|
|
|
在多用户共享系统中,许多事务可能同时对同一数据进行操作,称为并发操作,此时数据库管理系统的并发控制子系统负责协调并发事务的执行,保证数据库的完整性不受破坏,同时避免用户得到不正确的数据。
|
|
|
|
|
|
数据库的并发操作带来的主要问题有:丢失更新问题、不一致分析问题(读过时的数据)、依赖于未提交更新的问题(读脏数据)。这3个问题需要DBMS的并发控制子系统来解决。
|
|
|
|
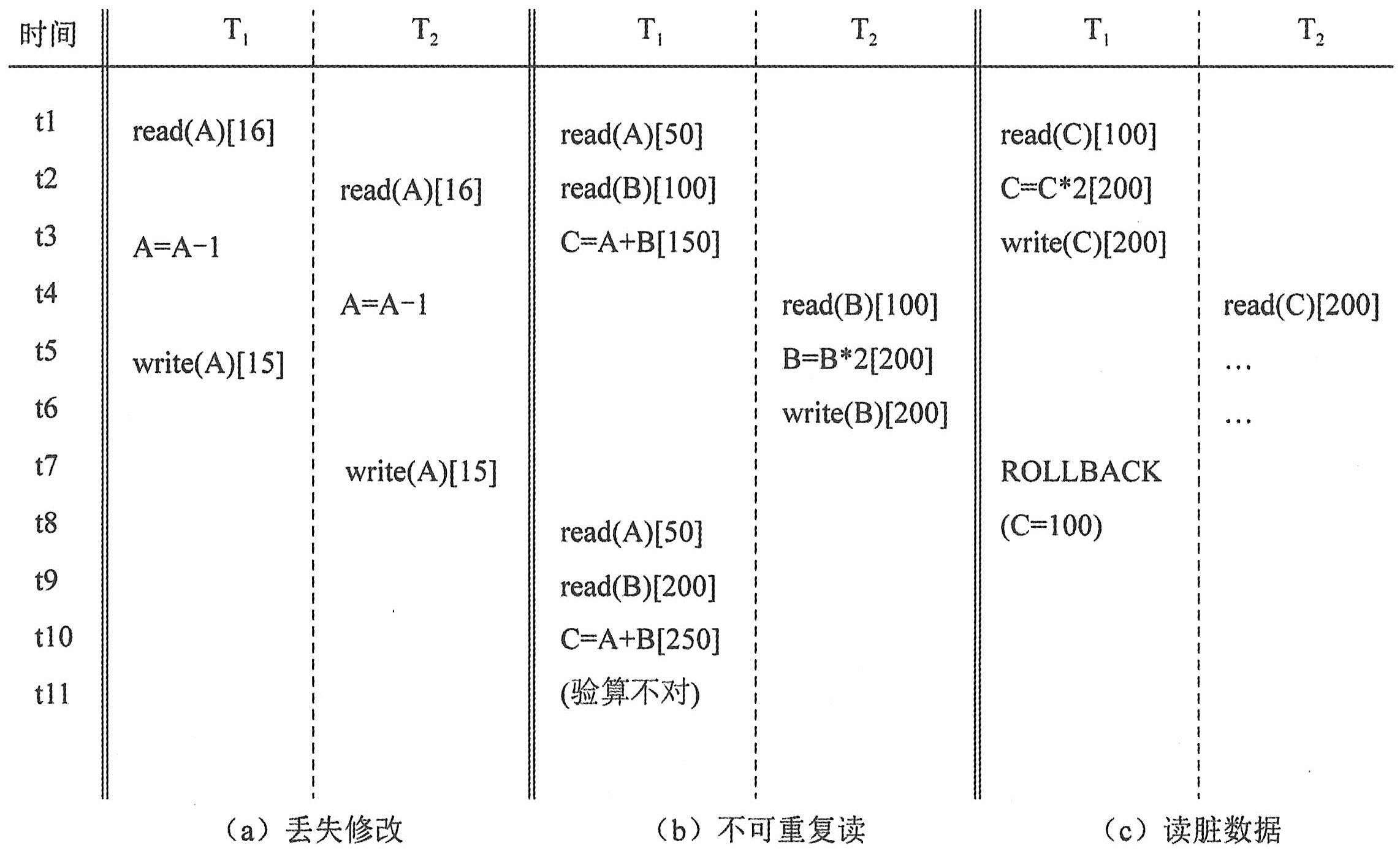
(1)丢失更新(丢失修改):两个事务T1和T2读入同一数据并修改,T2提交的结果破坏了T1提交的结果,T1的修改被丢失。
|
|
|
|
(2)读过时的数据(不可重复读):事务T1读取某一数据,事务T2读取并修改了同一数据,T1为了对读取值进行校对再读此数据,得到了不同的结果。例如,T1读取B=100,T2读取B并把B改为200,T1再读B得200,与第一次读取值不一致。
|
|
|
|
(3)读脏数据:事务T1修改某一数据,事务T2读取同一数据,而T1由于某种原因被撤销,则T2读到的数据就为“脏”数据,即不正确的数据。例如,T1把C由100改为200,T2读到C为200,而事务T1由于被撤销,其修改宣布无效,C恢复为原值100,而T2却读到了C为200,与数据库内容不一致。
|
|
|
|
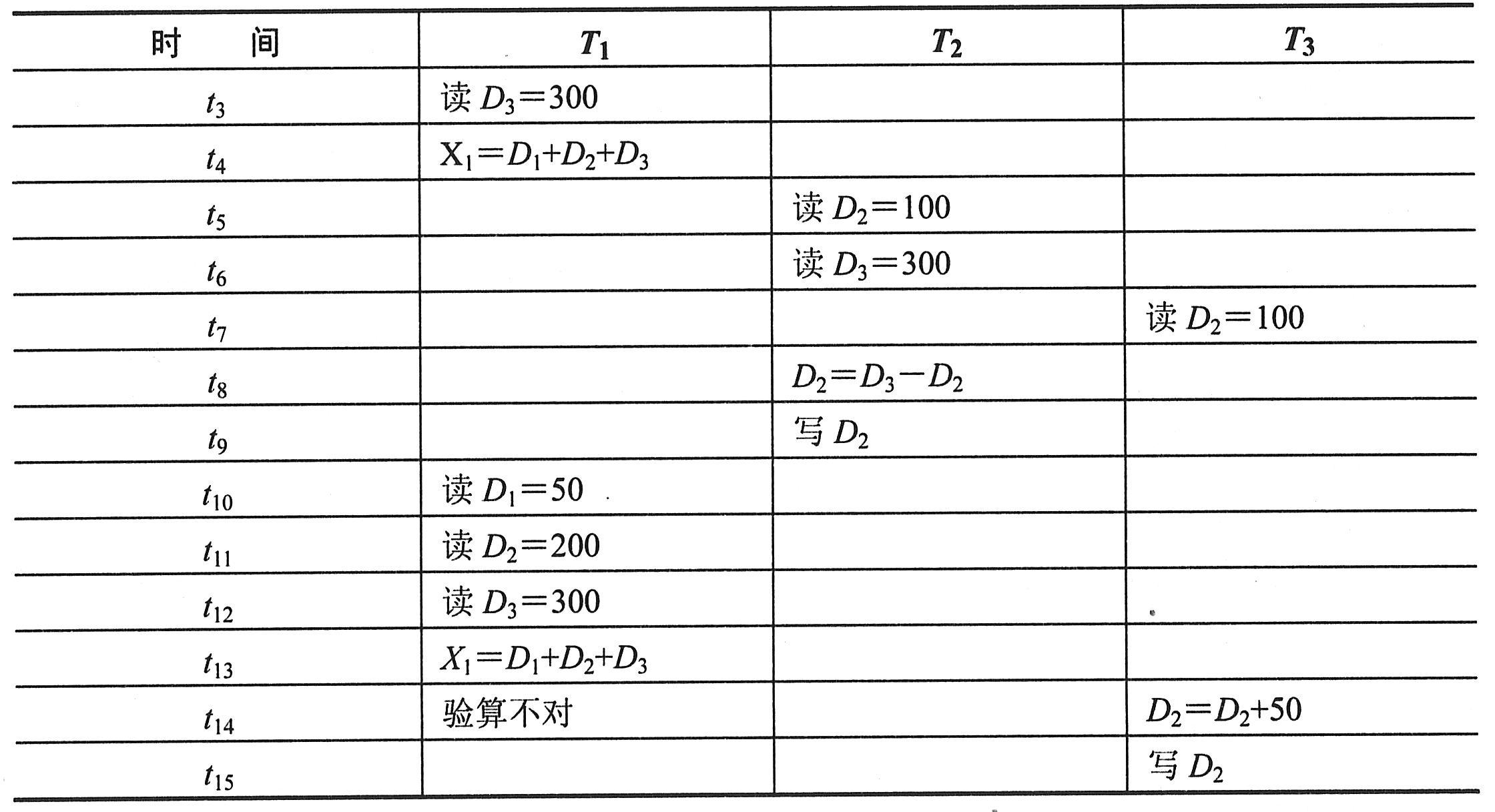
例如,假设某3个事务T1、T2和T3并发执行的过程如下表所示。
|
|
|
|
|
|
|
|
|
|
在上表中,事务T1、T2分别对数据D1、D2和D3进行读写操作,在t4时刻,事务T1将D1、D2和D3相加存入X1,X1等于450。在t8时刻,事务T2将D3减去D2存入D2,D2等于200。在t13时刻,事务T1将D1、D2和D3相加存入X1,X1等于550,验算结果不对。这种情况就属于不可重复读。在t14时刻事务T3将D2加50存入D2,D2等于150。这样,就丢失了事务T2对D2的修改,这种情况就属于丢失更新。
|
|
|
|
|
|
处理并发控制的主要方法是采用封锁技术,主要有两种类型的封锁,分别是X封锁和S封锁。
|
|
|
|
(1)排他型封锁(X封锁):如果事务T对数据A(可以是数据项、记录、数据集以至整个数据库)实现了X封锁,那么只允许事务T读取和修改数据A,其他事务要等事务T解除X封锁以后,才能对数据A实现任何类型的封锁。可见X封锁只允许一个事务独锁某个数据,具有排他性。
|
|
|
|
(2)共享型封锁(S封锁):X封锁只允许一个事务独锁和使用数据,要求太严。需要适当从宽,如可以允许并发读,但不允许修改,这就产生了S封锁概念。S封锁的含义是:如果事务T对数据A实现了S封锁,那么允许事务T读取数据A,但不能修改数据A,在所有S封锁解除之前决不允许任何事务对数据A实现X封锁。
|
|
|
|
|
|
在多个事务并发执行的系统中,主要采取封锁协议来进行处理。
|
|
|
|
(1)一级封锁协议:事务T在修改数据R之前必须先对其加X锁,直到事务结束才释放。一级封锁协议可防止丢失更新,并保证事务T是可恢复的,但不能保证可重复读和不读脏数据。
|
|
|
|
(2)二级封锁协议:一级封锁协议加上事务T在读取数据R之前先对其加S锁,读完后即可释放S锁。二级封锁协议可防止丢失更新,还可防止读脏数据,但不能保证可重复读。
|
|
|
|
(3)三级封锁协议:一级封锁协议加上事务T在读取数据R之前先对其加S锁,直到事务结束才释放。三级封锁协议可防止丢失更新、防止读脏数据与数据重复读。
|
|
|
|
(4)两段锁协议:所有事务必须分两个阶段对数据项加锁和解锁。其中,扩展阶段是在对任何数据进行读、写操作之前,首先要申请并获得对该数据的封锁;收缩阶段是在释放一个封锁之后,事务不能再申请和获得任何其他封锁。若并发执行的所有事务均遵守两段封锁协议,则对这些事务的任何并发调度策略都是可串行化的(可以避免丢失更新、不可重复读和读脏数据问题)。遵守两段封锁协议的事务可能发生死锁。
|
|
|
|
所谓封锁的粒度即是被封锁数据目标的大小,在关系数据库中封锁粒度有属性值、属性值集、元组、关系、某索引项(或整个索引)、整个关系数据库、物理页(块)等几种。
|
|
|
|
封锁粒度小则并发性高,但开销大;封锁粒度大则并发性低,但开销小。综合平衡照顾不同需求以合理选取适当的封锁粒度是很重要的。
|
|
|
|
|
|
采用封锁的方法固然可以有效防止数据的不一致性,但封锁本身也会产生一些麻烦,最主要就是死锁问题。死锁是指多个用户申请不同封锁,由于申请者均拥有一部分封锁权而又需等待另外用户拥有的部分封锁而引起的永无休止的等待。死锁是可以避免的,目前采用的办法有如下几种。
|
|
|
|
(1)预防法:采用一定的操作方式以避免死锁的出现,顺序申请法、一次申请法等即是此类方法。顺序申请法是指对封锁对象按序编号,用户申请封锁时必须按编号顺序(从小到大或反之)申请,这样能避免死锁发生;一次申请法是指用户在一个完整操作过程中必须一次性申请它所需要的所有封锁,并在操作结束后一次性归还所有封锁,这样能避免死锁的发生。
|
|
|
|
(2)死锁的解除法:允许产生死锁,并在死锁产生后通过解锁程序以解除死锁。这种方法中需要有两个程序,一个是死锁检测程序,用它测定死锁是否发生;另一个是解锁程序,一旦检测到系统已产生死锁,则启动解锁程序以解除死锁。
|
|
|