|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
在白盒测试中,可以使用各种测试方法的综合策略如下所示。
|
|
|
|
|
|
. 测试中可采取先静态后动态的组合方式:先进行静态结构分析、代码检查和静态质量度量,再进行覆盖率测试。
|
|
|
|
. 利用静态分析的结果作为引导,通过代码检查和动态测试的方式对静态分析结果进行进一步的确认,使测试工作更为有效。
|
|
|
|
. 覆盖率测试是白盒测试的重点,一般可使用基本路径测试法达到语句覆盖标准;对于软件的重点模块,应使用多种覆盖率标准衡量代码的覆盖率;具体的测试用例数计算与覆盖准则参见本书后面的内容。
|
|
|
|
. 在不同的测试阶段,测试的侧重点不同:在单元测试阶段,以代码检查、逻辑覆盖为主;在集成测试阶段,需要增加静态结构分析、静态质量度量;在系统测试阶段,应根据黑盒测试的结果,采取相应的白盒测试。
|
|
|
|
|
|
为实现测试的逻辑覆盖,必须设计足够多的测试用例,并使用这些测试用例执行被测程序,实施测试。我们关心的是,对某个具体程序来说,至少要设计多少测试用例。这里提供一种估算最少测试用例数的方法。
|
|
|
|
我们知道,结构化程序是由3种基本控制结构组成的。这3种基本控制结构就是:
|
|
|
|
|
|
|
|
|
|
为了把问题化简,避免出现测试用例极多的组合爆炸,把构成循环操作的重复型结构用选择结构代替。也就是说,并不指望测试循环体所有的重复执行,而是只对循环体检验一次。这样,任一循环便改造成进入循环体或不进入循环体的分支操作了。
|
|
|
|
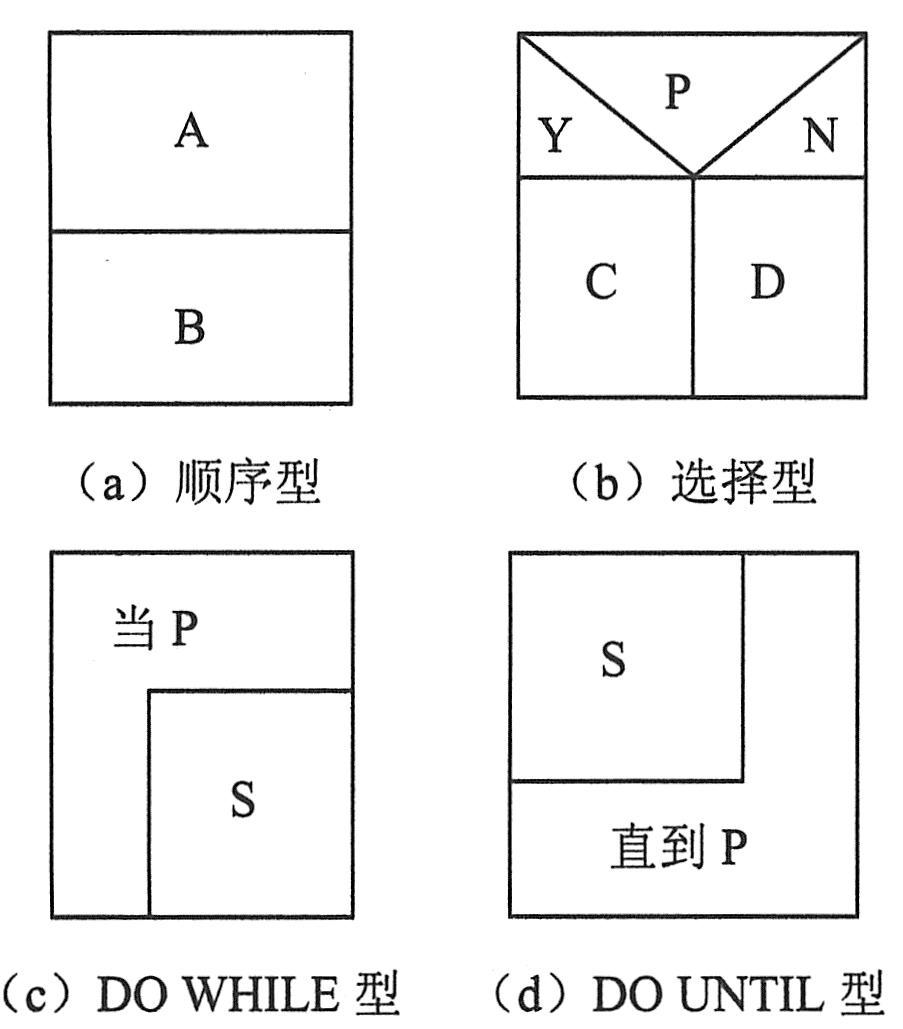
如下图所示给出了类似于流程图的N-S图表示的基本控制结构(图中A、B、C、D、S均表示要执行的操作,P是可取真假值的谓词,Y表真值,N表假值)。其中下图(c)和下图(d)两种重复型结构代表了两种循环。在作了如上简化循环的假设以后,对于一般的程序控制流,我们只考虑选择型结构。事实上它已经能体现顺序型和重复型结构了。
|
|
|
|
|
|
|
|
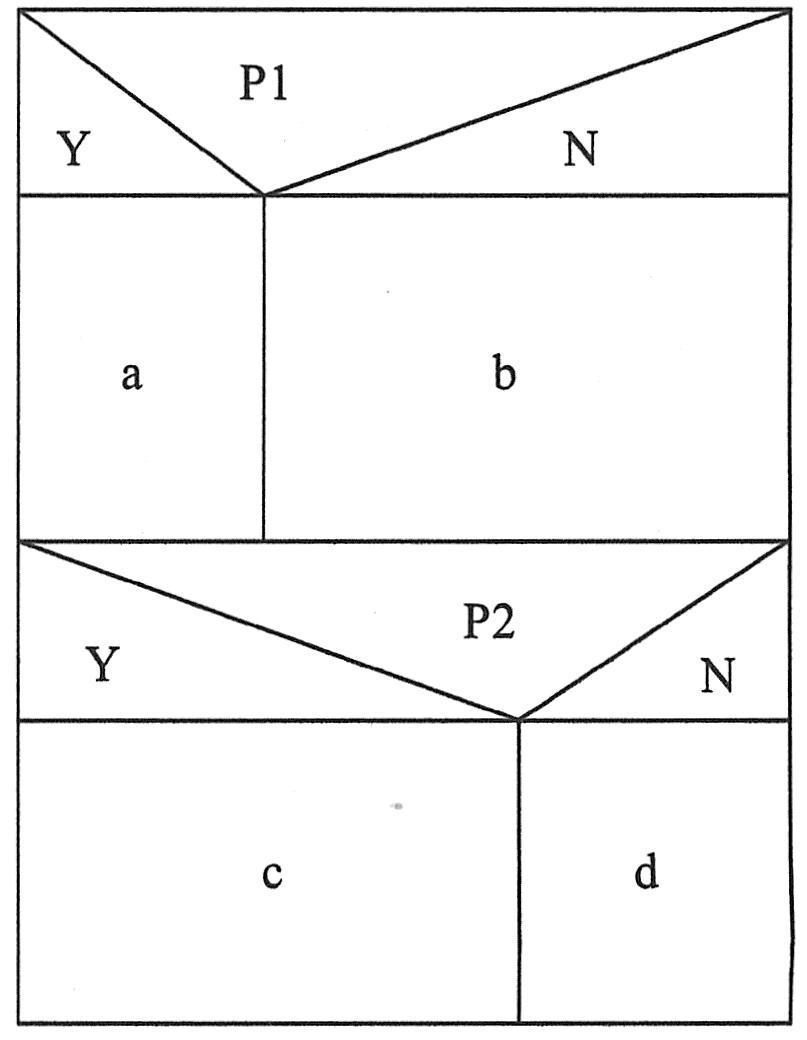
例如,如下图所示表达了两个顺序执行的分支结构。两个分支谓词P1和P2取不同值时,将分别执行a或b及c或d操作。显然,要测试这个小程序,需要至少提供4个测试用例才能做到逻辑覆盖。使得ac、ad、bc及bd操作均得到检验。其实,这里的4是图中第1个分支谓词引出的两个操作,及第2个分支谓词引出的两个操作组合起来而得到的,即2×2=4。并且,这里的2是由于两个并列的操作,1+1=2而得到的。
|
|
|
|
|
|
|
|
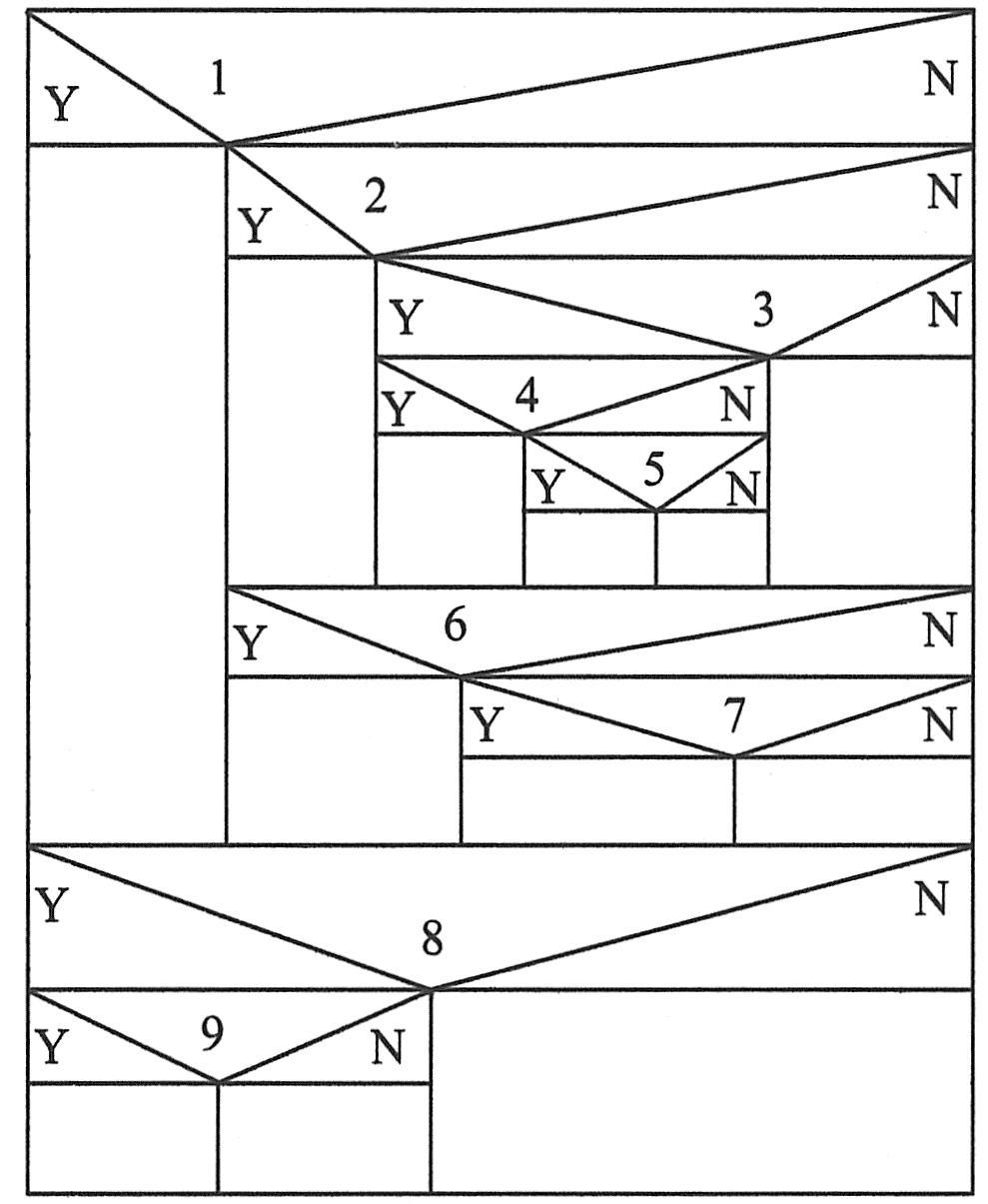
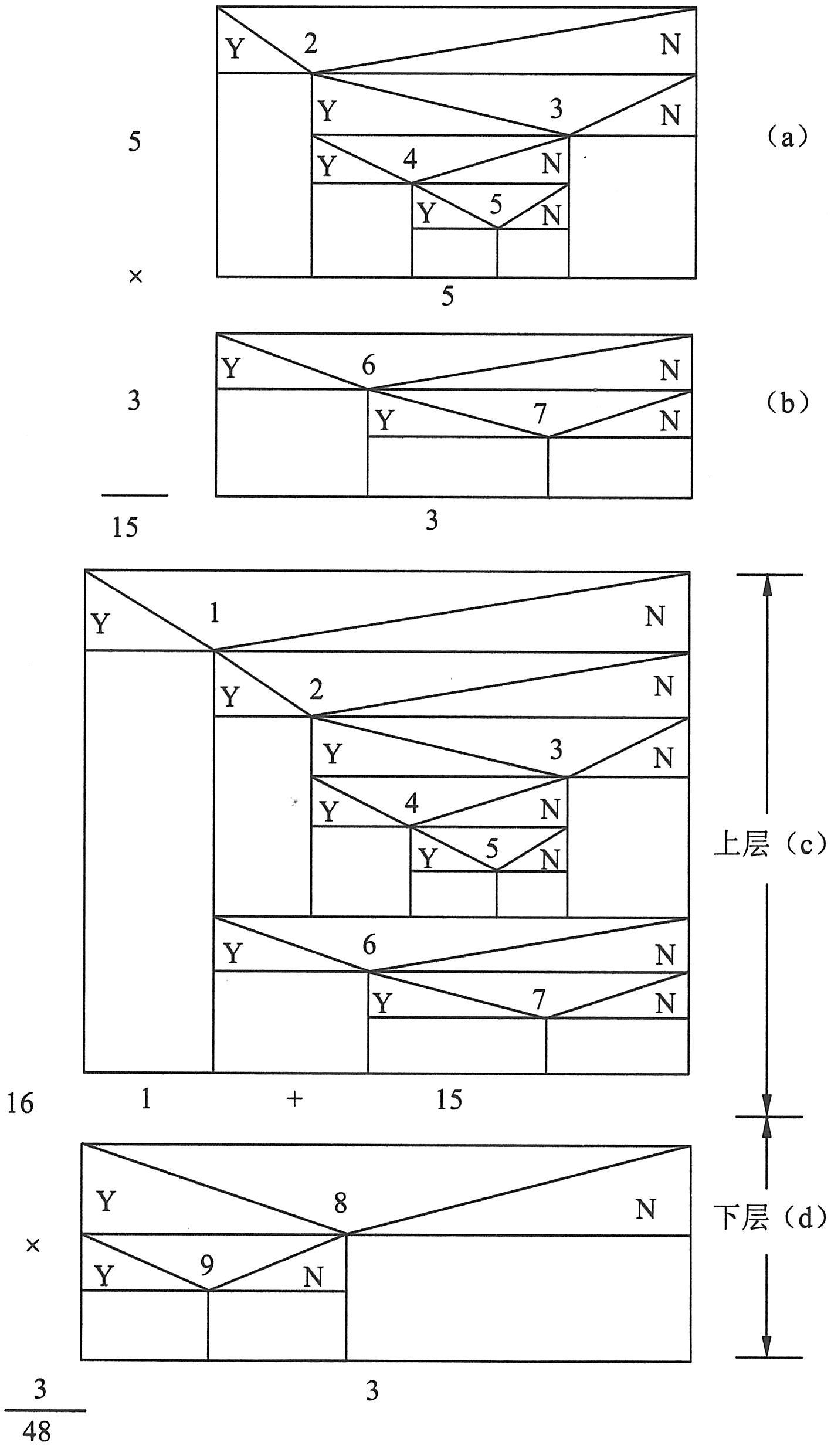
对于一般的、更为复杂的问题,估算最少测试用例数的原则也是同样的。现以下图所示的程序为例。该程序中共有9个分支谓词,尽管这些分支结构交错起来似乎十分复杂,很难一眼看出应至少需要多少个测试用例,但如果仍用上面的方法,也是很容易解决的。我们注意到该图可分上下两层:分支谓词1的操作域是上层,分支谓词8的操作域是下层。这两层正像前面简单例中的P1和P2的关系一样。只要分别得到两层的测试用例个数,再将其相乘,即得总的测试用例数。这里需要首先考虑较为复杂的上层结构。谓词1不满足时要做的操作又可进一步分解为两层,这就是如下图所示中的图(a)和(b)。它们所需测试用例个数分别为1+1+1+1+1=5和1+1+1=3。因而两层组合,得到5×3=15。于是整个程序结构上层所需测试用例数为1+15=16,而下层十分显然为3。故最后得到整个程序所需测试用例数至少为16×3=48。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
前面介绍的逻辑覆盖,其出发点似乎是合理的。所谓“覆盖”,就是想要做到全面而无遗漏。但事实表明,它并不能真的做到无遗漏。甚至对于像前面提到的,将程序段:
|
|
|
|
|
|
|
|
|
|
|
|
我们分析出现这一情况的原因在于,错误区域仅仅在I=0这个点上,即仅当I取0时,测试才能发现错误。它的确是在我们力图通过全面覆盖来查找错误的测试的“网上”钻了空子,并且恰恰在容易发生问题的条件判断那里未被发现。面对这类情况,我们应该从中吸取的教训是测试工作要有重点,要多针对容易发生问题的地方设计测试用例。
|
|
|
|
K.A.Foster从测试工作实践的教训出发,吸收了计算机硬件的测试原理,提出了一种经验型的测试覆盖准则,较好地解决了上述问题。
|
|
|
|
Foster的经验型覆盖准则是从硬件的早期测试方法中得到启发的。我们知道,硬件测试中,对每一个门电路的输入、输出测试都是有额定标准的。通常,电路中一个门的错误常常是“输出总是0”,或是“输出总是1”。与硬件测试中的这一情况类似,我们常常要重视程序中谓词的取值,但实际上它可能比硬件测试更加复杂。Foster通过大量的实验确定了程序中谓词最容易出错的部分,得出了一套错误敏感测试用例分析ESTCA(Error Sensitive Test Cases Analysis)规则。事实上,规则十分简单。
|
|
|
|
. [规则1]对于A rel B(rel可以是<,=和>)型的分支谓词,应适当地选择A与B的值,使得测试执行到该分支语句时,AB的情况分别出现一次。
|
|
|
|
. [规则2]对于A rel1 C(rel1可以是“>”或是“<”,A是变量,C是常量)型的分支谓词,当rel1为“<”时,应适当地选择A的值,使:
|
|
|
|
|
|
(M是距C最小的容器容许的正数,若A和C均为整型时,M=1)。同样,当rel1为“>”时,应适当地选择A,使:
|
|
|
|
|
|
. [规则3]对外部输入变量赋值,使其在每一测试用例中均有不同的值和符号,并与同一组测试用例中其他变量的值和符号不一致。
|
|
|
|
显然,上述规则1是为了检测rel的错误,规则2是为了检测“差1”之类的错误(如本应是“IF A>1”而错成“IF A>0”),而规则3则是为了检测程序语句中的错误(如应引用一变量而错成引用一常量)。
|
|
|
|
上述三个规则并不完备,但在普通程序的测试中确是有效的。原因在于规则本身针对着程序编写人员容易发生的错误,或是围绕着发生错误的频繁区域,从而提高了发现错误的命中率。
|
|
|
|
根据这里提供的规则来检验上述小程序段错误。应用规则1,对它测试时,应选择I的值为0,使I=0的情况出现一次。这样一来就立即找出了隐藏的错误。
|
|
|
|
当然,ESTCA规则也有很多缺陷。一方面是,有时不容易找到输入数据使得规则所指的变量值满足要求。另一方面是,仍有很多缺陷发现不了。对于查找错误的广度问题在变异测试中得到了较好的解决。
|
|
|
|
|
|
Woodward等人曾经指出结构覆盖的一些准则,如分支覆盖或路径覆盖,都不足以保证测试数据的有效性。为此,他们提出了一种层次LCSAJ覆盖准则。
|
|
|
|
LCSAJ(Linear Code Sequence and Jump)的意思是线性代码序列与跳转。一个LCSAJ是一组顺序执行的代码,以控制流跳转为其结束点。它不同于判断—判断路径。判断—判断路径是根据程序有向图决定的。一个判断—判断路径是指两个判断之间的路径,但其中不再有判断。程序的入口、出口和分支结点都可以是判断点。而LCSAJ的起点是根据程序本身决定的。它的起点是程序第一行或转移语句的入口点,或是控制流可以跳达的点。几个首尾相接,且第一个LCSAJ起点为程序起点,最后一个LCSAJ终点为程序终点的LCSAJ串就组成了程序的一条路径。一条程序路径可能是由两个、三个或多个LCSAJ组成的。基于LCSAJ与路径的这一关系,Woodward提出了LCSAJ覆盖准则。这是一个分层的覆盖准则,具体如下。
|
|
|
|
|
|
|
|
. [第三层]:LCSAJ覆盖。即程序中的每一个LCSAJ都至少在测试中经历过一次。
|
|
|
|
. [第四层]:两两LCSAJ覆盖。即程序中每两个首尾相连的LCSAJ组合起来在测试中都要经历一次。
|
|
|
|
|
|
. [第n+2层]:每n个首尾相连的LCSAJ组合在测试中都要经历一次。
|
|
|
|
|
|
在实施测试时,若要实现上述的Woodward层次LCSAJ覆盖,需要产生被测程序的所有LCSAJ。
|
|
|