|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
大数据技术体系纷繁复杂,其中一些技术创新格外受到关注。随着社交网络的流行导致大量非结构化数据出现,传统处理方法难以应对,数据处理系统和分析技术开始不断发展。从2005年Hadoop的诞生开始,形成了数据分析技术体系这一热点。伴随着量急剧增长和核心系统对吞吐量以及时效性的要求提升,传统数据库需向分布式转型,形成了事务处理技术体系这一热点。然而时代的发展使得单个企业甚至行业的数据都难以满足要求,融合价值更加显现,形成了数据流通技术体系这一热点。
|
|
|
|
|
|
从数据在信息系统中的生命周期看,数据分析技术生态主要有5个发展方向,包括数据采集与传输、数据存储与管理、计算处理、查询与分析、可视化展现。在数据采集与传输领域渐渐形成了Sqoop、Flume、Kafka等一系列开源技术,兼顾离线和实时数据的采集和传输。在存储层,HDFS已经成为了大数据磁盘存储的事实标准,针对关系型以外的数据模型,开源社区形成了K-V(key-value)、列式、文档、图这四类NoSQL数据库体系,Redis、HBase、Cassandra、MongoDB、Neo4j等数据库是各个领域的领先者。计算处理引擎方面,Spark已经取代MapReduce成为了大数据平台统一的计算平台,在实时计算领域Flink是Spark Streaming强力的竞争者。在数据查询和分析领域形成了丰富的SQL on Hadoop的解决方案,Hive、HAWQ、Impala、Presto、Spark SQL等技术与传统的大规模并行处理(Massively Parallel Processor,MPP)数据库竞争激烈,Hive还是这个领域当之无愧的王者。在数据可视化领域,敏捷商业智能(Business Intelligence,BI)分析工具Tableau、QlikView通过简单的拖拽来实现数据的复杂展示,是目前最受欢迎的可视化展现方式。
|
|
|
|
相比传统的数据库和MPP数据库,Hadoop最初的优势来源于良好的扩展性和对大规模数据的支持,但失去了传统数据库对数据精细化的操作,包括压缩、索引、数据的分配裁剪以及对SQL的支持度。经过10多年的发展,数据分析的技术体系渐渐在完善自己的不足,也融合了很多传统数据库和MPP数据库的优点,从技术的演进来看,大数据技术正在发生以下变化:
|
|
|
|
(1)更快。Spark已经替代MapReduce成为了大数据生态的计算框架,以内存计算带来计算性能的大幅提高,尤其是Spark 2.0增加了更多了优化器,计算性能进一步增强。
|
|
|
|
(2)流处理的加强。Spark提供一套底层计算引擎来支持批量、SQL分析、机器学习、实时和图处理等多种能力,但其本质还是小批的架构,在流处理要求越来越高的现在,Spark Streaming受到Flink激烈的竞争。
|
|
|
|
(3)硬件的变化和硬件能力的充分挖掘。大数据技术体系本质是数据管理系统的一种,受到底层硬件和上层应用的影响。当前硬件的芯片的发展从CPU的单核到多核演变转化为向GPU、FPGA、ASIC等多种类型芯片共存演变。而存储中大量使用SSD来代替SATA盘,NVRAM有可能替换DRAM成为主存。大数据技术势必需要拥抱这些变化,充分兼容和利用这些硬件的特性。
|
|
|
|
(4)SQL的支持。从Hive诞生起,Hadoop生态就在积极向SQL靠拢,主要从兼容标准SQL语法和性能等角度来不断优化,层出不穷的SQL on Hadoop技术参考了很多传统数据库的技术。而Greenplum等MPP数据库技术本身从数据库继承而来,在支持SQL和数据精细化操作方面有很大的优势。
|
|
|
|
(5)深度学习的支持。深度学习框架出现后,和大数据的计算平台形成了新的竞争局面,以Spark为首的计算平台开始积极探索如何支持深度学习能力,TensorFlow on Spark等解决方案的出现实现了TensorFlow与Spark的无缝连接,更好地解决了两者数据传递的问题。
|
|
|
|
|
|
随着移动互联网的快速发展,智能终端数量呈现爆炸式增长,银行和支付机构传统的柜台式交易模式逐渐被终端直接交易模式替代。以金融场景为例,移动支付以及普惠金融的快速发展,为银行业、支付机构和金融监管机构带来了海量高频的线上小额资金支付行为,生产业务系统面临大规模并发事务处理要求的挑战。
|
|
|
|
传统事务技术模式以集中式数据库的单点架构为主,通过提高单机的性能上限适应业务的扩展。而随着摩尔定律的失效(底层硬件的变化),单机性能扩展的模式走到了尽头,而数据交易规模的急速增长(上层应用的变化)要求数据库系统具备大规模并发事务处理的能力。大数据分析系统经过10多年的实践,积累了丰富的分布式架构的经验,Paxos、Raft等一致性协议的诞生为事务系统的分布式铺平了道路。新一代分布式数据库技术在这些因素的推动下应运而生。
|
|
|
|
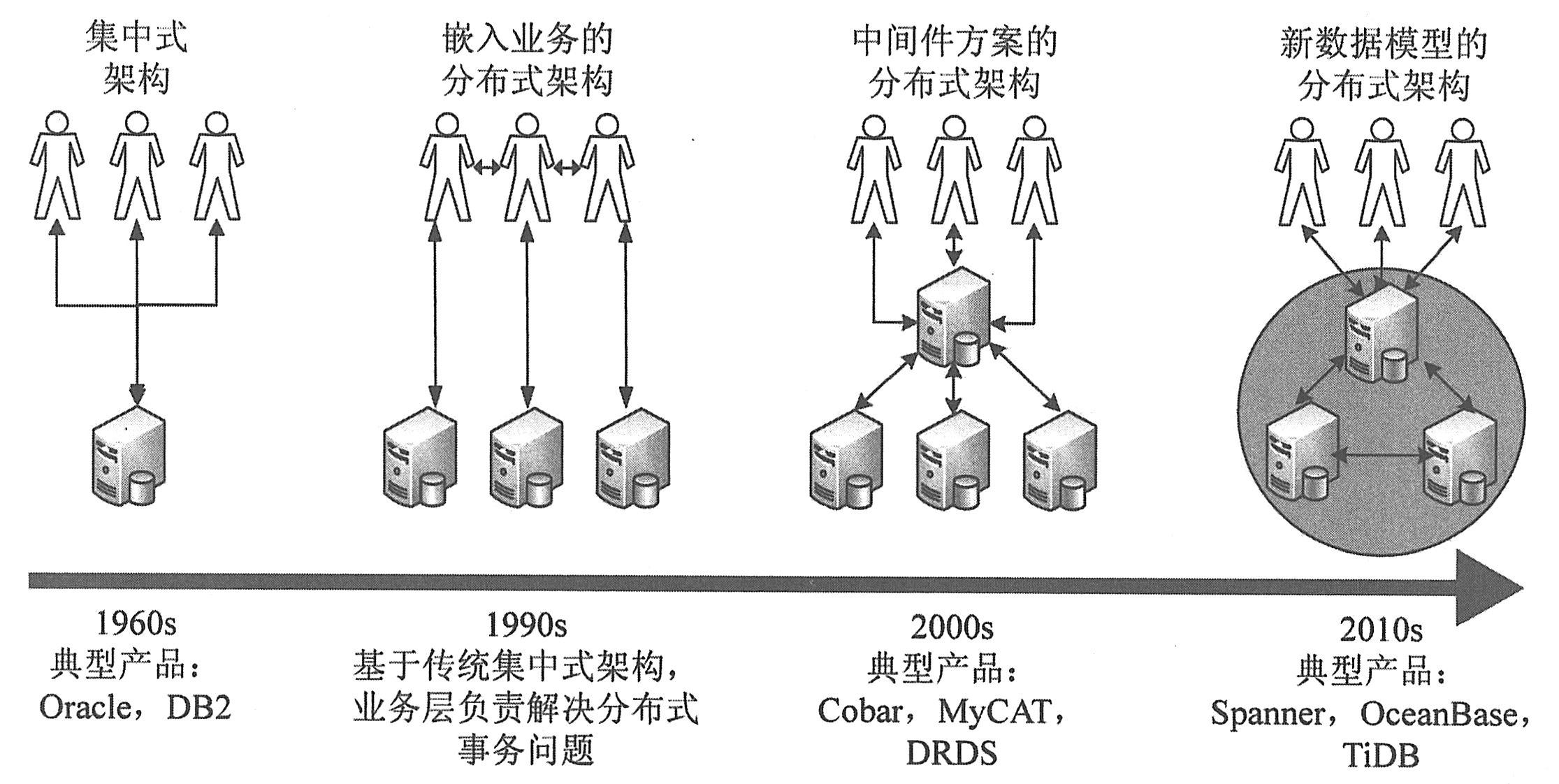
如下图所示,经过多年发展,当前分布式事务架构正处在快速演进的阶段,综合学术界以及产业界工作成果,目前主要分为三类:
|
|
|
|
|
|
|
|
(1)基于原有单机事务处理关系数据库的分布式架构改造:利用原有单机事务处理数据库的成熟度优势,通过在独立应用层面建立起数据分片和数据路由的规则,建立起一套复合型的分布式事务处理数据库的架构。
|
|
|
|
(2)基于新的分布式事务数据库的工程设计思路的突破。通过全新设计关系数据库的核心存储和计算层,将分布式计算和分布式存储的设计思路和架构直接植入数据库的引擎设计中,提供对业务透明和非侵入式的数据管理和操作/处理能力。
|
|
|
|
(3)基于新的分布式关系数据模型理论的突破。通过设计全新的分布式关系数据管理模型,从数据组织和管理的最核心理论层面,构造出完全不同于传统单机事务数据库的架构,从数据库的数据模型的根源上解决分布式关系数据库的架构。
|
|
|
|
分布式事务数据库进入到各行各业面临诸多挑战,其一是多种技术路线,目前没有统一的定义和认识;其二是除了互联网公司有大规模使用外,其他行业的实践刚刚开始,需求较为模糊,采购、使用、运维的过程缺少可供参考的经验,需要较长时间的摸索;其三是缺少可行的评价指标、测试方法和测试工具来全方位比较当前的产品,规范市场,促进产品的进步。故应用上述技术进行交易类业务进行服务时,应充分考虑“可持续发展”“透明开放”“代价可控”三原则,遵循“知识传递先行”“测试评估体系建立”“实施阶段规划”三步骤,并认识到“应用过度适配和改造”“可用性管理策略不更新”“外围设施不匹配”三个误区。
|
|
|
|
大数据事务处理类技术体系的快速演进正在消除日益增长的数字社会需求同旧式的信息架构缺陷,未来人类行为方式、经济格局以及商业模式将会随大数据事务处理类技术体系的成熟而发生重大变革。
|
|
|
|
|
|
数据流通是释放数据价值的关键环节。然而,数据流通也伴随着权属、质量、合规性、安全性等诸多问题,这些问题成为了制约数据流通的瓶颈。为了解决这些问题,大数据从业者从诸多方面进行了探索。目前来看,从技术角度的探索是卓有成效和富有潜力的。
|
|
|
|
从概念上讲,基础的数据流通只存在数据供方和数据需方这两类角色,数据从供方通过一定手段传递给需方。然而,由于数据权属和安全的需要,不能简单地将数据直接进行传送。数据流通的过程中需要完成数据确权、控制信息计算、个性化安全加密等一系列信息生产和再造,形成闭合环路。
|
|
|
|
安全多方计算和区块链是近年来常用的两种技术框架。由于创造价值的往往是对数据进行的加工分析等运算的结果而非数据本身,因此对数据需方来说,本身不触碰数据、但可以完成对数据的加工分析操作,也是可以接受的。安全多方计算这个技术框架就实现了这一点。其围绕数据安全计算,通过独特的分布式计算技术和密码技术,有区分地、定制化地提供安全性服务,使得各参与方在无需对外提供原始数据的前提下实现了对与其数据有关的函数的计算,解决了一组互不信任的参与方之间保护隐私的协同计算问题。区块链技术中多个计算节点共同参与和记录,相互验证信息有效性,既进行了数据信息防伪,又提供了数据流通的可追溯路径。业务平台中授权和业务流程的解耦对数据流通中的溯源、数据交易、智能合约的引入有了实质性的进展。
|
|
|