| HBase,即Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
|
|
|
| HBase同Hypertable一样,是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable利用Chubby作为协同服务,HBase利用Zookeeper作为对应。
|
|
|
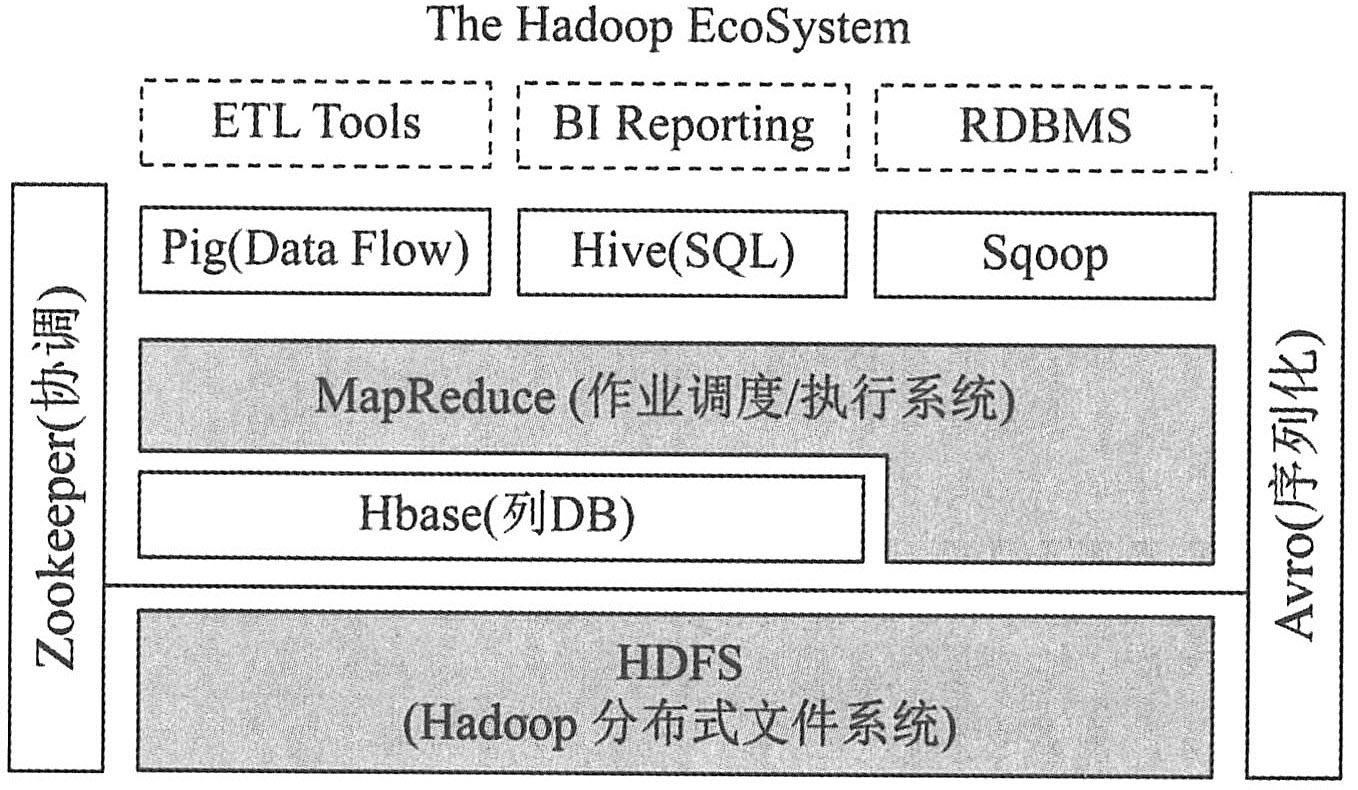
| 下图描述了Hadoop EcoSystem中的各层系统,其中HBase位于结构化存储层。
|
|
|
|
|
|
|
| HDFS为HBase提供了高可靠性的底层存储支持,Hadoop MapReduce为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定服务和failover机制。另外,Pig和Hive为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变得非常简单。Sqoop则为HBase提供了方便的RDBMS数据导入功能,使得传统数据库数据向HBase中迁移变得非常方便。
|
|
|
| 表是Hbase中数据的逻辑组织方式,从用户视角,HBase表的逻辑模型如下表所示。HBase中一个表有若干行,每一行有多个列族,每个列族中包含多个列,列中的值有多个版本。下表展示的是HBase中员工信息表,有三行记录和两个列族,行键分别是7001、7002和7003,两个列族分别是Info和Salary,每一族中含有若干列,如列族Info中包含姓名、性别和年龄三列,列族Salary中包括一月、二月和三月三列。在Hbase中,列不是固定的表结构,在创建表时,不用预先定义列名,可以在插入数据时临时创建。
|
|
|
|
|
|
|
| 从上表的逻辑模型来看,HBase表与关系型数据库中的表结构之间似乎没有太大差异,只不过多了列族概念。但实际上是有很大差别的,关系型数据库中表的结构需要预先定义,如列名及其数据类型和值域等内容。如果需要添加新列,则需要修改表结构,这会对已有的数据产生很大影响。同时,关系型数据库中的表为每个列预留了存储空间,即上表中的空白单元格数据在关系型数据库中以“Null”值占用存储空间。因此,对稀疏数据来说,关系型数据库表中就会产生很多“Null”值,消耗大量的存储空间。
|
|
|
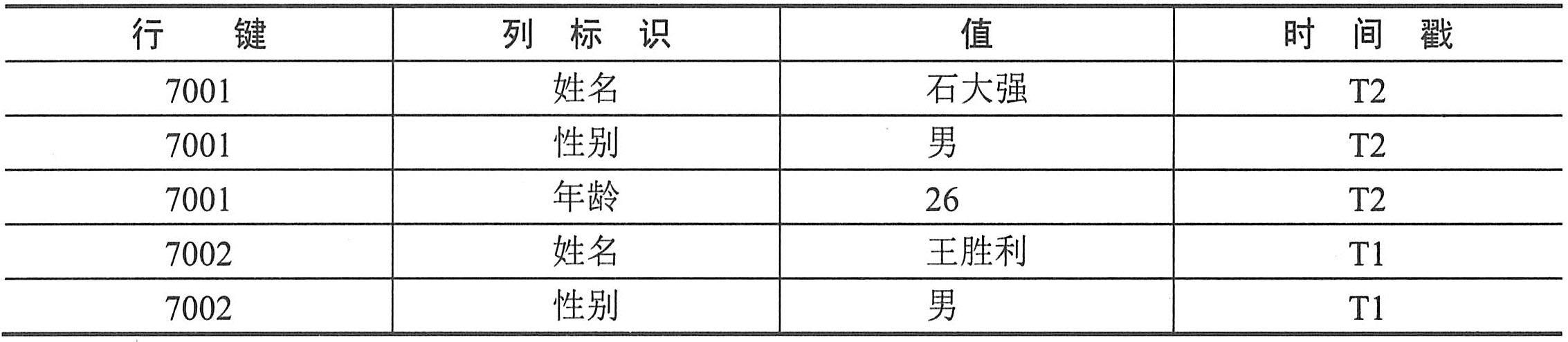
| 在HBase中,如上表的空白单元格在物理上是不占用存储空间的,即不会存储空白的键值对。因此,若一个请求为获取行键为7002在T1时间的Info:年龄的值时,其结果为Null。类似地,若一个请求为获取行键为7003在T2时间的Salary:二月的值时,其结果也为空。与面向行存储的关系型数据库不同,HBase是面向列存储的,且在实际的物理存储中,列族是分开存储的,即上表中的员工信息表将被存储为Info和Salary两个部分。且空白单元格是没有被存储下来的。下表展示了Info这个列族的实际物理存储方式,列族Salary的存储与之类似。从下表可以看出“Null”是没有被存储下来的。
|
|
|
|
|
|
|