|
|
|
|
|
|
|
|
|
|
|
存储布局是确定了如何访问磁盘,以及如何直接影响性能,主要分为基于行的存储布局、列存储布局、带有局部性群组的列存储布局、LSM-Tree四种。
|
|
|
|
|
|
这里首先介绍行存储和列存储。两者之间的主要区别在于,行存储将每条记录的所有字段的数据聚合存储,而列存储将所有记录中相同字段的数据聚合存储。举个简单的例子,见下表。
|
|
|
|
|
|
|
|
对于传统的行存储,表格中的每一行(每一条记录)在磁盘上是紧密排列的,如下所示:
|
|
|
|
|
|
|
|
|
|
而列存储,将表格中每一列的数据项放在了一起,如下所示:
|
|
|
|
|
|
|
|
|
|
|
|
总结来说,行存储主要适用于OLTP,或者更新操作,尤其是插入、删除操作频繁的场合;而列存储主要适用于OLAP,数据仓库,数据挖掘等查询密集型应用。
|
|
|
|
|
|
.每个字段的数据聚集存储,在查询只需要少数几个字段的时候能大大减少读取的数据量。而查询密集型应用的特点之一就是查询一般只关心少数几个字段,而行存储每次必须读取整条记录。
|
|
|
|
.既然一个字段的数据聚集存储,那就更容易为这种聚集存储设计更好的压缩/解压算法。
|
|
|
|
|
|
带有局部性群组的列存储,它和列存储很相似,但是增加了局部性群组的特色。
|
|
|
|
首先这里需要介绍一下局部性群组,它是在Google的关于Bigtable的论文中第一次提到的。它是指根据需要将原来不存储在一起的数据,以列族为单位存储至单独的字表中。如用户对网站排名、语言等分析信息感兴趣,那么可以将这些列族放在单独的子表,减少无用信息读取,改善存取效率。
|
|
|
|
而对于上面的例子,带有局部性群组的列存储就可以如下所示:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
LSM-Tree(Log Structured Merge Trees,日志结构合并树)与前面介绍的存储结构有所不同,前面的存储结构在描述如何序列化逻辑数据结构,而LSM-Tree描述的则是为了满足高效、高性能、安全地读写的要求,如何有效地利用内存和磁盘存储。LSM-Tree的观点是由Patrick O'Neil在1996年率先提出的。LSM-Tree算法思想主要用于解决日志记录索引的问题,这种应用的特点是数据量大、写速率高(2000条/秒),又要建立有效的索引来查找日志中的特定条目。Patrick O'Neil的做法是,在内存里维护一个相同的B树,当内存中的B树达到阈值时,批量进行滚动合并。
|
|
|
|
而LSM-Tree的典型例子就是Google的Bigtable。下面将结合Bigtable具体解释LSM-Tree的工作原理。
|
|
|
|
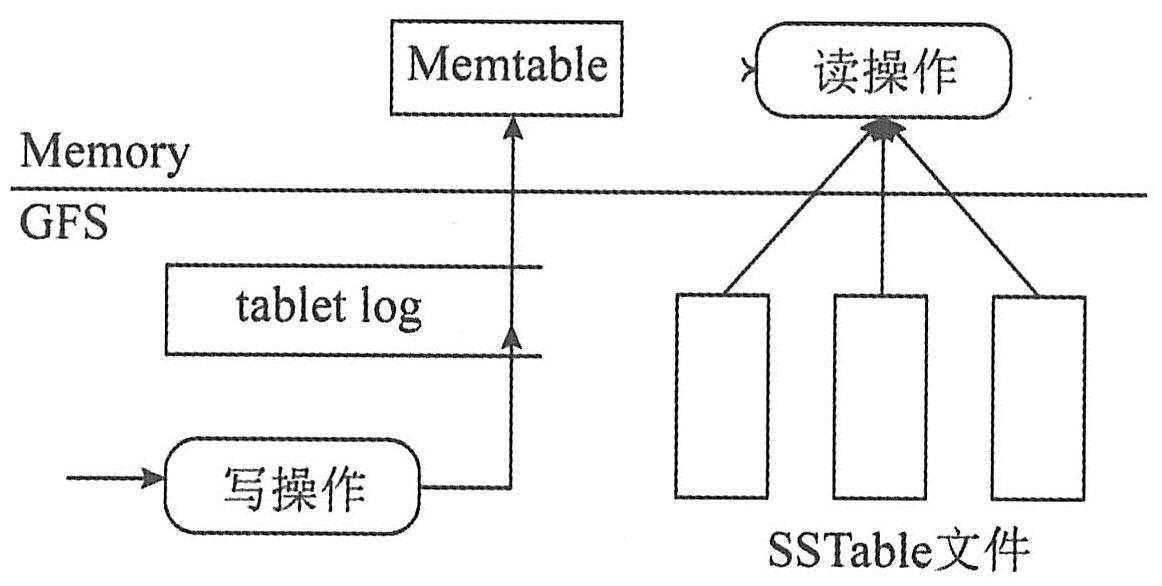
当初Google设计Bigtable的原因有两个,一是Google需要存储的数据种类繁多,二是海量的服务请求。Google的需求是:数据存储可靠性、高速数据检索与读取、存储海量的记录、可以保持记录的多个版本。Bigtable中的合并/转储引擎结构图如下图所示。
|
|
|
|
|
|
|
|
用户的操作首先写入到MemTable中,当内存中的MemTable达到一定的大小,需要将MemTable转储到持久化存储中生成SSTable文件。这里需要注意,除了最早写入的SSTable存放了最终结果以外,其他的SSTable和MemTable存放的都是用户的更新操作,比如对指定行的某个列加一操作,删除某一行等。每次读取或者扫描操作都需要对所有的SSTable及MemTable按照时间从老到新进行一次多路归并,从而获取最终结果。
|
|
|
|
如果要确保数据不能丢失,为了应对服务器遇到不可抵抗外力因素造成宕机的情况,LSM有两次持久化过程:一次是log,以append形式对所有的update操作先进行日志记录,一旦出现意外情况,即可以恢复log中的内容到MemTable;第二次是swap,在MemTable达到阈值的时候直接转储到磁盘上形成新的SSTable。
|
|
|