|
|
|
键值存储模型是最简单,也是最方便使用的数据模型,它支持简单的键对值的键值存储和提取。根据一个简单的字符串(键)能够返回一个任意类型的数据(值)。键值存储最大的好处是不用为值指定一个特定的数据类型,这样就能在值里存储任意类型的数据。系统将这些信息按照BLOB大对象进行存储,当收到检索请求时,返回同样的BLOB。由应用来决定被使用的数据是什么类型,如字符串、图片和XML文件等。键值存储数据库的主要特点是具有极高的并发读写性能。
|
|
|
|
|
|
键值存储中的键是很灵活的,可以是图片名称、网页URL或者文件路径名,它们指向那些图片、网页和对应的文档。键可以用很多种格式来表示:
|
|
|
|
|
|
|
|
|
|
|
|
值也很灵活,并且可以是任何BLOB数据,如字符串、图片、网页或视频。下表是一个键值存储的示例。
|
|
|
|
|
|
|
|
|
|
键值存储中存在三种操作:put、get和delete。这三种操作规定了程序员与键值存储交互的基本方式。应用开发者使用put、get和delete函数访问和操作键值存储:
|
|
|
|
(1)put($key as xs:string,$value as item())对表添加一个新的键值对,并且当键存在时,更新键对应的值。
|
|
|
|
(2)get($key as xs:string)as item()根据给出的任意键返回键对应的值,如果键值存储中没有该键,将返回一个错误信息。
|
|
|
|
(3)delete($key as xs:string)将键和对应的值从表中删除,如果键值存储中没有该键,将返回一个错误信息。
|
|
|
|
|
|
键值存储的数据库根据数据的保存方式可以分为临时性、永久性和两者兼具三种。
|
|
|
|
|
|
临时性的保存有可能丢失数据。这类数据库一般把数据都保存在内存中,这样读和写的速度都非常快,但是当数据库停止或者机器重启后,数据就不存在了。由于数据保存在内存中,所以也无法操作超过内存容量的数据,旧的数据会丢失。特点可以总结如下:
|
|
|
|
|
|
|
|
|
|
|
|
永久性的保存不会丢失数据。这类数据库一般不把数据保存在内存中,而是把数据保存在硬盘上。与临时性在内存中读和写数据比较起来,由于牵扯到对硬盘的I/O操作,所以性能上的差距是显而易见的。但是它的最大优势是不会丢失数据。特点可以总结如下:
|
|
|
|
|
|
|
|
|
|
|
|
这类数据库兼具临时性保存和永久性保存的优点。比如典型的Redis系统,它首先把数据保存在内存中,平时都在内存中进行读和写操作。在满足特定条件(缺省是15分钟一次以上,5分钟10个以上或1分钟1000个以上的键发生变化)时,将数据写入到硬盘上保存。这样既确保了内存中数据处理的高速性,又通过写入硬盘来保证数据的永久性。这种类型的数据库特别适合处理数组类型的数据,特点可以总结如下:
|
|
|
|
|
|
|
|
|
|
|
|
键值存储产品主要有亚马逊的Memcached、Redis、Dynamo、Project Voldemort、Tokyo Tyrant、Riak、Scalaries这几个数据库,这里主要介绍一下Memcached和Redis。
|
|
|
|
|
|
Memcached属于前面分类中的临时性保存类型,是高性能的分布式内存对象缓存系统。一般的使用目的是,通过缓存数据库查询结果,减少数据库访问次数,以提高动态Web应用的速度、提高可扩展性。它和共享内存、APC等本地缓存的区别在于Memcached是分布式的,也就是说它不是本地的。它基于网络连接方式完成服务,本身它是一个独立于应用的程序或守护进程。
|
|
|
|
Memcached使用libevent库实现网络连接服务,理论上可以处理无限多的连接,但是它和Apache不同,它更多的时候是面向稳定的持续连接的,所以它实际的并发能力是有限制的。Memcached内存使用方式也和APC不同。后者是基于共享内存和MMAP的,Memcached有自己的内存分配算法和管理方式,它和共享内存没有关系,也没有共享内存的限制。
|
|
|
|
正如所有的NoSQL数据库一样,Memcached也有其特定的应用场合。Memcached常作为数据库前段Cache使用。因为它比数据库少了很多SQL解析、磁盘操作等开销,而且它是使用内存来管理数据的,所以它可以提供比直接读取数据库更好的性能。另外,Memcached也常作为服务器直接数据共享的存储媒介,例如SSO系统中保持系统单点登录状态的数据就可以保持在Memcached中,被多个应用共享。
|
|
|
|
在实际应用中,通常会把数据库查询的结果集保存到Memcached中,下次访问时直接从Memcached中获取,而不再做数据库查询操作,这样可以在很大程度上减轻数据库的负担。通常会将SQL语句md5()之后的值作为唯一标识符key。下边是一个利用Memcached来缓存数据库查询结果集的示例(此代码片段紧接上边的示例代码):
|
|
|
|
|
|
可以看出,使用Memcached之后,可以减少数据库连接、查询操作,数据库负载下来了,脚本的运行速度也提高了。
|
|
|
|
|
|
Redis是一种主要基于内存存储和运行,能够快速响应的键值数据库,属于临时和永久兼具类型,有点像Memcached,整个数据库统统加载在内存当中进行操作,但是通过定期异步操作把数据库数据flush到硬盘上进行保存。因为是纯内存操作,Redis的性能非常出色,每秒可以处理超过10万次读写操作。
|
|
|
|
Redis的出色之处不仅仅是性能,Redis最大的魅力是支持保存List链表和Set集合的数据结构,而且还支持对List进行各种操作。此外单个value的最大限制是1GB,不像Memcached只能保存1MB的数据。其主要缺点是数据库容易受到物理内存的限制,不能用作海量数据的高性能读写,并且它没有原生的可扩展机制,不具有扩展能力,要依赖客户端来实现分布式读写,因此Redis适合的场景主要局限在较小数据量的高性能操作和运算上。
|
|
|
|
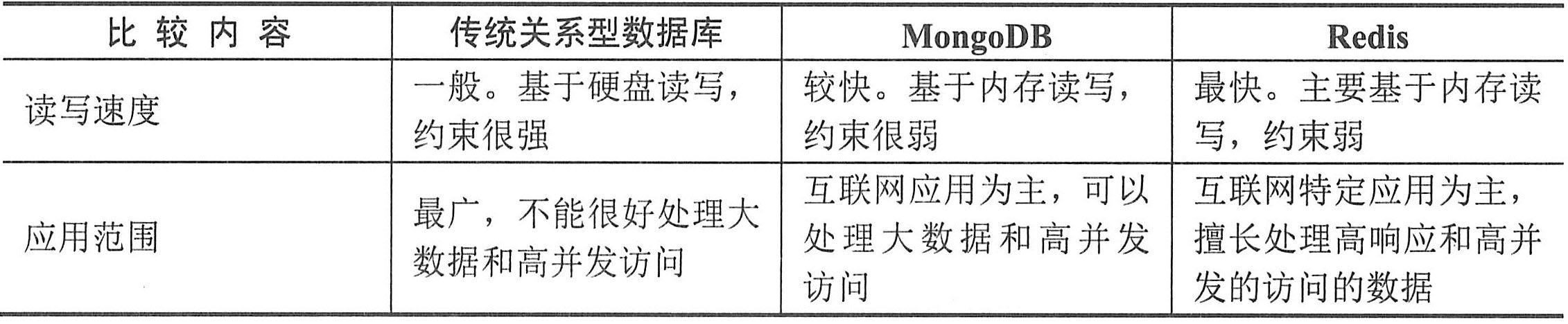
将传统关系型数据库、MongoDB和Redis的特点做一个简单对比。如下表所示,读写响应性能上,传统关系型数据库一般,MongoDB类似于磁盘读写的NoSQL数据库速度较快,基于内存存储的Redis数据库最快。但是传统关系型数据库应用范围广泛,后两者以互联网应用为主。在当前互联网环境下,许多大型网站需要这种处理高并发和高响应的内存数据应用。
|
|
|
|
|
|
传统关系型数据库和MongoDB、Redis的比较
|
|
|
|
Redis的数据库存储模式,是基于键值(Key-Value)基本存储原理,进行细化分类,构建了具有自身特点的数据结构类型。像MySQL这样的关系型数据库,表的结构比较复杂,会包含很多字段,可以通过SQL语句,来实现非常复杂的查询需求。而Redis客户只包含“键”和“值”两部分,只能通过“键”来查询“值”。正是因为这样简单的存储结构,也让Redis的读写效率非常高。键的数据类型是字符串,但是为了丰富数据存储的方式,方便开发者使用,值的数据类型很多,它们分别是字符串、列表、字典、集合、有序集合。在对数据进行各种命令操作之前,首先要掌握Redis的数据结构类型特点。
|
|
|
|
字符串是Redis数据库最简单的数据结构,形式如下表所示,字符串值的内容是二进制的,意味着可以把数字、文本、图片、视频等都赋给这个值,最大长度不能超过512MB。键名的命名要容易阅读,方便系统维护;键名不要太长,否则会影响数据库执行效率。
|
|
|
|
|
|
|
|
列表由若干插入顺序的字符串组成,支持存储一组数据。这种数据类型对应两种实现方法,一种是压缩列表,另一种是双向循环链表。列表中存储的数据量比较小的时候,列表就可以采用压缩列表的方式实现。压缩列表由Redis自己设计实现,类似于数组,通过一片连续的内存空间存储数据,在读写操作时只能从其两头开始(由链表的寻址方式所决定)。不过,它跟数组不同的一点是Redis允许存储的数据大小不同。如下表所示,将700010看作表头的第一个结点字符串数据,结尾是700012字符串。值的内容允许重复出现。列表可用于聊天记录、博客评论等无需调整字符串顺序但又需要快速响应的场景。
|
|
|
|
|
|
|
|
集合是由不重复且无序的字符串元素组成的整体,结构如下表所示,集合与列表最主要的区别是,集合里面所有字符串是唯一的;所有字符串的读写顺序是任意的,不存在从两头操作的问题。
|
|
|
|
|
|
|
|
散列表可以存储多个键值对的映射,是无序的一种数据集合。只有在数据存储数据量比较小的情况下,Redis才使用散列表进行操作,如下表所示。键的内容必须是唯一的,不能重复,且字符串不宜过长,以免占用过多内存,影响执行效率。使用“:”等隔离符号增加可读性,并给使用者提供更大的存储空间。值可以是字符串类型也可以是数字型。散列表特别适用于存储一个对象,会占更少的内存,并且方便存取整个对象。
|
|
|
|
|
|
|
|
有序集合的键被称为成员(member),每个成员都是各不相同的。有序集合的值则被称为分值(score),分值必须为浮点数。有序集合是Redis里面唯一一个既可以根据成员访问元素,又可以根据分值以及分值的排列顺序访问元素的结构,如下表所示。有序集合的值自动进行排序,键字符串必须唯一,值可以重复。由于采用自动值排序,在数据量较多的情况下,检索速度比散列表快。
|
|
|
|
|
|
|