|
|
关系数据库设计的方法之一就是设计满足适当范式的模式,通常可以通过判断分解后的模式达到几范式来评价模式规范化的程度。范式有:1NF、2NF、3NF、BCNF、4NF和5NF,其中1NF级别最低。这几种范式之间 成立。 成立。
|
|
|
|
通过分解,可以将一个低一级范式的关系模式转换成若干个高一级范式的关系模式,这种过程叫作规范化。下面将给出各个范式的定义。
|
|
|
|
|
|
【定义7.10】若关系模式R的每一个分量是不可再分的数据项,则关系模式R属于第一范式。记为R∈1NF。
|
|
|
|
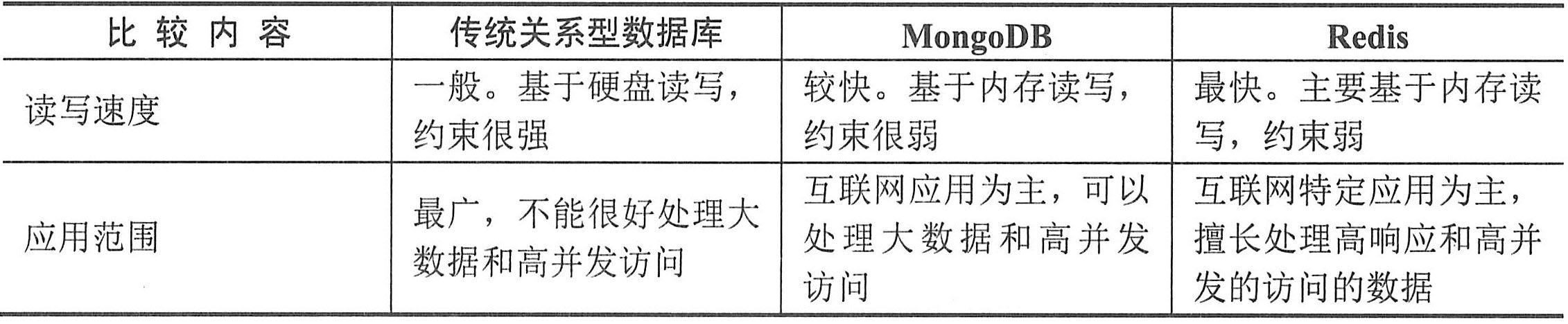
例如,供应者和它所提供的零件信息,关系模式FIRST和函数依赖集F如下:
|
|
|
|
FIRST(Sno,Sname,Status,City,Pno,Qty)
|
|
|
|
F={Sno→Sname,Sno→Status,Status→City,(Sno,Pno)→Qty}
|
|
|
|
对具体的关系FIRST如下表所示。从下表中可以看出,每一个分量都是不可再分的数据项,所以是1NF的。但是,1NF存在4个问题:
|
|
|
|
|
|
|
|
(1)冗余度大。例如每个供应者的Sno、Sname、Status、City要与其供应的零件的种类一样多。
|
|
|
|
(2)引起修改操作的不一致性。例如供应者S1从“天津”搬到“上海”,若不注意,会使一些数据被修改,另一些数据未被修改,导致数据修改的不一致性。
|
|
|
|
(3)插入异常。关系模式FRIST的主码为Sno、Pno,按照关系模式实体完整性规定主码不能取空值或部分取空值。这样,当某个供应者的某些信息未提供时(如Pno),则不能进行插入操作,这就是所谓的插入异常。
|
|
|
|
(4)删除异常。若供应商S4的P2零件销售完了,并且以后不再销售P2零件,那么应删除该元组。这样,在基本关系FIRST找不到S4,可S4又是客观存在的。
|
|
|
|
正因为上述4个原因,所以要对模式进行分解,并引入了2NF。
|
|
|
|
|
|
【定义7.11】若关系模式R∈1NF,且每一个非主属性完全依赖于码,则关系模式R∈2NF。
|
|
|
|
换句话说,当1NF消除了非主属性对码的部分函数依赖,则称为2NF。
|
|
|
|
例如,FIRST关系中的码是Sno、Pno,而Sno→Status,因此非主属性Status部分函数依赖于码,故非2NF的。
|
|
|
|
|
|
FIRST1(Sno,Sname,Status,City)∈ 2NF
|
|
|
|
|
|
因为分解后的关系模式FIRST1的码为Sno,非主属性Sname、Status、City完全依赖于码Sno,所以属于2NF;关系模式FIRST2的码为Sno、Pno,非主属性Qty完全依赖于码,所以也属于2NF。
|
|
|
|
|
【定义7.12】若关系模式R(U,F)中不存在这样的码X,属性组Y及非主属性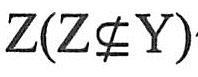 使得X→Y, 使得X→Y,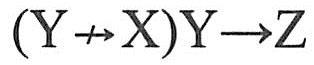 成立,则关系模式R∈3NF。 成立,则关系模式R∈3NF。
|
|
|
|
即当2NF消除了非主属性对码的传递函数依赖,则称为3NF。
|
|
|
|
例如,FIRST1?3NF,因为在分解后的关系模式FIRST1中有Sno→Status,Status→City,存在着非主属性City传递依赖于码Sno。若此时将FIRST1继续分解为:
|
|
|
|
FIRST11(Sno,Sname,Status)∈ 3NF
|
|
|
|
|
|
通过上述分解,数据库模式FIRST转换为FIRST11(Sno,Sname,Status)、FIRST12(Status,City)、FIRST2(Sno,Pno,Qty)三个子模式。由于这三个子模式都达到了3NF,因此称分解后的数据库模式达到了3NF。
|
|
|
|
可以证明,3NF的模式必是2NF的模式。产生冗余和异常的两个重要原因是部分依赖和传递依赖。因为3NF模式中不存在非主属性对码的部分函数依赖和传递函数依赖,所以具有较好的性能。对于非3NF的1NF、2NF其性能弱,一般不宜作为数据库模式,通常要将它们变换成为3NF或更高级别的范式,这种变换过程称为“关系模式的规范化处理”。
|
|
|
|
BCNF(Boyce Codd Normal Form,巴克斯范式)
|
|
|
【定义7.13】关系模式R∈1NF,若X→Y且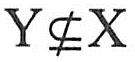 时,X必含有码,则关系模式R∈BCNF。 时,X必含有码,则关系模式R∈BCNF。
|
|
|
|
也就是说,当3NF消除了主属性对码的部分函数依赖和传递函数依赖,则称为BCNF。
|
|
|
|
|
|
|
|
(2)所有非主属性对每一个不包含它的码,也是完全函数依赖。
|
|
|
|
(3)没有任何属性完全函数依赖于非码的任何一组属性。
|
|
|
|
例如,设R(Pno,Pname,Mname)的属性分别表示零件号、零件名和厂商名,如果约定,每种零件号只有一个零件名,但不同的零件号可以有相同的零件名;每种零件可以有多个厂商生产,但每家厂商生产的零件应有不同的零件名。这样我们可以得到如下一组函数依赖:
|
|
|
|
Pno→Pname,(Pname,Mname)→Pno
|
|
|
|
由于该关系模式R中的候选码为(Pname,Mname)或(Pno,Mname),因而关系模式R的属性都是主属性,不存在非主属性对码的传递依赖,所以R是3NF的。但是,主属性Pname传递依赖于码(Pname,Mname),因此R不是BCNF的。当一种零件由多个生产厂家生产时,零件名与零件号间的联系将多次重复,带来冗余和操作异常现象。若将R分解成:
|
|
|
|
R1(Pno,Pname)和R2(Pno,Mname)
|
|
|
|
就可以解决上述问题,并且分解后的关系模式R1、R2都属于BCNF。
|
|
|
|
|
【定义7.14】关系模式R∈1NF,若对于R的每个非平凡多值依赖X→→Y且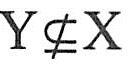 时,X必含有码,则关系模式R(U,F)∈4NF。 时,X必含有码,则关系模式R(U,F)∈4NF。
|
|
|
|
4NF是限制关系模式的属性间不允许有非平凡且非函数依赖的多值依赖。
|
|
|
|
注意:如果只考虑函数依赖,关系模式最高的规范化程度是BCNF;如果考虑多值依赖,关系模式最高的规范化程度是4NF。
|
|
|
|
|
|
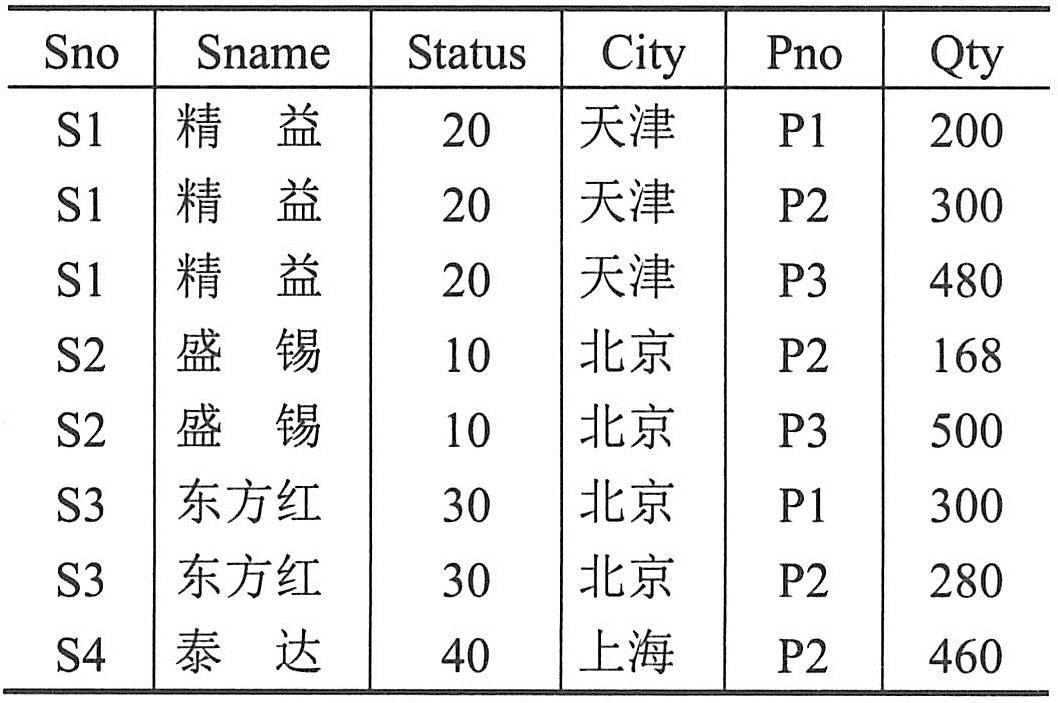
连接依赖:当关系模式无损分解为n个投影(n>2)会产生一些特殊的情况。下面考虑供应商数据库中SPJ关系的一个具体的值,如下图所示。
|
|
|
|
|
|
|
第一次SP、PJ投影连接“ ”起来的结果比原始SPJ关系多了一个元组“S2,P1,J2”,即上图中带下画线的元组。第二次连接的结果去掉了多余的元组,从而恢复了原始的关系SPJ。在这种情况下,原始的SPJ关系是可3分解的。注意,无论我们选择哪两个投影作为第一次连接,结果都是一样的,尽管在每种情况下中间结果不同。 ”起来的结果比原始SPJ关系多了一个元组“S2,P1,J2”,即上图中带下画线的元组。第二次连接的结果去掉了多余的元组,从而恢复了原始的关系SPJ。在这种情况下,原始的SPJ关系是可3分解的。注意,无论我们选择哪两个投影作为第一次连接,结果都是一样的,尽管在每种情况下中间结果不同。
|
|
|
|
SPJ的可3分解性是基本与时间无关的特性,是关系模式的所有合法值满足的特性,也就是说,这是关系模式满足一个特定的与时间无关的完整性约束。将这种约束简称为3D(3分解)约束。上述情况就是连接依赖要研究的问题。
|
|
|
|
连接依赖:如果给定一个关系模式R,R1,R2,R3,…,Rn是R的分解,那么称R满足连接依赖JD*{R1,R2,R3,…,Rn},当且仅当R的任何可能出现的合法值都与它在R1,R2,R3,…,Rn上的投影等价。
|
|
|
形式化地说,若R=R1∪R2∪…∪Rn,且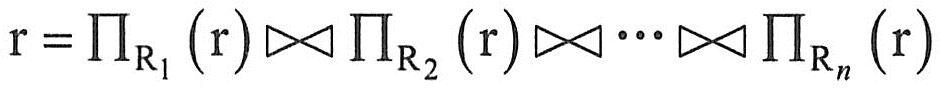 ,则称R满足连接依赖JD*{R1,R2,R3,…,Rn}。如果某个Ri,就是R本身,则连接依赖是平凡的。 ,则称R满足连接依赖JD*{R1,R2,R3,…,Rn}。如果某个Ri,就是R本身,则连接依赖是平凡的。
|
|
|
|
为了进一步理解连接依赖的概念,我们考虑银行数据库中的子模式:贷款(L-no,Bname,C-name,amount)。其中:
|
|
|
|
.贷款号为L-no的贷款是由机构名为Bname贷出的。
|
|
|
|
.贷款号为L-no的贷款是贷给客户名为C-name的客户。
|
|
|
|
|
|
|
|
JD*((L-no,Bname),(L-no,C-name),(L-no,amount))
|
|
|
|
这个例子说明了连接依赖很直观,符合数据库设计的原则。
|
|
|
|
【定义7.15】一个关系模式R是第五范式(也称投影-连接范式PJNF),当且仅当R的每一个非平凡的连接依赖都被R的候选码所蕴涵,记作5NF。
|
|
|
|
“被R的候选码所蕴涵”的含义可通过SPJ关系来理解。关系模式SPJ并不是5NF的,因为它满足一个特定连接依赖,即3D约束。这显然没有被其唯一的候选码(该候选码是所有属性的组合)所蕴涵。其区别是,关系模式SPJ并不是5NF,因为它是可被3分解的,可3分解并没有为其(Sno,Pno,Jno)候选码所蕴涵。但是将SPJ3分解后,由于3个投影SP、PJ、JS不包括任何(非平凡的)连接依赖,因此它们都是5NF的。
|
|
|