|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
声音是由振动产生的。物体振动停止,发声也停止。当振动波传到人耳时,人便听到了声音。人耳能感受到(听觉)的频率范围为20Hz~20kHz,称此频率范围内的声音为可听声(audible sound)或音频(audio),频率小于20Hz的声音为次声,频率大于20kHz的声音为超声。人的发音器官所发出的声音(人声)的频率大约是80~3400Hz。人说话的声音(话音/语音)的频率通常为300~3000Hz(带宽约3kHz)。
|
|
|
|
声音具有三个要素:音调、响度(音量/音强)和音色。人耳就是根据声音的三要素区分声音的。
|
|
|
|
音调(pitch)就是声音的高低(高音、低音),由“频率”(frequency)决定,频率越高,音调越高。声音的频率是指每秒声音信号变化的次数,用Hz表示。例如,20Hz表示声音信号在1秒内周期性地变化20次。
|
|
|
|
响度(loudness)又称音量、音强,指人主观上感觉声音的大小,由“振幅”(amplitude)和人与声源的距离决定,振幅越大,响度越大,人和声源的距离越小,响度越大。响度的单位为分贝(dB)。
|
|
|
|
音色(music quality)又称音品,由发声物体的材料、结构决定。每个人讲话的声音以及钢琴、小提琴、笛子等乐器所发出的不同声音都是由不同音色造成的。
|
|
|
|
|
|
|
|
音频信号是典型的连续信号,不仅在时间上是连续的,而且在幅度上也是连续的。在时间上“连续”是指在任何一个指定的时间范围内,声音信号都有无穷多个幅值;在幅度上“连续”是指幅度的数值为实数。人们把在时间(或空间)和幅度上都连续的信号称为模拟信号(analog signal)。
|
|
|
|
|
|
模拟信号由于在时间和幅度上都是连续的,因此计算机无法处理这类信号。为了让计算机能够处理这些信号,必须将时间和幅度上的信号都进行离散化。人们把在时间和幅度上都用离散的数字表示的信号称为数字信号(digital signal)。
|
|
|
|
从模拟信号到数字信号的转换为模数转换,记为A/D(Analog to Digital)。
|
|
|
|
从数字信号到模拟信号的转换为数模转换,记为D/A(Digital to Analog)。
|
|
|
|
|
|
计算机处理和存储的只能是二进制数,所以在使用计算机处理和存储声音信号之前,必须使用模数转换(A/D)技术将模拟音频转化为二进制数,这样模拟音频就转化为数字音频。转换过程包括采样、量化和编码三个步骤,下图显示了音频数字化的过程。模拟音频向数字音频的转换是在计算机的声卡中完成的。
|
|
|
|
|
|
|
|
|
|
采样是指将时间轴上连续的信号每隔一定的时间间隔便抽取出一个信号的幅度样本,把连续的模拟量用一个个离散的点表示出来,使其成为在时间上离散的脉冲序列。
|
|
|
|
每秒采样的次数称为采样频率,用f表示;样本之间的时间间隔称为采样周期,用T表示,T=1/f。例如,CD的采样频率为44.1kHz,表示每秒采样44100次。常用的采样频率有8kHz、11.025kHz、22.05kHz、15kHz、44.1kHz、48kHz等。
|
|
|
|
|
|
量化是指将采样后的离散信号的幅度用二进制数表示的过程。
|
|
|
|
每个采样点所能表示的二进制位数称为采样位数(也称量化位数)。采样位数反映了度量声音波形幅度的精度。例如,每个声音样本用16位(2字节)表示,测得的声音样本值为0~65536,它的精度就是输入信号的1/65536。常用的采样位数为8b/s、12b/s、16b/s、20b/s、24b/s等。
|
|
|
|
采样频率、采样位数和声道数对声音的音质和占用的存储空间起着决定性作用。
|
|
|
|
人们希望音质越高越好,占用的磁盘存储空间越少越好,这本身就是一个矛盾。必须在音质和磁盘存储空间之间取得平衡。声音采样的各个要素之间的关系可以用下述公式表示。
|
|
|
|
|
|
数据量=数据率×时间=采样频率×采样位数×声道数×时间/8
|
|
|
|
采样精度还有另一种表示方法,就是信号量化噪声比,简称信噪比(Signal Quantization Noise Ratio, SQNR),通过下式计算:
|
|
|
|
|
|
其中,Vsignal表示信号电压,Vnoise表示量化噪声电压,也就是模拟信号的采样值和与它最接近的数字数值之间的差值,SQNR的单位为分贝(db)。
|
|
|
|
|
|
采样和量化后的信号还不是数字信号,需要把它转换成数字编码脉冲,这一过程称为编码。最简单的编码方式是二进制编码,即将已经量化的信号幅值用二进制数表示,计算机采用的就是这种编码方式。
|
|
|
|
模拟音频经过采样、量化和编码后所形成的二进制序列就是数字音频信号,可以将其以文件的形式保存在计算机的存储设备中,这样的文件通常称为数字音频文件。
|
|
|
|
|
|
|
|
一种频率的声音(掩蔽声音,masking tone)阻碍听觉系统感受另一种频率的声音(被掩蔽声音,masked tone)的现象称为掩蔽效应。掩蔽效应在日常生活中很常见,例如在一个安静的环境中,人们能听到吉他手的手指轻轻滑过琴弦的响声,但如果同样的响声出现在播放摇滚乐曲的环境中,那么一般人就听不到它了。
|
|
|
|
掩蔽效应可分为频域掩蔽和时域掩蔽。频域掩蔽是指一个强纯音掩蔽在其附近同时发声的弱纯音的特性,也称同时掩蔽(simultaneous masking)。除了同时发出的声音之间有掩蔽现象之外,在时间上相邻的声音之间也有掩蔽现象,称为时域掩蔽。时域掩蔽又分为超前掩蔽(pre-masking)和滞后掩蔽(post-masking)。产生时域掩蔽的主要原因是人的大脑在处理信息时需要花费一定的时间。一般来说,超前掩蔽很短,只有5~20ms,而滞后掩蔽可以持续50~200ms。
|
|
|
|
|
|
对于人类的听觉来说,对声音的感知特性并不是以线形频率为尺度变化的,而是可以用被称为临界频带的一系列有限的频段表达。简单地说,把整个频带划分成几段,在每个频段里,人耳的听觉感知是相同的,即心理声学特性都是一样的。这里定义人耳刚好可以感知的两种频率的声音有差别的频率范围为临界频带。通常认为声音(audio)有25个临界频带,临界频带的宽度随声音频率的变化而变化。在低频端,宽度小于100Hz可认为接近于常数;在高频端,宽度近似线性增加,最高可达4kHz。临界频带的单位为巴克(Bark),1Bark等于一个临界频带的宽度。
|
|
|
|
|
|
人的听觉灵敏度随着频率而改变,即通常两个功率一样但频率不同的音调听起来并不一样响。通过下图所示的等响度曲线可知,人耳对4kHz的频率最敏感,即在4kHz下能被察觉出来的声音压力水平(响度)在其他频率下并不能被察觉,这就给在一些不太灵敏的频率下失真提供了条件。
|
|
|
|
|
|
|
|
|
|
将量化后的数字声音信息直接存入计算机将会占用大量的存储空间。在多媒体音频信号处理中,一般需要对数字化后的声音信号进行压缩编码,使其成为具有一定字长的二进制数字序列,以减少音频的数据量,并以这种形式在计算机内传输和存储。在播放这些声音时,需要经解码器将二进制编码恢复成原来的声音信号。
|
|
|
|
|
|
. 声音信号中存在着很大的冗余度,通过识别和去除这些冗余度能达到压缩的目的。
|
|
|
|
. 音频信息的最终接收者是人,人的视觉和听觉器官都具有某种不敏感性。舍去人的感官所不敏感的信息对声音质量的影响很小,在有些情况下甚至可以忽略不计。例如,人耳听觉有一个重要的特点,即听觉的“掩蔽”,指一个强音能抑制一个同时存在的弱音的听觉现象。利用该性质可以抑制与信号同时存在的量化噪声。
|
|
|
|
. 对声音波形进行采样后,相邻采样值之间存在着很强的相关性。
|
|
|
|
|
|
按照压缩原理的不同,声音的压缩编码可分为3类,即波形编码、参数编码和混合型编码。
|
|
|
|
|
|
波形编码主要利用音频采样值的幅度分布规律和相邻采样值之间的相关性进行压缩,目标是力图使重构的声音信号的各个样本尽可能地接近于原始声音的采样值。这种编码保留了信号原始采样值的细节变化,即保留了信号的各种过渡特征,因此复原的声音质量较高。波形编码技术有脉冲编码调制(PCM)、自适应增量调制(ADM)和自适应差分脉冲编码调制(ADPCM)等。
|
|
|
|
|
|
参数编码是一种对语音参数进行分析合成的方法。语音的基本参数是基音周期、共振峰、语音谱、声强等,如能得到这些语音基本参数,就可以不对语音的波形进行编码,只要记录和传输这些参数就能实现声音数据的压缩。这些语音基本参数可以通过分析人的发音器官的结构及语音生成的原理建立语音生成的物理或数学模型。得到语音参数后,就可以对其进行线性预测编码(Linear Predictive Coding, LPC)。
|
|
|
|
|
|
混合型编码是一种在保留参数编码技术的基础上,引用波形编码准则去优化激励源信号的方案。混合型编码充分利用了线性预测技术和综合分析技术,其典型算法有:码本激励线性预测(CELP)、多脉冲线性预测(MP-LPC)、矢量和激励线性预测(VSELP)等。
|
|
|
|
波形编码可以获得很高的声音质量,因此在声音编码方案中应用较广。下面介绍波形编码方案中常用的PCM编码。
|
|
|
|
|
|
PCM脉冲编码调制是对连续语音信号进行空间采样、幅度值量化及用适当码字将其编码的总称,即它把连续输入的模拟信号变换为在时域和振幅上都离散的量,然后将其转化为代码形式传输或存储,其原理框图如下图所示。在下图中,输入是模拟声音信号,输出是PCM样本。下图中的防失真滤波器是一个低通滤波器,用来滤除声音频带以外的信号;波形编码器可暂时理解为采样器;量化器可理解为量化阶大小(step-size)生成器或者量化间隔生成器。
|
|
|
|
|
|
|
|
PCM方法可以按量化方式的不同分为均匀量化、非均匀量化和自适应量化等。
|
|
|
|
|
|
采用相等的量化间隔对采样得到的信号进行量化称为均匀量化,也称线性量化。均匀量化将输入的声音信号的振幅范围分成2B个等份(B为量化的二进制位数),所有落入同一等份数的采样值都被编码成相同的B位二进制码。只要采样频率足够大,量化位数也适当,便能获得较高的声音信号数字化效果。为了满足听觉效果,均匀量化必须使用较多的量化位数,这样所记录和产生的音乐才可以达到最接近原声的效果。当然,提高采样率及分辨率将造成存储数据空间的增大。
|
|
|
|
为了适应幅度大的输入信号,同时又要满足精度要求,就需要增加样本的位数。但是,对话音信号来说,大信号出现的机会并不多,增加的样本位数没有被充分利用。为了克服这个不足,出现了非均匀量化的方法,这种方法也称非线性量化。
|
|
|
|
|
|
对输入信号进行量化时,大的输入信号采用大的量化间隔,小的输入信号采用小的量化间隔,这样就可以在满足精度要求的情况下用较少的位数表示。声音数据还原时则采用相同的规则。
|
|
|
|
|
|
自适应量化是一种根据输入信号幅度改变量化阶距的一种波形编码技术。这种自适应可以是瞬时自适应(即量化阶距每隔几个样本就改变),也可以是音节自适应(即量化阶距在较长的时间周期内发生变化)。
|
|
|
|
|
|
|
|
MIDI(Musical Instrument Digital Interface,乐器数字接口)是数字音乐国际标准。从20世纪80年代初期开始,MIDI逐渐被音乐家和作曲家广泛接受和使用。MIDI是乐器和计算机使用的标准语言,是一套指令(即命令的约定),它指示乐器(即MIDI设备)要做什么、怎么做,如奏出音符、加大音量、生成音效等。这里强调一下,MIDI不是声音信号,而是发给MIDI设备或其他装置并能让它产生声音或执行某个动作的指令。
|
|
|
|
MIDI将电子乐器键盘的弹奏信息记录下来,包括键名、力度、时值长短等,这些信息称为MIDI信息。MIDI文件相对于普通声音文件有两大优点:一是所需存储容量小,例如CD-DA格式的波形声音播放1小时的立体声音乐需要600MB的存储容量,而播放同时间的MIDI音乐仅需要400KB左右的存储容量,两者相差1000倍以上;二是编辑修改十分灵活,例如可任意修改曲子的速度、音调,也可以改变乐器等。
|
|
|
|
目前,MIDI的标准主要有三个:GS标准、GM标准和XG标准。GS标准是日本罗兰公司于1984年提出的,该标准大大增强了音乐的表现力。1991年,为了更有利于音乐家广泛地使用不同的合成器设备和促进MIDI文件的交流,国际MIDI生产者协会(MMA)制定了通用MIDI标准——GM标准,该标准是在GS标准的基础上制定的。GM标准的提出得到了Windows操作系统的支持,使得数字音乐设备之间的信息交流得到了简化,受到了全世界数字音乐爱好者的一致好评。1994年,YAMAHA公司在GM标准上推出了自己的XG标准的MIDI格式,增加了更多的乐器组,扩大了MIDI标准定义范围,在专业音乐范围内得到了广泛的应用。
|
|
|
|
|
|
MIDI文件是一种描述性的“音乐语言”,它将所要演奏的乐曲信息用字节进行描述。例如在某一时刻使用什么乐器、以什么音符开始、以什么音调结束、加什么伴奏等。要想形成计算机音乐,必须通过音乐合成。
|
|
|
|
目前,音乐合成的方法主要有两种:一种是频率调制(Frequency Modulation, FM)合成,另一种是波表合成。早期的ISA声卡普遍使用的是FM合成,目前基本上使用的是波表合成。
|
|
|
|
|
|
FM合成方式是由波形的组合而产生的,它是使高频震荡波的频率按调制信号规律变换的一种调制方式。采用不同的调制波频率和调制指数可以方便地合成具有不同频谱分布的波形,再现某些乐器的音色,而且可以创造出丰富多彩甚至真实乐器不具备的音色。理论上,波形有无限多组,可以模拟任何声音,但实际上使用得最多的只有通过4个正弦波产生器模拟音色,所以FM合成在发出General MIDI中的乐器声时,其真实效果较差。
|
|
|
|
|
|
波表合成采用真实的声音样本进行播放,音乐效果更逼真,但由于需要额外的存储器存储音色库,因此成本较高。波表中的钢琴声就是对钢琴声进行录音,再利用PCM编码将钢琴声作为数字信号样本存入ROM中(而FM则是用波形进行模拟的),所以当接口卡要发出钢琴的声音时,波表发出的是真正的钢琴声,而FM则是用波形模拟合成的。
|
|
|
|
|
|
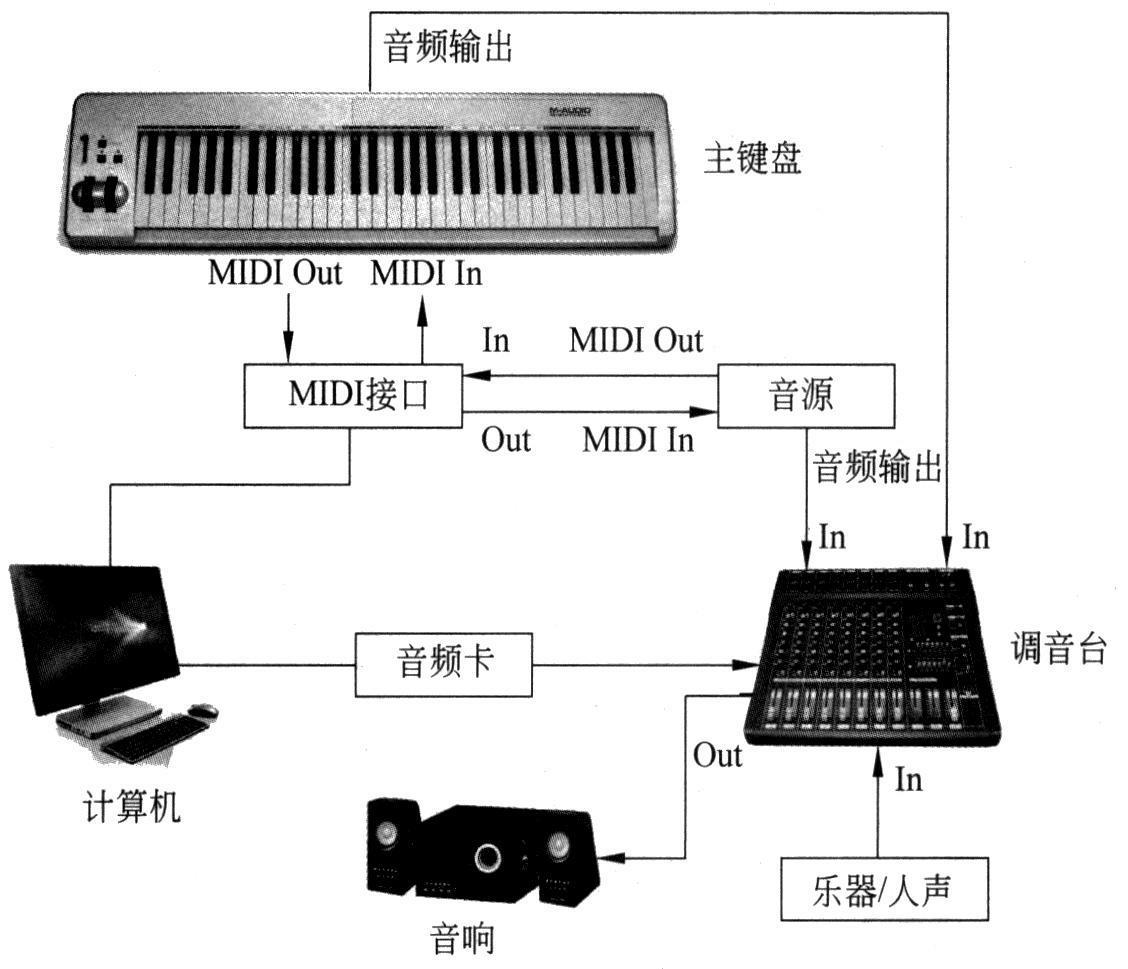
一个MIDI系统一般需要以下三个基本要素:音序器或音序软件、主键盘和音源。各要素之间的连接通过MIDI接口完成。
|
|
|
|
|
|
音序器相当于音乐词处理器(word processor),利用音序器可以记录、播放和编辑各种不同MIDI乐器演奏出的乐曲。音序器记录的不是真正的声音,而是MIDI信息。MIDI信息很像印在纸上的乐谱,本身不能直接产生音乐,只是包含产生音乐所需的所有指令,例如用什么乐器、奏什么音符、奏得多快、奏的力度等。
|
|
|
|
音序器可以是硬件,也可以是软件,它们的作用过程与专业录音棚里的多轨录音机一样,可以把许多独立的声音记录在音序器里,其区别是音序器只记录演奏时的MIDI数据,而不记录声音;它可以一轨一轨地进行录制,也可以一轨一轨地进行修改,当弹奏键盘音乐时,音序器记录从键盘发来的MIDI数据。一旦把所需要的数据存储下来,就可以播放刚做好的曲子。硬件音序器的音轨数相对少一些,一般为8~16轨,而音序器软件的音轨数一般为64~200轨。
|
|
|
|
硬件音序器主要有两类:一类是专门的音序器(如YAMAHA-QY300),还有一类是装在合成器里的音序器(如KORG01/W)。这种硬件音序器具有共同的弱点:不可升级、编辑功能逐渐落后、操作烦琐、界面简单等,所以后期都逐渐被音序软件所代替。
|
|
|
|
常用的音序软件一般有:CAKEWALK、CUBASE、MASTERTRACK等。音序软件操作方便、界面简单明了、升级方便、更新换代简单。
|
|
|
|
|
|
主键盘是向音序器输入音符和部分控制信息的输入设备。主键盘一般有两类:一类是空白控制键盘,这种键盘手感好,但没有音色,还需另配音源;另一类是带有音源的控制键盘,这种键盘有音源,并且有触键力度响应、延音脚踏板、弯音控制轮等功能。
|
|
|
|
|
|
音源是系统的输出设备,音源的形式较多,可以是一块声卡或一台音源器,也可以是一台带有音源的合成器。
|
|
|
|
|
|
MIDI规范规定,每种MIDI装置由一个接收器和一个发送器组成。发送器生成符合MIDI格式的消息并向外发送,接收器接收MIDI格式的消息并执行MIDI命令。MIDI收发器可用一种通用的异步收发器互相连接,数据传输速度为31250b/s,每个数据位前后各有一个起始位和一个停止位。
|
|
|
|
MIDI端口有三种:MIDI输入(MIDI-In)用来接收从其他MIDI设备发送过来的消息;MIDI输出(MIDI-Out)用来发送本设备产生的原始MIDI消息;MIDI转发(MDI-Thru)用来在MIDI设备之间转发消息。MIDI设备可以同时具有3种端口,但是至少应具有其中一种端口。
|
|
|
|
|
|
|
|
|
|
这个系统可以实现MIDI音乐的制作和录音,上图中的调音台的主要功能是将多路输入信号进行放大、混合、分配、音质修饰和音响效果加工。
|
|
|
|
|
|
|
|
|
|
WAV是微软公司开发的一种声音文件格式。标准格式化的WAV文件采用44.1kHz的采样频率和16位量化位数,其音质非常好,被大量软件所支持,适用于多媒体开发、保存音乐和原始音效素材;其缺点是文件过大,不便于交流和传播;其后缀名为wav。
|
|
|
|
|
|
标准CD格式采用44.1kHz的采样频率,速率为88kb/s,16位量化位数,近似无损。CD光盘可以在CD唱机中播放,也能用计算机中的各种播放软件重放。一个CD音频文件是一个cda文件,这只是一个索引信息,并非真正包含声音信息,所以不论CD音乐时长的长短,在计算机上看到的cda文件都是44字节。
|
|
|
|
|
|
MP3的全称是Moving Picture Experts Group Audio Layer Ⅲ,即ISO标准MPEG-1和MPEG-2的第三层,是当今较为流行的一种数字音频编码和有损压缩格式,所使用的采样频率为16~48kHz,编码速率为8kb/s~1.5Mb/s。其特点是音质好,压缩比较高,被大量软件和硬件支持,应用广泛,适合用于一般及要求较高的音乐欣赏。
|
|
|
|
|
|
MP3 Pro是新一代的MP3格式,是MP3编码格式的升级版本。MP3 Pro是由瑞典Coding科技公司开发的,在保持相同音质的条件下可以把声音文件的文件量压缩到原有MP3格式的一半,而且可以在基本不改变文件大小的情况下改善原有MP3音乐的音质。该格式能够在使用较低的比特率压缩音频文件的情况下最大限度地保持压缩前的音质。
|
|
|
|
|
|
MIDI格式存储的不是数字的音频波形,而是音乐代码或电子乐谱。MIDI文件每存储1min的音乐只占用5~10KB。MIDI文件主要用于原始乐器作品、流行歌曲的业余表演、游戏音轨以及电子贺卡等;其后缀名为mid。
|
|
|
|
|
|
WMA(Windows Media Audio)由微软公司开发,其音质要强于MP3格式,更远胜于RA格式,它以减少数据流量但保持音质的方法达到比MP3压缩率更高的目的,WMA格式的压缩率一般可以达到1:18,并内置版权保护技术,可以限制播放时间和播放次数,甚至播放的机器。WMA格式在录制时可以对音质进行调节。在同一格式下,音质甚至可与CD媲美,压缩率较高的WMA文件可用于网络广播。
|
|
|
|
|
|
RA格式主要适用于在网络上的在线音乐欣赏,有的下载站点会提示用户根据其Modem速率选择最佳的RA文件。
|
|
|