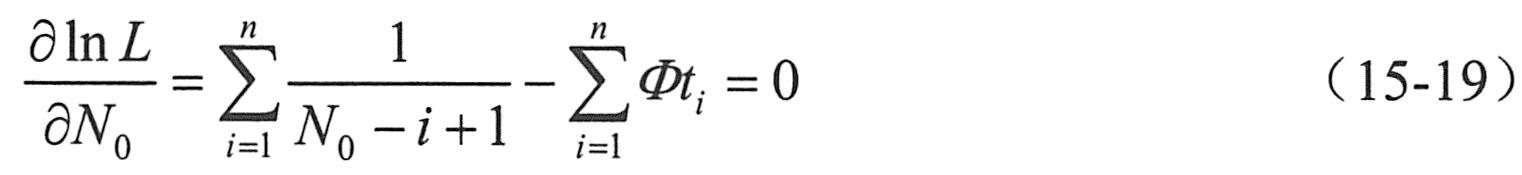|
|
| 在讲到软件可靠性评估的时候,我们不得不提到软件可靠性模型。软件可靠性模型(software reliability model)是指为预计或估算软件的可靠性所建立的可靠性框图和数学模型。建立可靠性模型是为了将复杂系统的可靠性逐级分解为简单系统的可靠性,以便于定量预计、分配、估算和评价复杂系统的可靠性。
|
|
|
| 为了构建软件的可靠性模型,我们首先要来分析一下影响软件可靠性的因素。影响软件可靠性的因素是纷杂而众多的,甚至包括技术以外的许多因素。首先我们必须只考虑影响软件可靠性的主要因素:缺陷的引入、发现和清除。缺陷的引入主要取决于软件产品的特性和软件的开发过程特性,软件产品的特性指软件本身的性质,开发过程特性包括开发技术、开发工具、开发人员的水平、需求的变化频度等。缺陷的发现依靠用户对软件的操作方式、运行环境等,也就是运行剖面。缺陷的清除依赖于失效的发现和修复活动及可靠性方面的投入。
|
|
|
|
|
| . 运行剖面(环境)。软件可靠性的定义是相对运行环境而言的,一样的软件在不同的运行剖面下,其可靠性的表现是不一样的。
|
|
|
| . 软件规模。也就是软件的大小,一个只有数十行代码的软件和几千万行代码的软件是不能相提并论的。
|
|
|
| . 软件内部结构。结构对软件可靠性的影响主要取决于软件结构的复杂程度,一般来说,内部结构越复杂的软件,所包含的软件缺陷数就可能越多。
|
|
|
| . 软件的开发方法和开发环境。软件工程表明,软件的开发方法对软件的可靠性有显著影响,例如,与非结构方法相比,结构化方法可以明显减少软件的缺陷数。
|
|
|
| . 软件的可靠性投入。软件在生命周期中可靠性的投入包括开发者在可靠性设计、可靠性管理、可靠性测试、可靠性评价等方面投入的人力、资金、资源和时间等。经验表明,在早期重视软件可靠性并采取措施开发出来的软件,可靠性有明显的提高。
|
|
|
| 总之,有许许多多的因素影响着软件的可靠性,有些至今也无法确定它们与软件可靠性之间的定量关系,甚至定性关系也不甚清楚。
|
|
|
|
|
| 一个软件可靠性模型通常(但不是绝对)由以下几部分组成。
|
|
|
| . 模型假设。模型是实际情况的简化或规范化,总要包含若干假设,例如测试的选取代表实际运行剖面,不同软件失效独立发生等。
|
|
|
| . 性能度量。软件可靠性模型的输出量就是性能度量,如失效强度、残留缺陷数等。在软件可靠性模型中性能度量通常以数学表达式给出。
|
|
|
| . 参数估计方法。某些可靠性度量的实际值无法直接获得,例如残留缺陷数,这时需通过一定的方法估计参数的值,从而间接确定可靠性度量的值。当然,对于可直接获得实际值的可靠性度量,就无需参数估计了。
|
|
|
| . 数据要求。一个软件可靠性模型要求一定的输入数据,即软件可靠性数据。不同类型的软件可靠性模型可能要求不同类型的软件可靠性数据。
|
|
|
| 绝大多数的模型包含三个共同假设。这些假设至今主宰着软件可靠性建模的研究发展,人们尚未找到克服这些假设局限性的有效方法。
|
|
|
| . 代表性假设。此假设认为软件测试用例的选取代表软件实际的运行剖面,甚至认为测试用例是独立随机地选取。此假设实质上是指可以用测试产生的软件可靠性数据预测运行阶段的软件可靠性行为。
|
|
|
| . 独立性假设。此假设认为软件失效是独立发生于不同时刻,一个软件失效的发生不影响另一个软件失效的发生。例如在概率范畴,假设相邻软件失效间隔构成一组独立随机变量,或假设一定时间内软件失效次数构成一个独立增量过程。在模糊数学范畴,则相邻软件失效间隔构成一组不相关的模糊变量。
|
|
|
| . 相同性假设。此假设认为所有软件失效的后果(等级)相同,即建模过程只考虑软件失效的具体发生时刻,不区分软件的失效严重等级。
|
|
|
| 软件可靠性模型要描述失效过程对上一节所分析的因素的一般依赖形式。由于这些因素大多数在本质上是概率性的,并且表现与时间相关联,所以我们通过失效数据的概率分布和随机过程随时间的变化的特性来整体区分软件可靠性模型。
|
|
|
| 我们常常通过下面估计或预测的方法来确定模型的参数。估计是通过收集到的失效数据进行统计分析,利用一定的推导过程归纳出模型的参数;预测则是使用软件产品自身的属性和开发过程来确定模型的参数,这种方法可以在开始执行程序前完成。
|
|
|
| 确定了模型的参数后,就可以来表示失效过程的很多不同的特性。例如大多数模型都会对如下的内容进行解析表达。
|
|
|
|
|
|
|
|
|
|
|
| 在对将来的故障行为进行预测时,应保证模型参数的值不发生变化。如果在进行预测时发现引入了新的错误,或修复行为使新的故障不断发生,就应停止预测,并等足够多的故障出现后,再重新进行模型参数的估计。否则,这样的变化会因为增加问题的复杂程度而使模型的实用性降低。
|
|
|
| 一般来说,软件可靠性模型是以在固定不变的运行环境中运行的不变的程序作为估测实体的。这也就是说,程序的代码和运行剖面都不发生变化,但它们往往总要发生变化的,于是在这种情况之下,就应采取分段处理的方式来进行工作。因此,模型主要集中注意力于排错。但是,也有的模型具有能处理缓慢地引进错误情况的能力。
|
|
|
| 对于一个已发行并正在运行的程序,应暂缓安装新的功能和对下一次发行的版本的修复。如果能保持一个不变的运行剖面,则程序的故障密度将显示为一个常数。
|
|
|
| 一般来说,一个好的软件可靠性模型增加了关于开发项目的交流,并对了解软件开发过程提供了一个共同的工作基础。它也增加了管理的透明度和其他令人感兴趣的东西。即使在特殊的情况之下,通过模型作出的预测并不是很精确的话,上面的这些优点也仍然是明显而有价值的。
|
|
|
| 要建立一个有用的软件可靠性模型必须有坚实的理论研究工作、有关工具的建造和实际工作经验的积累。通常这些工作要许多人一年的工作量。相反,要应用一个好的软件可靠性模型,则要求以极少的项目资源就可以在实际工作中产生好的效益。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 一个有效的软件可靠性模型应尽可能地将上面所述的因素在软件可靠性建模时加以考虑,尽可能简明地反映出来。自1972年第一个软件可靠性分析模型发表的20多年来,见之于文献的软件可靠性统计分析模型将近百种。这些可靠性模型大致可分为如下10类。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 这类模型利用捕获-再捕获抽样技术估计程序中的错误数,在程序中预先有意“播种”一些设定的错误“种子”,然后根据测试出的原始错误数和发现的诱导错误的比例,来估计程序中残留的错误数。其优点是简便易行,缺点是诱导错误的“种子”与实际的原始错误之间的类比性估量困难。
|
|
|
|
|
|
|
| . Jelinski-Moranda的de-eutrophication模型;
|
|
|
| . Jelinski-Moranda的几何de-eutrophication模型;
|
|
|
|
|
|
|
|
|
|
|
|
|
| 这类模型用回归分析的方法研究软件复杂性、程序中的缺陷数、失效率、失效间隔时间,包括参数方法和非参数方法两种。
|
|
|
|
|
| 这类模型预测软件在检错过程中的可靠性改进,用增长函数来描述软件的改进过程。这类模型如下。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 程序结构模型是根据程序、子程序及其相互间的调用关系,形成一个可靠性分析网络。网络中的每一结点代表一个子程序或一个模块,网络中的每一有向弧代表模块间的程序执行顺序。假定各结点的可靠性是相互独立的,通过对每一个结点可靠性、结点间转换的可靠性和网络在结点间的转换概率,得出该持续程序的整体可靠性。这类模型如下。
|
|
|
|
|
|
|
|
|
| 这类模型选取软件输入域中的某些样本“点”运行程序,根据这些样本点在“实际”使用环境中的使用概率的测试运行时的成功/失效率,推断软件的使用可靠性。这类模型的重点(亦是难点)是输入域的概率分布的确定及对软件运行剖面的正确描述。这类模型如下。
|
|
|
|
|
|
|
|
|
| 这类模型的分析方法与上面的模型相似,先计算程序各逻辑路径的执行概率和程序中错误路径的执行概率,再综合出该软件的使用可靠性。Shooman分解模型属于此类。
|
|
|
|
|
| 非齐次泊松过程模型,即NHPP,是以软件测试过程中单位时间的失效次数为独立泊松随机变量,来预测在今后软件的某使用时间点的累计失效数。这类模型如下。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 这是利用失效率的试验前分布和当前的测试失效信息,来评估软件的可靠性。这是一类当软件可靠性工程师对软件的开发过程有充分的了解,软件的继承性比较好时具有良好效果的可靠性分析模型。这类模型如下。
|
|
|
|
|
|
|
| 另外,Musa和Okumoto依据模型的不同属性对可靠性模型进行以下分类。
|
|
|
| . 时间域:有两种,自然或日历时间与执行(CPU)时间;
|
|
|
| . 失效数类:取决于无限时间内发生的失效数是有限的还是无限的;
|
|
|
| . 失效数分布:相对于时间系统失效数的统计分布形式,主要的两类是泊松分布型和二项分布型;
|
|
|
| . 有限类:对有限失效数的类别适用,用时间表示的失效强度的函数形式;
|
|
|
| . 无限类:对无限失效数的类别适用,用经验期望失效数表示的失效强度的函数形式。
|
|
|
|
|
| 迄今已有数十种模型是根据上一小节中关于模型的分类方法进行的分类,下面我们将介绍Jelinski-Moranda模型的基本思想及其相关的历史背景。
|
|
|
| Jelinski-Moranda模型经常简称为JM模型,它是Z.Jelinski和P.Moranda于1972年提出的软件可靠性数学模型,是最具代表性的早期软件可靠性马尔可夫过程的数学模型。随后的许多工作,都是在它的基础上,对其中与软件开发实际不相适合的地方进行改进而提出来的,所以,JM模型是具有广泛影响的模型之一。
|
|
|
|
|
|
|
| . 软件系统中的初始错误个数为一个未知的常数,用N0表示。
|
|
|
| . 可靠性测试中发现的错误立即被完全排除,并且排除过程不引入新的错误,排除时间忽略不计。因此,每次排错之后,N0就要减去1。
|
|
|
| . 在任何一个失效间隔区间,软件系统的失效率与系统中剩余的错误个数成正比,比例常数用Φ表示。
|
|
|
| 其实,最初Jelinski和Moranda提出的模型假设只有最后一条,前面两个假设是后人根据使用过程中出现的问题归纳总结而来的。
|
|
|
|
|
| 根据假设,每发生1次失效,错误数都要减去1,如果用t1,t2,…,ti表示从0时刻开始的每次失效间隔时间,那第i-1次失效到第i次失效之间的失效率就是:
|
|
|
|
|
| 根据我们在可靠性定量描述一节的讨论,我们知道失效强度函数为:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 在可靠度函数表达式中含有两个未知参数Φ和N0,下面我们运用统计学中的最大似然法来对参数Φ和N0进行估算。
|
|
|
|
|
|
|
|
|
|
|
| 对公式(15-18)分别对N0和Φ求偏导,并令结果为零:
|
|
|
|
|
|
|
|
|
|
|
公式15-21中不含Φ,因而可以由测试收集的数据,计算出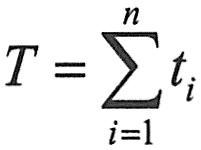 和 和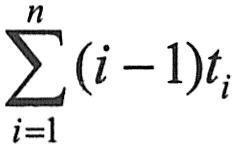 的值,将它们代入公式15-21中,即可先解出N0的估计值 的值,将它们代入公式15-21中,即可先解出N0的估计值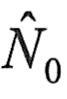 : :
|
|
|
|
|
|
|
|
|
|
|
|
|
代入N0的估计值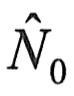 ,可解出Φ的估计值 ,可解出Φ的估计值 : :
|
|
|
|
|
| 需要说明的是,软件可靠性是一门正在发展中的分支学科,许多来源于硬件可靠性的理论在软件可靠性研究中并不适用,有关软件可靠性的模型并不成熟,并且应用范围也非常有限,软件可靠性的定量分析方法和数学模型要在实践中不断加以验证和修正,对于不同类型的软件,模型的假设、表示公式及应用方式也有很大的区别。
|
|
|