|
|
|
在讨论一致性之前,先看一下CAP理论。它作为一种理论依据,使得在不同应用中,对一致性也有了不同的要求。CAP理论:简单地说,就是对于一个分布式系统,一致性(Consistency)、可用性(Availablity)和分区容忍性(Partition tolerance)三个特点最多只能三选二。
|
|
|
|
一致性意味着系统在执行了某些操作后仍处在一个一致的状态,这点在分布式的系统中尤其明显。比如某用户在一处对共享的数据进行了修改,那么所有有权使用这些数据的用户都可以看到这一改变。简言之,就是所有的结点在同一时刻有相同的数据。
|
|
|
|
可用性指对数据的所有操作都应有成功的返回。高可用性则是在系统升级(软件或硬件)或在网络系统中的某些结点发生故障的时候,仍可以正常返回。简言之,就是任何请求不管成功或失败都有响应。
|
|
|
|
分区容忍性这一概念的前提是在网络发生故障的时候。在网络连接上,一些结点出现故障,使得原本连通的网络变成了一块一块的分区,若允许系统继续工作,那么就是分区可容忍的。
|
|
|
|
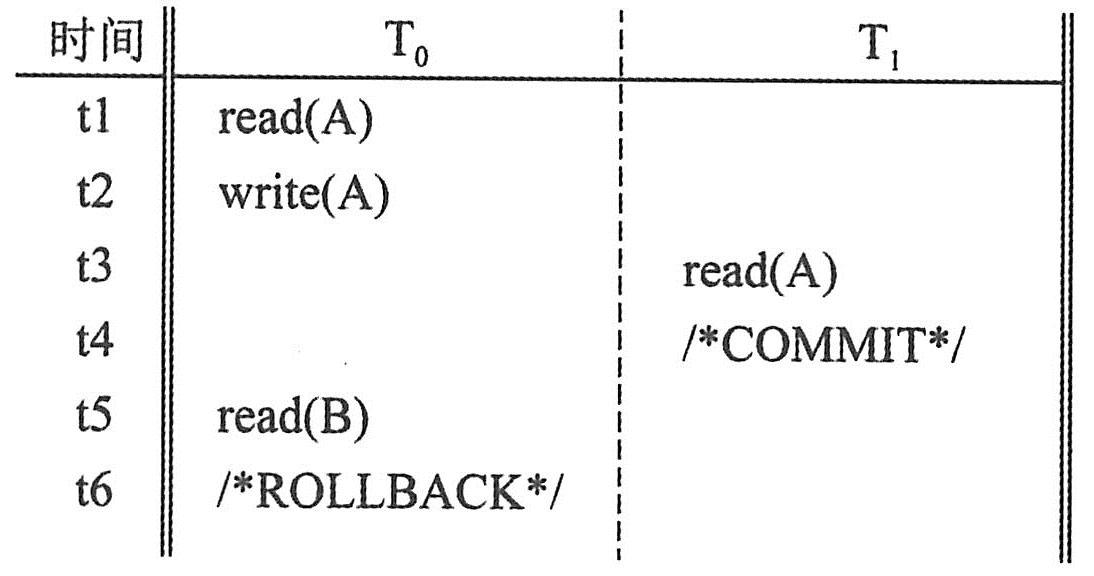
在数据库系统中,事务的ACID属性保证了数据库的一致性。比如银行系统中,转账就是一个事务,从原账户扣除金额,以及向目标账户添加金额,这两个数据库操作的总和构成一个完整的逻辑过程,具有原子的不可拆分特性,从而保证了整个系统中的总金额没有变化。
|
|
|
|
然而,这些ACID特性对于大型的分布式系统来说,是和高性能不兼容的。比如,你在网上书店买书,任何一个人买书这个过程都会锁住数据库直到买书行为彻底完成(否则书本库存数可能不一致),买书完成的那一瞬间,世界上所有的人都可以看到书的库存减少了一本(这也意味着两个人不能同时买书)。这在小的网上书城也许可以运行得很好,可是对Amazon这种网上书城却并不是很好。
|
|
|
|
而对于Amazon这种系统,它也许会用Cache系统,剩余的库存数也许是几秒甚至几个小时前的快照,而不是实时的库存数,这就舍弃了一致性。并且,Amazon可能也舍弃了独立性,当只剩下最后一本书时,也许它会允许两个人同时下单,宁愿最后给那个下单成功却没货的人道歉,而不是整个系统性能的下降。
|
|
|
|
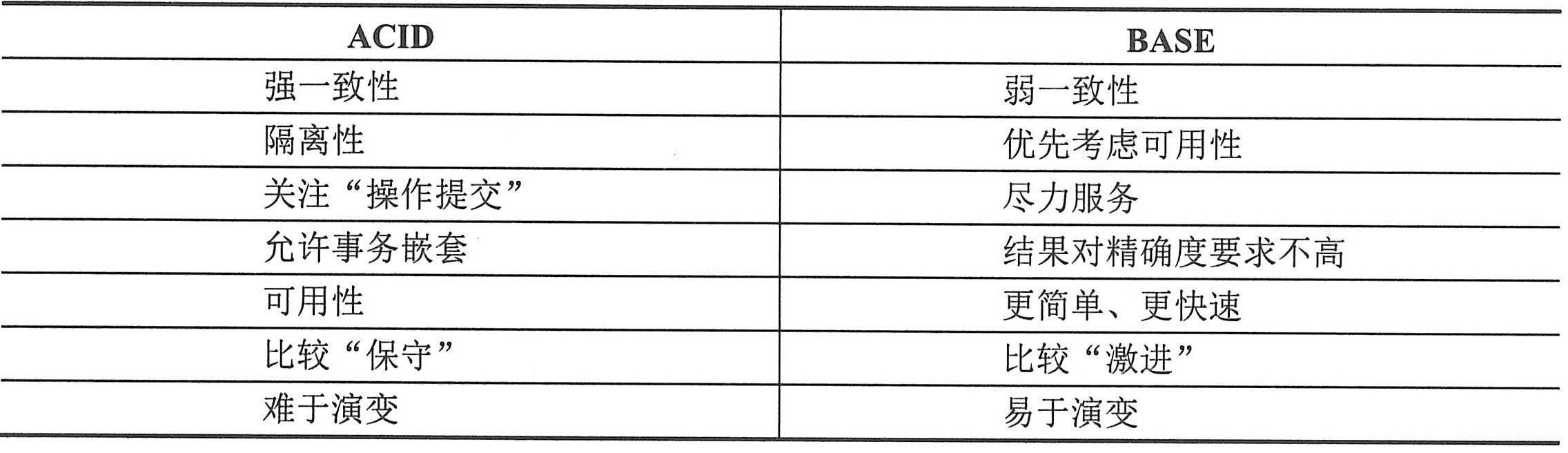
由于CAP理论的存在,为了提高性能,出现了ACID的一种变种BASE(这四个字母分别是Basically Available,Soft—state,Eventual consistency的开头字母,是一个弱一致性的理论,只要求最终一致性):
|
|
|
|
.Basically Available:基本可用。
|
|
|
|
.Soft state:软状态,可以理解为“无连接”的,而与之相对应的Hard state就是“面向连接”的。
|
|
|
|
.Eventual consistency:最终一致性,最终整个系统(时间和系统的要求有关)看到的数据是一致的。
|
|
|
|
在BASE中,强调可用性的同时,引入了最终一致性这个概念,不像ACID,其并不需要每个事务都是一致的,只需要整个系统经过一定时间后最终达到一致。比如Amazon的卖书系统,也许在卖的过程中,每个用户看到的库存数是不一样的,但最终卖完后,库存数都为0。再比如SNS网络中,C更新状态,A也许可以1分钟就看到,而B甚至5分钟后才看到,但最终大家都可以看到这个更新。
|
|
|
|
具体地说,如果选择了CP(一致性和分区容忍性),那么就要考虑ACID理论(传统关系型数据库的基石,事务的四个特点)。如果选择了AP(可用性和分区容忍性),那么就要考虑BASE系统。如果选择了CA(一致性和可用性),如Google的bigtable,那么在网络发生分区的时候,将不能进行完整的操作。
|
|
|
|
|
|
|
|
|