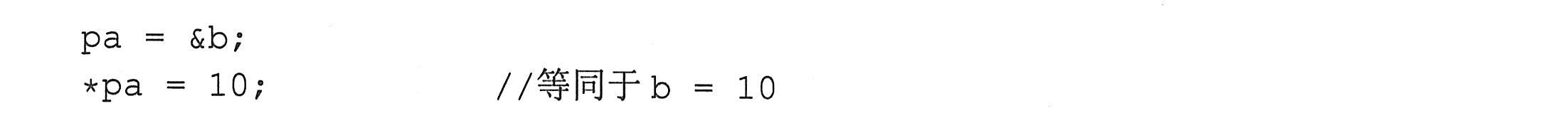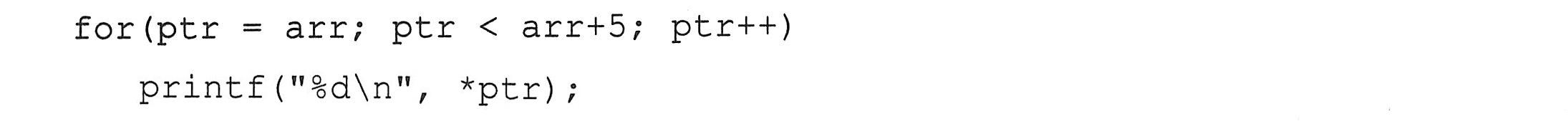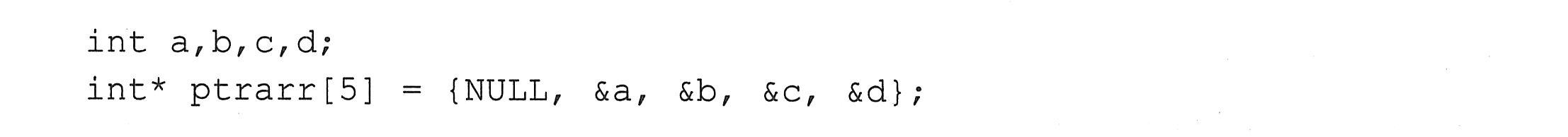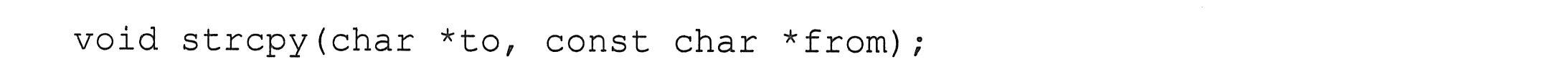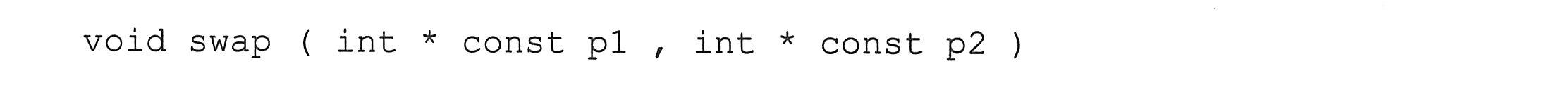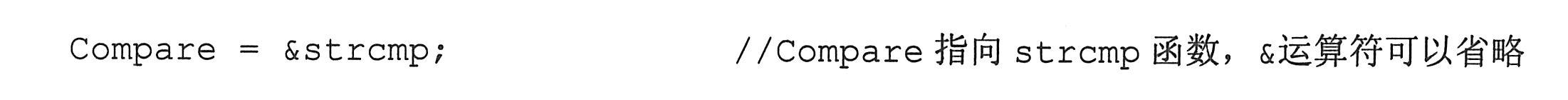|
|
|
简单来说,指针是内存单元的地址,它可能是变量的地址、数组空间的地址,或者是函数的入口地址。存储地址的变量称为指针变量,简称为指针。指针是C语言中最有力的武器,能够为程序员提供极大的编程灵活性。
|
|
|
|
|
|
指针类型的变量是用来存放内存地址的,下面是两个指针变量的定义:
|
|
|
|
|
|
变量ptr1和ptr2都是指针类型的变量,ptr1用于保存一个整型变量的地址(称ptr1指向一个整型变量),ptr2用于保存一个字符型变量的地址(称ptr2指向一个字符变量)。
|
|
|
|
使用指针时需明确两个概念:指针对象和指针指向的对象。指针对象是明确命名的指针变量,如上例中的ptr1、ptr2;指针指向的对象是另一个变量,用“*”和指针变量联合表示,如上例中的整型变量*ptr1和字符变量*ptr2,由于上面的定义中未对ptr1和ptr2进行初始化,它们的初始值是随机的,也就是*ptr1和*ptr2可视为并不存在。
|
|
|
|
借助指针变量可以针对指定的地址进行操作,例如,设置地址为0x1234开始的存储空间存放一个整型变量的值0x5678,代码如下。
|
|
|
|
|
|
|
|
|
|
|
|
对指针变量进行加减运算时,是以指针所指向的数据类型存储宽度为单位计算的。
|
|
|
|
例如,下面的指针p和s在进行加1运算时有不同的结果。
|
|
|
|
|
|
p+1实际上是按照公式p+1*sizeof(int)来计算的,s+1则是按照s+1*sizeof(char)进行计算。
|
|
|
|
|
|
标准预处理宏NULL(它的值为0,称为空指针常量)常用来表示指针不指向任何内存单元,可以把NULL赋给任意类型的指针变量,以初始化指针变量。例如:
|
|
|
|
|
|
需要注意:全局指针变量会被自动初始化为NULL,局部指针变量的初始值是随机的。编程时常见的一个错误是没有给指针变量赋初值。未初始化的指针变量可能表示了一个非法的地址,导致程序运行时出现内存访问错误,从而使程序异常终止。
|
|
|
|
|
|
“&”称为地址运算符,其作用是获取变量的地址。“*”称为间接运算符,其作用是获取指针所指向的变量。
|
|
|
|
例如,下面的语句“pa=&b;”执行后,变量pa就得到了b的地址(称为指针pa指向b),*pa表示pa指向的变量(也就是变量b)。
|
|
|
|
|
|
|
|
在上面的例子中,通过指针pa修改了变量b的值,本质上是对b的间接访问。在程序中通过指针访问数据对象或函数对象,提供了运算处理上的灵活性。
|
|
|
|
如果指针变量的值是空指针或者是随机的,通过指针来访问数据就是一种错误(在编译时报错,或者在运行时发生异常),下面的语句会产生一个运行时错误(vp可能表示了一个非法的地址,因此它所指向的对象*vp也是非法的)。
|
|
|
|
|
|
void*类型可以与任意的数据类型匹配。void指针在被使用之前,必须转换为明确的类型。例如:
|
|
|
|
|
|
|
|
在程序运行过程中,堆内存能够被动态地分配和释放,在C程序中通过malloc(或calloc、realloc)和free函数实现该处理要求。
|
|
|
|
|
|
|
|
在堆中分配的内存块的生存期是由程序员自己控制的,应在程序中显式地释放。例如:
|
|
|
|
|
|
注意:指针为空(指针值为0或NULL)时表示不指向任何内存单元,因此释放空指针没有意义。
|
|
|
|
因为内存资源是有限的,所以若申请的内存块不再需要就及时释放。如果程序中存在未被释放(由于丢失其地址在程序中也不能再访问)的内存块,则称为内存泄漏。持续的内存泄漏会导致程序性能降低,甚至崩溃。嵌入式系统存储空间非常有限,一般情况下应尽量采用静态存储分配策略。
|
|
|
|
|
|
|
|
在C程序中,常利用指针访问数组元素,数组名表示数组在内存中的首地址,即数组中第一个元素的地址。可以通过下标访问数组元素,也可以通过指针访问数组元素。
|
|
|
|
|
|
|
|
数组arr的元素可以用*ptr、*(ptr+1)、*(ptr+2)、*(ptr+3)来引用。
|
|
|
|
数组名是常量指针,数组名的值不能改变,因此arr++是错误的,而ptr++是允许的。例如,下面的代码通过修改指针ptr来访问数组中的每个元素。
|
|
|
|
|
|
一般情况下,一个int型变量占用4个字节的内存空间,一个char型变量占用一个字节的空间,所以str是字符指针的话,str++就使str指向下一个字符;而整型指针ptr++则使ptr指向下一个int型整数,即指向数组的第二个元素。
|
|
|
|
可以用指针访问二维数组元素。例如,对于一个m行、n列的二维整型数组,其定义为
|
|
|
|
|
|
由于二维数组元素在内存中是以线性序列方式存储的,且按行存放,所以用指针访问二维数组的关键是如何计算出某个二维数组元素在内存中的地址。二维数组a的元素a[i][j](ii][j]之前的元素所占空间形成的偏移量,概念上表示为a+(i×n+j)*sizeof(int),在程序中需要表示为(&a[0][0]+i×n+j)。
|
|
|
|
|
|
可将指针设置为指向字符串常量(存储在只读存储区域),通过指针读取字符串或其中的字符。例如,
|
|
|
|
|
|
不允许在程序运行过程中修改字符串常量。例如,下面代码试图通过修改字符串的第2个字符将“hello”改为“hallo”,程序运行时该操作会导致异常,原因是str指向的是字符串常量“hello”,该字符串在运行时不能被修改。
|
|
|
|
|
|
如果用const进行修饰,这个错误在编译阶段就能检查出来,修改如下:
|
|
|
|
|
|
|
|
如果数组的元素类型是指针类型,则称之为指针数组。下面的ptrarr是一维数组,数组元素是指向整型变量的指针。
|
|
|
|
|
|
若需要动态生成二维整型数组,则传统的处理方式是先设置一个指针数组arr2,然后将其每个元素的值(指针)初始化为动态分配的“行”。
|
|
|
|
|
|
|
|
在C程序中,对指针变量加一个整数或减一个整数的含义与指针指向的对象有关,也就是与指针所指向的变量所占用存储空间的大小有关。例如:
|
|
|
|
|
|
|
|
常量指针是指针变量指向的对象是常量,即指针变量可以修改,但是不能通过指针变量来修改其指向的对象。例如,
|
|
|
|
|
|
|
|
在定义指针时,如果在指针变量前加一个const修饰符,就定义了一个指针常量,即指针值是不能修改的。
|
|
|
|
|
|
指针常量定义时被初始化为指向整型变量d。p本身不能修改(即p不能再指向其他对象),但它所指向变量的内容却可以修改,例如,*p=5(实际上是将d的值改为5)。
|
|
|
|
区分常量指针和指针常量的关键是“*”的位置,如果const在“*”的左边,则为常量指针,如果const在“*”的右边则为指针常量。如果将“*”读作“指针”,将const读作“常量”,内容正好符合。对于定义“int const *p;”p是常量指针,而定义“int* const p;”p是指针常量。
|
|
|
|
|
|
|
|
|
|
函数调用时,用指针作为函数的参数可以借助指针来改变调用函数中实参变量的值。以下面的swap函数为例进行说明,该函数的功能是交换两个整型变量的值。
|
|
|
|
|
|
若有函数调用swap(&x,&y),则swap函数执行后两个实参x和y的值被交换。函数中参与运算的值不是pa、pb本身,而是它们所指向的变量,也就是实参x、y(*pa与x、*pb与y所表示的对象相同)。在调用函数中,是把实参的地址传送给形参,即传送&x和&y,在swap函数中指针pa和pb并没有被修改。
|
|
|
|
如果在被调用函数中修改了指针参数的值,则不能实现对实参变量的修改。例如,下面函数get_str中的错误是将指针p指向的目标修改了,从而在main中调用get_str后,ptr的值仍然是NULL。
|
|
|
|
|
|
将上面的函数定义和调用作如下修改,就可以修改实参ptr的值,使其指向函数中所申请的字符串存储空间。
|
|
|
|
|
|
|
|
用const修饰函数参数,可以避免在被调用函数中出现不当的修改。例如:
|
|
|
|
|
|
其中,from是输入参数,to是输出参数,如果在函数strcpy内通过from来修改其指向的字符(如*from='a'),编译时将报错。
|
|
|
|
若需要使指针参数在函数内不能修改为指向其他对象,则可如下修饰指针参数。
|
|
|
|
|
|
|
|
函数的返回值也可以是一个指针。返回指针值的函数的一般定义形式是:
|
|
|
|
|
|
例如,如下进行函数定义和调用,可以降低函数参数的复杂性。
|
|
|
|
|
|
|
|
注意:不能将具有局部作用域的变量的地址作为函数的返回值。这是因为局部变量的内存空间在函数返回后即被释放,而该变量也不再有效。
|
|
|
|
例如,下面函数被调用后,变量a的生存期结束,其存储空间(地址)不再有效。
|
|
|
|
|
|
|
|
在C程序中,可以将函数地址保存在函数指针变量中,然后用该指针间接调用函数。例如:
|
|
|
|
|
|
该语句定义了一个名称为Compare的函数指针变量,用于保存任何有两个常量字符指针形参、返回整型值的函数的地址(函数的地址通常用函数名表示)。例如,Compare可以指向字符串运算函数库中的函数strcmp。
|
|
|
|
|
|
|
|
|
|
|
|
若有函数定义int strcmp(const char*,const char*);则strcmp能被直接调用,也能通过Compare被间接调用。下面三个函数调用是等价的:
|
|
|
|
|
|
|
|
指针是C语言的特色和精华所在,链表是指针的重要应用之一,创建、查找、插入和删除结点是链表上的基本运算,需熟练掌握这些运算的实现过程,其关键点是指针变量的初始化和在链表结点间的移动处理。
|
|
|
|
以元素值为整数的单链表为例,需要先定义链表中结点的类型,下面将其命名为Node,而LinkList则是指向Node类型变量的指针类型名。
|
|
|
|
|
|
当p指向Node类型的结点时,涉及两个指针变量:p和p->next,p是指向结点的指针,p->next是结点中的指针域,如下图(a)所示;运算“p=p->next;”之后,p指向下一个结点;如下图(b)所示;运算“p->next=p;”之后,结点的指针域指向结点自己,如下图(c)所示。
|
|
|
|
|
|
|