|
|
|
|
|
|
|
|
|
|
|
封锁对象的大小称为封锁的粒度。封锁的对象可以是逻辑单元(如属性、元组、关系、索引项、整个索引直至整个数据库),也可以是物理单元(如数据页或索引页)。
|
|
|
|
封锁粒度与系统的并发度和并发控制的开销密切相关。封锁的粒度越大,并发度越小,但系统开销也就越小;封锁的粒度越小,并发度越高,但系统开销也就越大。
|
|
|
|
选择封锁粒度时必须同时考虑封锁对象和并发度两个因素,对系统开销与并发度进行权衡,以求得最优的效果。一般说来,需要处理大量元组的用户事务可以以关系为封锁对象;需要处理多个关系的大量元组的用户事务可以以数据库为封锁对象;而对于一个处理少量元组的用户事务,可以以元组为封锁对象以提高并发度。
|
|
|
|
多粒度(multiple granularity)机制是指通过允许各种大小的数据项并定义数据粒度的层次结构,其中小粒度数据项嵌套在大粒度数据项中。对此,可以构造一个粒度层次图,粒度层次图像一棵倒置的树,故也称多粒度树。
|
|
|
|
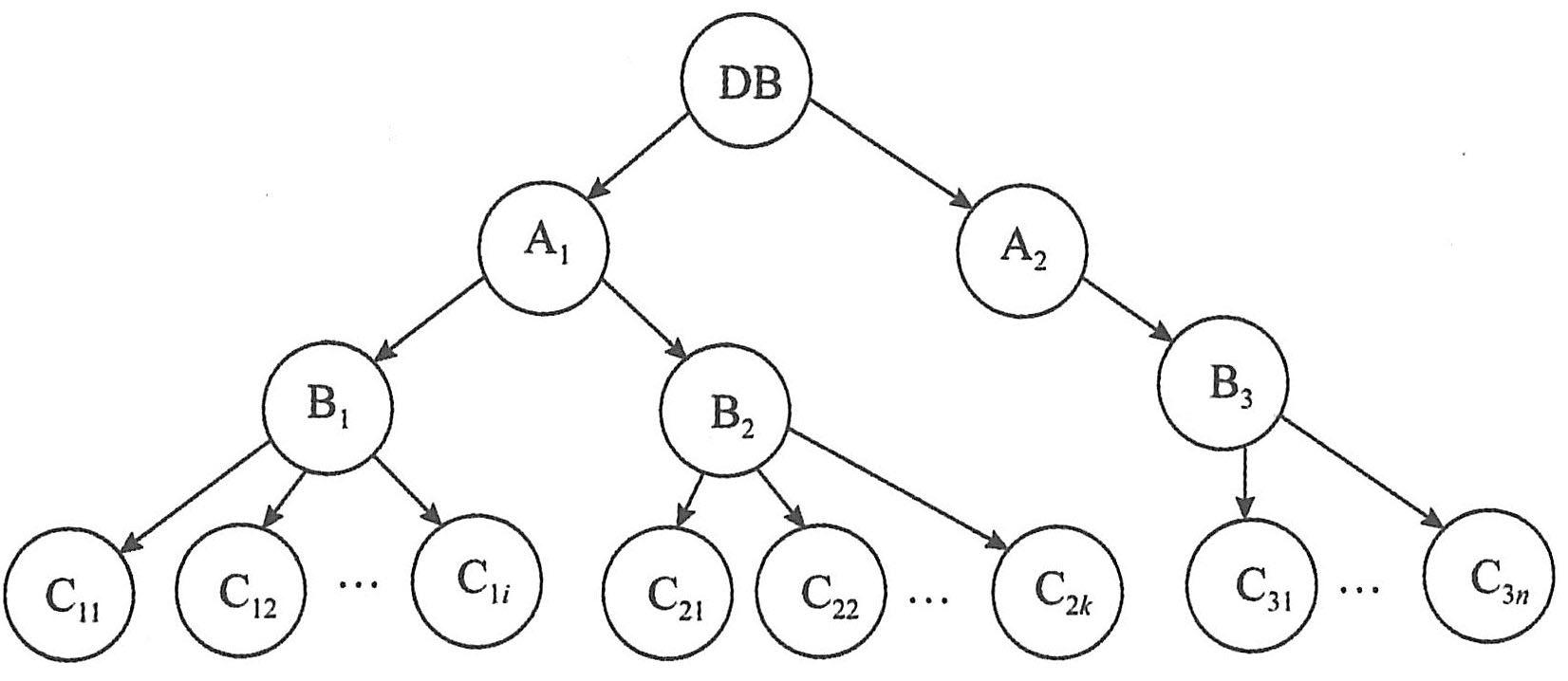
例如,考虑一个由四层结点构成的多粒度树,该粒度树包括:根结点、区域类型结点、文件类型结点和记录类型结点,如下图所示。
|
|
|
|
|
|
|
|
最高层是根结点,表示整个数据库,其下的结点是区域类型结点,而数据库是由这些区域组成。
|
|
|
|
第二层是区域类型结点,每个区域类型结点又以文件类型结点作为其子结点,每个区域是由这些文件类结点组成,任何文件都不能处于一个以上的区域中。
|
|
|
|
第三层是文件类型结点,文件类型结点下的是记录类型结点,文件是由作为其子结点的记录组成。
|
|
|
|
|
|
粒度树中的每个结点都可以单独加锁(共享锁或排它锁)。当一个事务对结点加锁时,那么该事务也可以同样类型的锁隐含地封锁该结点的全部后代结点。
|
|
|
|
例如,假设事务T1显式地对上图中的文件结点B2加排它锁,若事务T2要求封锁文件结点B2的后代结点C23,请分析加锁是否成功?
|
|
|
|
分析:由于事务T1显式地对文件结点B2加排它锁,则意味着事务T1隐含地对B2的后代结点C21,C22,…,C2k,加排它锁。当T2要求封锁文件结点B2的后代结点C23时,由于T1已显式地对结点B2加排它锁,意味着结点C23也加了排它锁。当事务T2发出封锁C23命令时,由于C23并没有显式加锁,系统必须从根结点到结点C23开始搜索,如果发现该路径上的某个结点的锁与要加锁的锁类型不相容,T2就必须延迟(等待)。
|
|
|
|
采用多粒度树的好处是:减少对后代结点加锁的系统代价。从上例可见,由于事务T1显式地对文件结点B2加排它锁,这样事务T1不用挨个对其后代记录结点C21,C22,…,C2k,加排它锁,从而减少了事务T1对记录结点C21,C22,…,C2k加锁的系统代价。
|
|
|