|
|
|
数据流图或称数据流程图(Data Flow Diagram,DFD),是一种便于用户理解、分析系统数据流程的图形工具。它摆脱了系统的物理内容,精确地在逻辑上描述系统的功能、输入、输出和数据存储等,是系统逻辑模型的重要组成部分。
|
|
|
|
|
|
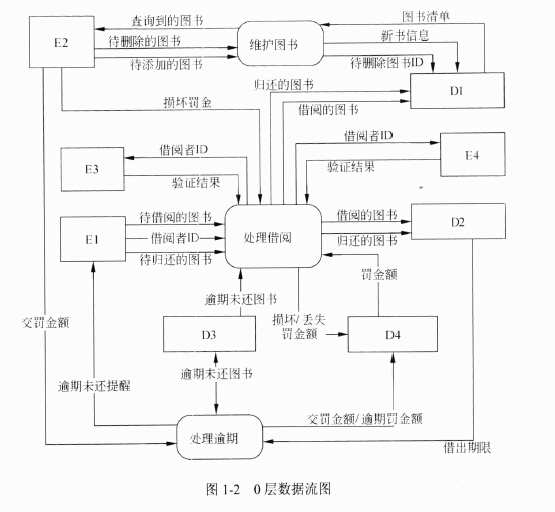
DFD的基本成分包括数据流、加工、数据存储和外部实体,可分别用下图(a)~(d)表示。
|
|
|
|
|
|
|
|
(1)数据流。数据流由一组固定成分的数据组成,表示数据的流向。值得注意的是,DFD中描述的是数据流,而不是控制流。除了流向数据存储或从数据存储流出的数据流不必命名外,每个数据流都必须有一个合适的名字,以反映该数据流的含义。
|
|
|
|
(2)加工。加工描述了输入数据流到输出数据流之间的变换,也就是输入数据流经过什么处理后变成了输出数据流。每个加工有一个名字和编号。编号能反映出该加工位于分层DFD中的哪个层次和哪张图中,也能够看出它是哪个加工分解出来的子加工。
|
|
|
|
(3)数据存储。数据存储用来表示存储的数据,每个数据存储都有一个名字。
|
|
|
|
(4)外部实体。外部实体是指存在于软件系统之外的人员或组织,它指出系统所需数据的发源地和系统所产生的数据的归宿地。
|
|
|
|
|
|
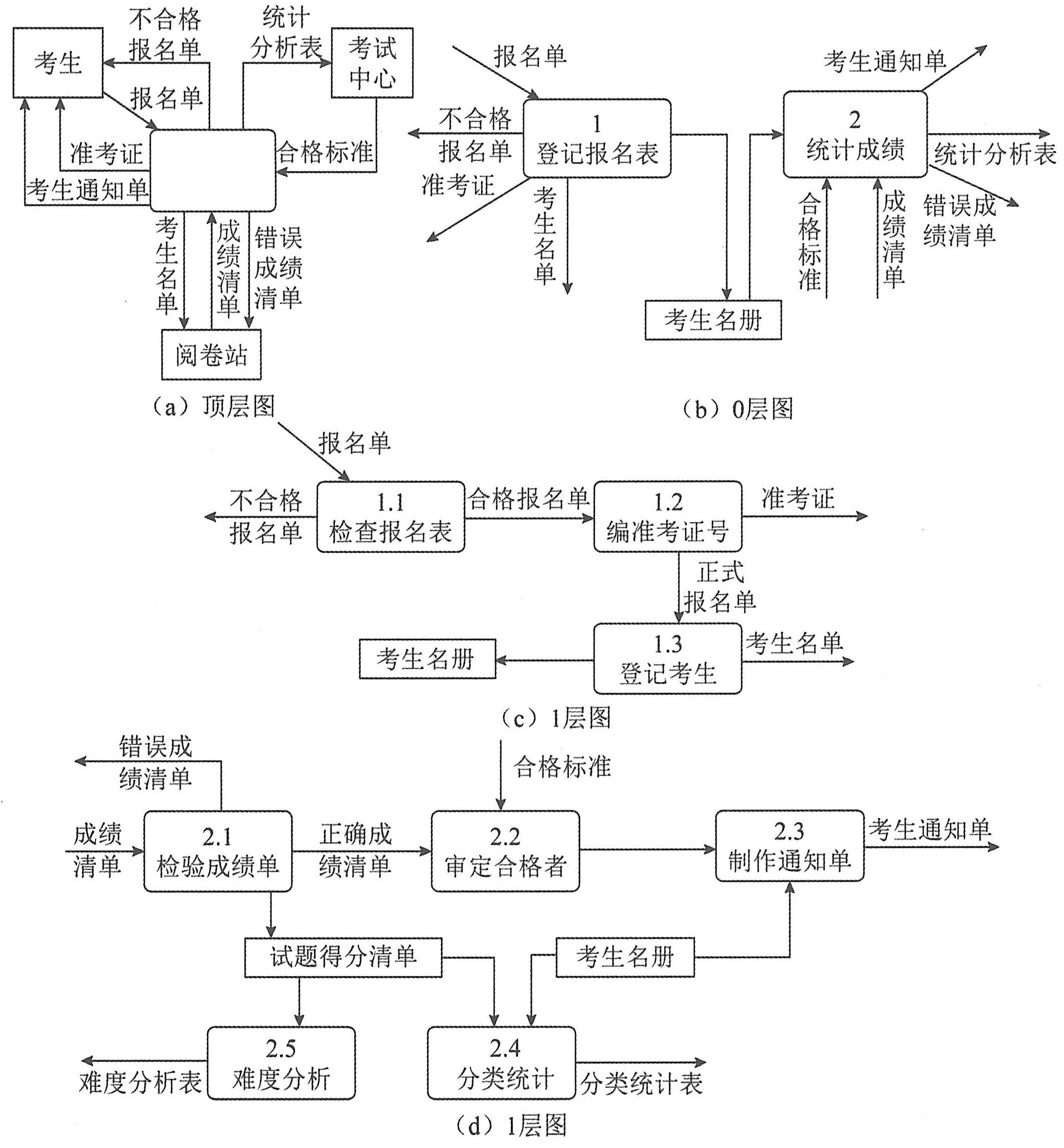
(1)画系统的输入和输出。把整个软件系统看作一个大的加工,然后根据系统从哪些外部实体接收数据流,以及系统发送数据流到哪些外部实体,就可以画出系统的输入和输出图,这张图称为顶层图。
|
|
|
|
(2)画系统的内部。将顶层图的加工分解成若干个加工,并用数据流将这些加工连接起来,使得顶层图中的输入数据经过若干个加工处理后变换成顶层图的输出数据流。这张图称为0层图。从一个加工画出一张数据流图的过程实际上就是对这个加工的分解。
|
|
|
|
可以用下述的方法来确定加工:在数据流的组成或值发生变化的地方应画一个加工,这个加工的功能就是实现这一变化;也可根据系统的功能确定加工。
|
|
|
|
确定数据流的方法:当用户把若干个数据看作一个单位来处理(这些数据一起到达,一起加工)时,可把这些数据看成一个数据流。
|
|
|
|
对于一些以后某个时间要使用的数据可以组织成一个数据存储来表示。
|
|
|
|
(3)画加工的内部。把每个加工看作一个小系统,该加工的输入输出数据流看成小系统的输入输出数据流。于是可以用与画0层图同样的方法画出每个加工的DFD子图。
|
|
|
|
(4)对第(3)步分解出来的DFD子图中的每个加工,重复第(3)步的分解,直至图中尚未分解的加工都足够简单(也就是说这种加工不必再分解)为止。至此,得到了一套分层数据流图。
|
|
|
|
|
|
对于一个软件系统,其数据流图可能有许多层,每一层又有许多张图。为了区分不同的加工和不同的DFD子图,应该对每张图和每个加工进行编号,以利于管理。
|
|
|
|
|
|
假设分层数据流图里的某张图(记为图A)中的某个加工可用另一张图(记为图B)来分解,称图A是图B的父图,图B是图A的子图。在一张图中,有些加工需要进一步分解,有些加工则不必分解。因此,如果父图中有n个加工,那么它可以有0~n张子图(这些子图位于同一层),但每张子图都只对应于一张父图。
|
|
|
|
|
|
①顶层图只有一张,图中的加工也只有一个,所以不必编号。
|
|
|
|
②0层图只有一张,图中的加工号可以分别是0.1,0.2,……或者是1,2,……。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
(3)对阅卷站送来的成绩清单进行检查,并根据考试中心指定的合格标准审定合格者。
|
|
|
|
(4)制作考生通知单(内含成绩合格/不合格标志)送给考生。
|
|
|
|
(5)按地区、年龄、文化程度、职业和考试级别等进行成绩分类统计和试题难度分析,产生统计分析表。
|
|
|
|
|
|
|
|
|
|
|
|
(1)适当地为数据流、加工、数据存储、外部实体命名,名字应反映该成分的实际含义,避免空洞的名字。
|
|
|
|
|
|
|
|
(4)一个加工的输出数据流不应与输入数据流同名,即使它们的组成成分相同。
|
|
|
|
(5)允许一个加工有多条数据流流向另一个加工,也允许一个加工有两个相同的输出数据流流向两个不同的加工。
|
|
|
|
(6)保持父图与子图平衡。也就是说,父图中某加工的输入输出数据流必须与它的子图的输入输出数据流在数量和名字上相同。值得注意的是,如果父图的一个输入(或输出)数据流对应于子图中几个输入(或输出)数据流,而子图中组成这些数据流的数据项全体正好是父图中的这一个数据流,那么它们仍然算是平衡的。
|
|
|
|
(7)在自顶向下的分解过程中,若一个数据存储首次出现时只与一个加工有关,那么这个数据存储应作为这个加工的内部文件而不必画出。
|
|
|
|
(8)保持数据守恒。也就是说,一个加工所有输出数据流中的数据必须能从该加工的输入数据流中直接获得,或者是通过该加工能产生的数据。
|
|
|
|
(9)每个加工必须既有输入数据流,又有输出数据流。
|
|
|
|
(10)在整套数据流图中,每个数据存储必须既有读的数据流,又有写的数据流。但在某一张子图中可能只有读没有写,或者只有写没有读。
|
|
|