协议,都采用了"扩散/剪枝"机制,如下图所示。同时,假定带宽不受限制,每个路由器都想接收组播数据包。主要不同之处在于DVMRP使用内建的组播路由协议,而PIM-DM采用RPF动态建立SPT。
|
|
|
|
|
|
|
|
该模式适合于下述几种情况:高速网络;组播源和接收者比较靠近,发送者少,接收者多;组播数据流比较大且比较稳定。
|
|
|
|
|
|
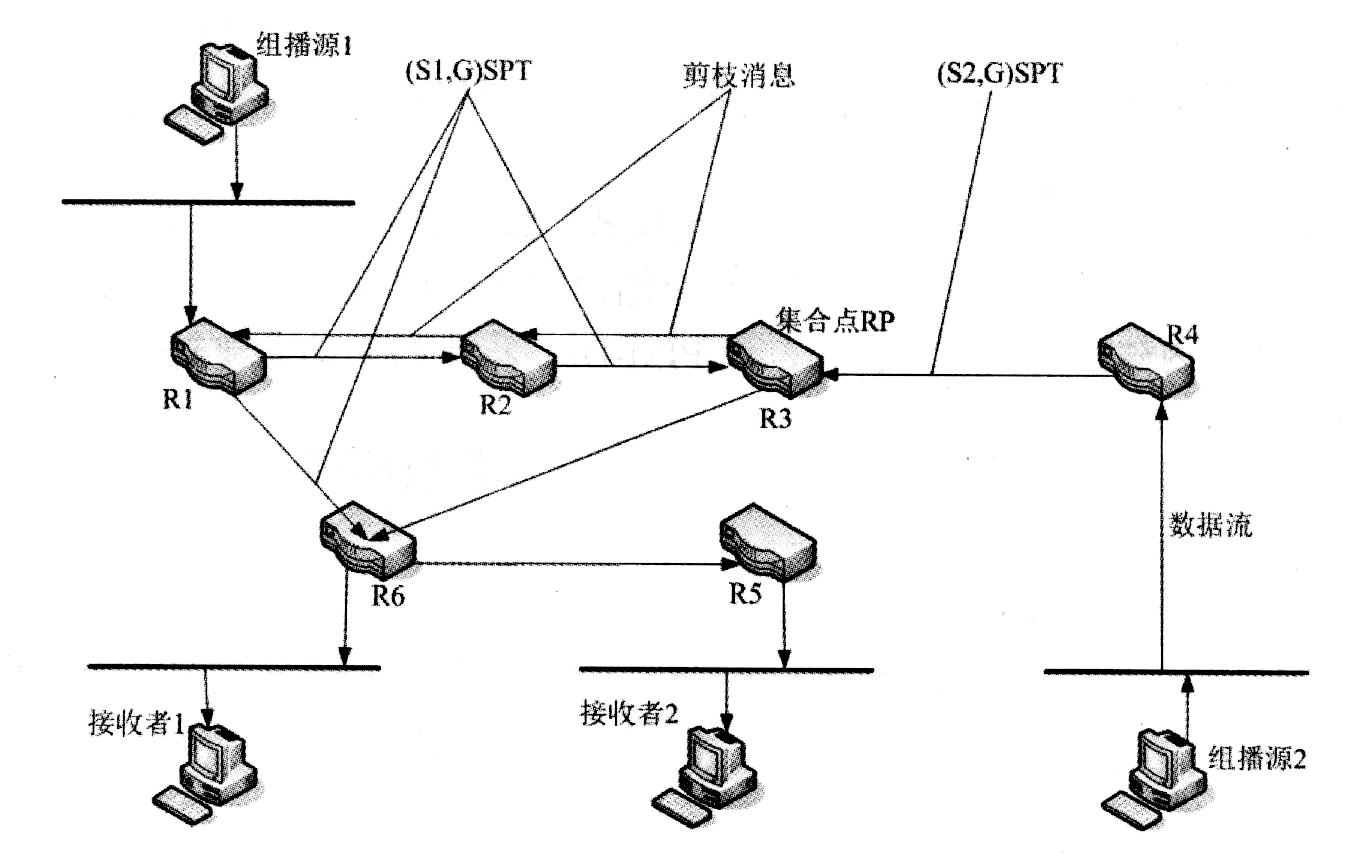
PIM-SM与基于"扩散/剪枝"模型的根本差别在于PIM-SM是基于显式加入模型,即接收者向RP发送加入消息,而路由器只在已加入某个多播组输出接口上转发那个多播组的数据包。
|
|
|
|
PIM-SM采用共享树进行组播数据包转发。每一个组有一个汇合点(Rendezvous Point, RP),组播源沿最短路径向RP发送数据,再由RP沿最短路径将数据发送到各个接收端,如下图所示。这一点类似于CBT,但PIM-SM不使用核的概念。PIM-SM主要优势之一是它不局限于通过共享树接收组播信息,还提供从共享树向SPT转换的机制。
|
|
|
|
|
|
|
|
尽管从共享树向SPT转换减少了网络延迟以及在RP上可能出现的阻塞,但这种转换耗费了相当的路由器资源,所以它适用于有多对组播数据源和网络组数目较少的环境。
|
|
|
|
有核树组播路由协议(Core-Based Trees, CBT)
|
|
|
|
CBT的基本目标是减少网络中路由器组播状态,以提供组播的可扩展性。为此,CBT被设计成稀疏模式(与PIM-SM相似)。CBT使用双向共享树,双向共享树以某个核心路由器为根,允许组播信息在两个方向流动。这一点与PIM-SM不同(PIM-SM中共享树是单向的,在RP与组播源之间使用SPT将组播数据转发到RP),所以CBT不能使用RPF检查,而使用IP包头的目标组地址作检查转发缓存。这就要求对CBT共享树的维护非常小心,以确保不会产生组播路由循环。
|
|
|
|
从路由器创建的组播状态的数量来看,CBT比支持SPT的协议效率高,在具有大量组播源和组的网络中,CBT能把组播状态优化到组的数量级。
|
|
|
|
CBT为每个组播组建立一个生成树,所有组播源使用同一棵组播树。CBT工作过程大体如下。
|
|
|
|
(1)首先选择一个核,即网络中多播组的固定中心,来构造一棵CBT。
|
|
|
|
|
|
(3)所有中间路由器都接收到该命令,并把接收该命令的接口标记为属于这个组的树。
|
|
|
|
(4)如果接收到命令的路由器已是树中一个成员,那么只要再标记一次该接口属于该组;如果路由器第一次收到join命令,那么它就向核的方向进一步转发该命令,路由器就需要为每个组保留一份状态信息。
|
|
|
|
(5)当组播数据到达一个在CBT树上的组播路由器时,路由器组播数据到树的核。以保证数据能够发送到组的所有成员。
|
|
|
|
CBT将组播扩张限制在接收者范围内,即使第一个数据包也无须在全网扩散,但CBT导致核周围的流量集中,网络性能下降。所以某些版本的CBT支持多个核心以平衡负载。
|
|
|
|
目前CBTv3草案已公布。该方案通过使用CBT边界路由器(BR)更好地处理域间组播的转发。CBTv3还引入新的状态及单向分支CBT概念。尽管CBT很有代表性,但至今却几乎没有已实现的CBT网络。
|
|
|