|
|
|
SQL(Structrued Query Language)是关系数据库标准语言,它不仅包含数据查询功能,还包括插入、删除、更新和数据定义功能。
|
|
|
|
|
|
一个SQL数据库是表的汇集,它用一个或多个SQL模式定义。其主要特点为:
|
|
|
|
(1)综合统一。SQL是集数据定义、数据操纵和数据控制功能于一体,语言风格统一,可独立完成数据库生命周期的所有活动。而非关系模型的数据语言分为模式定义语言和数据操纵语言,当数据库投入运行后,若要修改模式时,必须停止现有数据库的运行,然后转储数据,修改模式并编译后再重装数据库,非常麻烦。
|
|
|
|
(2)高度非过程化。非关系数据模型的数据操纵语言是面向过程的,若要完成某项请求时,必须指定存储路径。而SQL语言是高度非过程化语言,当进行数据操作时,只要指出“做什么”,无须指出“怎么做”,存储路径对用户来说是透明的,提高了数据的独立性。
|
|
|
|
(3)面向集合的操作方式。非关系数据模型采用的是面向记录的操作方式,操作对象是一条记录。而SQL语言采用面向集合的操作方式,其操作对象、查找结果可以是元组的集合。
|
|
|
|
(4)灵活的使用方式。用户可以在终端键盘上输入SQL命令,对数据库进行操作;也可以将SQL语言嵌入到高级语言程序中。
|
|
|
|
(5)语言简洁、易学易用。SQL语言功能极强,完成核心功能只用了9个动词,包括如下4类:数据查询(SELECT)、数据定义(CREATE、DROP、ALTER)、数据操纵(INSERT、UODATE、DELETE)和数据控制(GRANT、REVORK)。
|
|
|
|
|
|
|
|
|
|
|
|
说明:语句格式中,“<>”表示必选项,“[]”表示可选项,“|”表示多选一,NOT NULL表示字段不能为空,UNIQUE表示字段值是唯一的,PRIMARY KEY定义字段为主键。
|
|
|
|
|
|
|
|
|
|
例如,向“供应商”表增加“邮政编码”可用如下语句:
|
|
|
|
ALTER TABLE供应商ADD邮政编码text(6);
|
|
|
|
注意,不论基本表中原来是否已有数据,新增加的列一律为空。
|
|
|
|
|
|
ALTER TABLE供应商MODIFY供应商号INT;
|
|
|
|
|
|
|
|
例如,执行“DROP TABLE供应商”语句后,“供应商”表在“销售”数据库不存在。
|
|
|
|
|
|
|
|
聚集索引对表的物理数据页中的数据按列进行排序,然后再重新存储到磁盘上,即聚集索引与数据是混为一体的,它的叶节点中存储的是实际的数据。
|
|
|
|
非聚集索引具有完全独立于数据行的结构,使用非聚集索引不用将物理数据页中的数据按列排序。非聚集索引的叶节点存储了组成非聚集索引的关键字值和行定位器。
|
|
|
|
|
|
|
|
说明:“次序”是指可选ASC(升序)或DSC(降序),默认值为ASC;UNIQUE表示该索引的每一个索引值只对应唯一的数据记录;CLUSTER表明要建立的索引是聚簇索引,意为索引项的顺序是与表中记录的物理顺序一致的索引组织。
|
|
|
|
|
|
|
|
例如,执行DROP INDEX S-SNO,此后索引S-SNO不再是“销售”数据库模式的一部分。
|
|
|
|
|
|
数据库查询是数据库的核心操作,SQL语言提供了SELECT语句进行数据库的查询。
|
|
|
|
|
|
|
|
SQL最简单的查询是找出关系中满足特定条件的元组,这些查询与关系代数中的选择操作类似。简单查询只需要使用三个保留字SELECT、FROM和WHERE。
|
|
|
|
|
|
|
|
|
|
|
|
子查询也称为嵌套查询。嵌套查询是指一个SELECT-FROM-WHERE查询块可以嵌入另一个查询块之中。在SQL中允许多重嵌套。
|
|
|
|
|
|
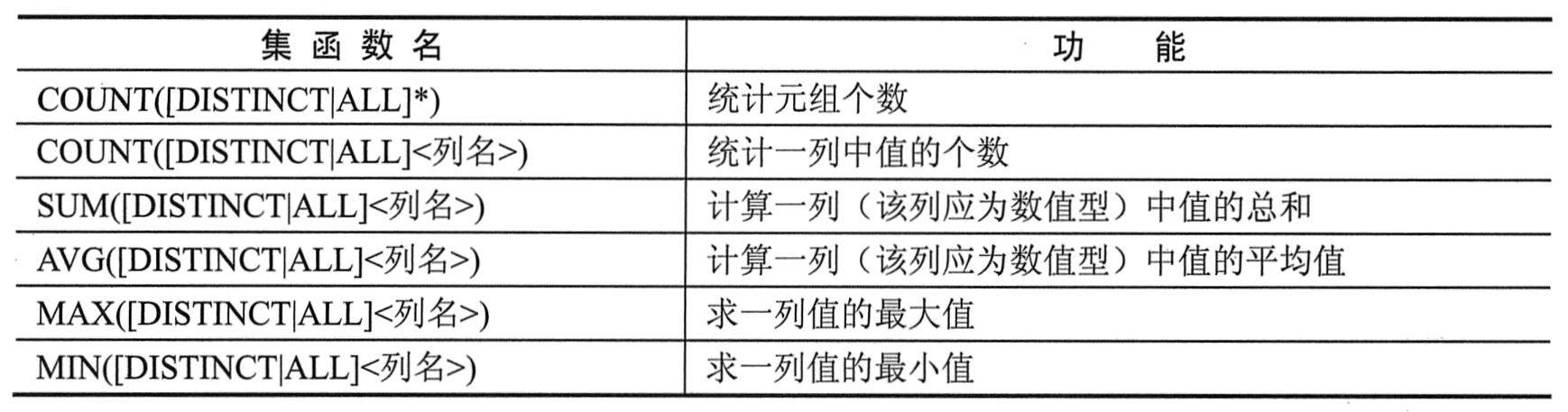
聚集函数是一个值的集合为输入,返回单个值的函数。SQL提供了5个预定义集函数:平均值avg、最小值min、最大值max、求和sum以及计数count。如下表所示。
|
|
|
|
|
|
|
|
|
|
|
|
在WHERE子句后面加上GROUP BY子句可以对记录进行分组,保留字GROUP BY后面跟着一个分组字段列表。最简单的情况是FROM子句后面只有一个关系(表),根据分组字段对表中的记录进行分组。SELECT子句中使用的聚集操作符仅用在每个分组上。
|
|
|
|
|
|
假如记录在分组前按照某种方式加上限制,使得不需要的分组为空,那么可以通过GROUP BY后面跟一个HAVING条件子句实现。
|
|
|
|
注意,当记录含有空值时,在任何聚集操作中被忽视。它对求和、求平均值和计数都没有影响,空值不能作为某列的最大值或最小值。例如,COUNT(*)是某个关系中所有元组数目之和,但COUNT(A)却是A属性非空的元组个数之和。
|
|
|
|
|
|
|
|
在数据库中插入数据,可以通过指定被插入的记录,或者用查询语句选出一批待插入的记录。插入语句的基本格式如下:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|