|
|
|
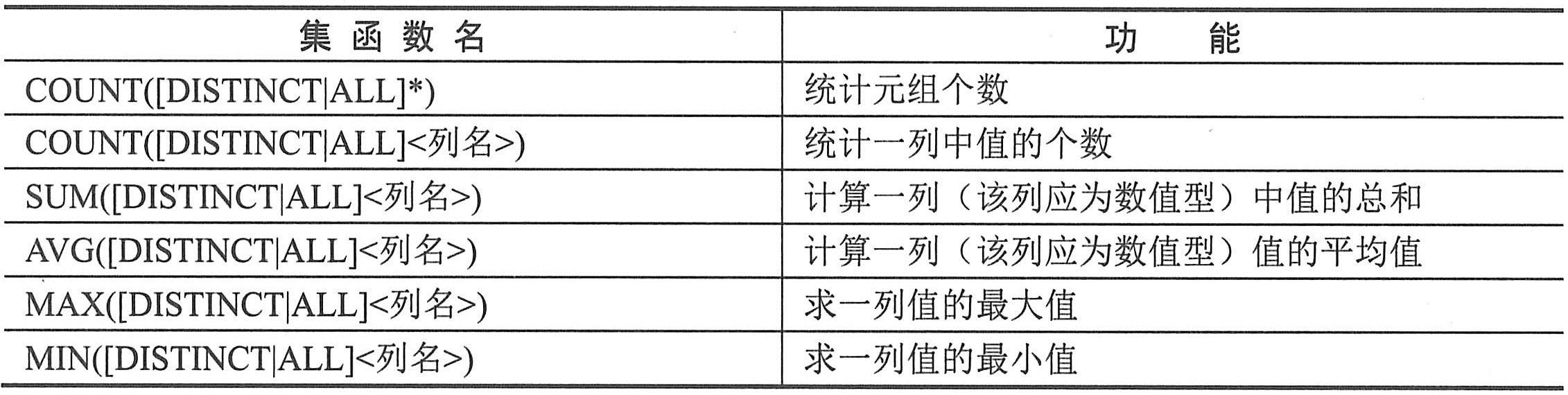
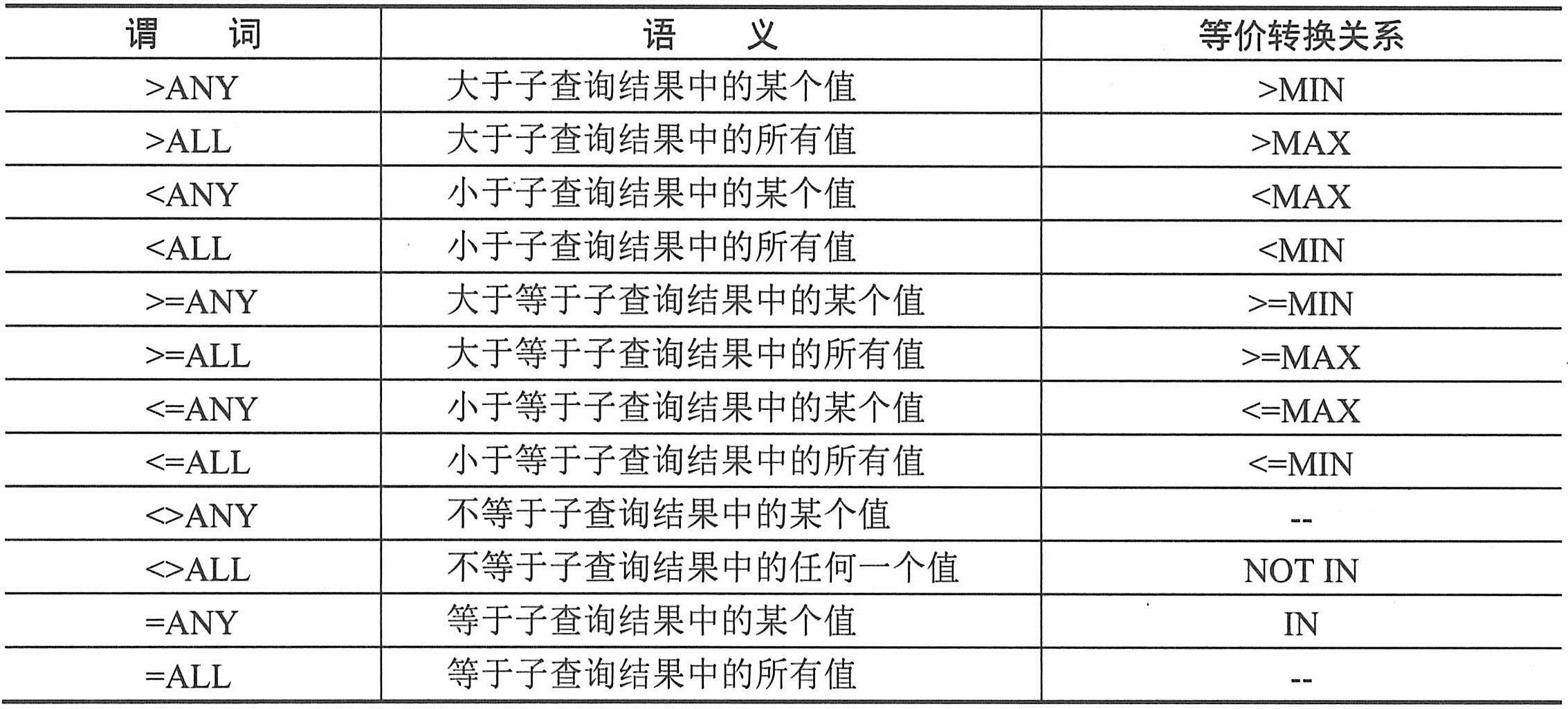
数据库的设计质量对整个系统的功能和效率有很大的影响。数据库设计的核心问题是:从系统的观点出发,根据系统分析和系统设计的要求,结合选用的数据库管理系统,建立一个数据模式。设计的基本要求是:
|
|
|
|
|
|
|
|
|
|
|
|
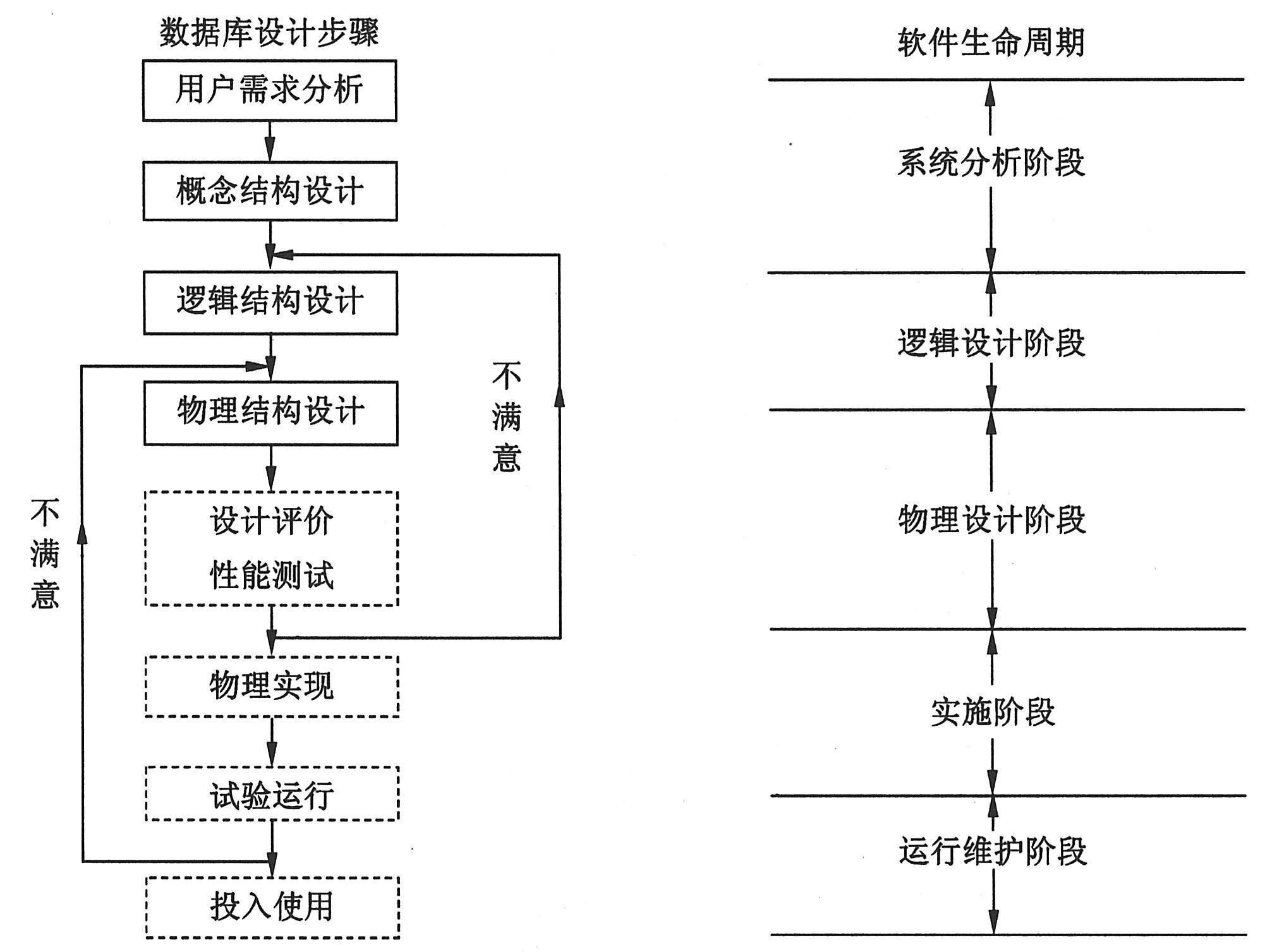
数据库的设计过程可以分为4个阶段,即用户需求分析、概念结构设计、逻辑结构设计和物理结构设计。下图反映和分析了这一设计过程,其中:
|
|
|
|
|
|
|
|
|
|
.概念结构设计是从现实世界向信息世界的转换。根据用户需求来进行数据库建模,也称为概念模型,常用实体关系模型表示。
|
|
|
|
.逻辑结构设计是从信息世界向数据世界的转化。将概念模型转化为某种数据库管理系统所支持的数据模型。
|
|
|
|
.物理结构设计是为数据模型选择合适的存储结构和存储方法。
|
|
|
|
|
|
用户需求分析需要结合具体的业务需求分析,确定信息系统的各类使用者以及管理员对数据及其处理、数据安全性和完整性的要求。主要设计如下三方面:
|
|
|
|
|
|
系统应用环境及系统所服务和运行的特殊组织环境。不同业务单位有不同的组织结构和业务工作流程。环境的特殊性将决定数据库的整体设计思路和风格。
|
|
|
|
|
|
用户需求及加工分析指用户希望从数据库中获得那些信息以及对信息的处理要求。由此决定数据库中应该存储哪些信息以及对数据需要进行哪些加工处理,包括在处理过程中特定的查询要求、响应时间要求,以及数据安全性、保密性、完整性和一致性等方面的要求,应在此基础上编制数据字典。
|
|
|
|
|
|
系统约束条件分析及分析现有系统的规模、结构、资源和地理分布,明确现有系统存在的种种限制或约束,从而使系统设计不至于脱离实际条件,确保系统设计顺利实施。
|
|
|
|
|
|
概念结构设计是指由现实世界的各种客观事物及其联系转化为信息世界中的信息模型的过程,即为数据库的概念结构设计。E-R模型即实体-联系模型是描述数据库概念结构的有力工具。下面结合实例说明E-R模型的构建。
|
|
|
|
在一个政府部门中存在着多个不同科室,每一个由若干名科员构成,每个科室都有一名主管上级领导,科室公务员负责为前来机关办事的群众提供相关的服务。现分别画出各个科室的E-R模型图,再画出整个机关的E-R模型。
|
|
|
|
|
|
|
|
(2)实体联系,主管领导与科室之间是一对多的关系,科室与科员之间的联系也是一对多的关系,科员与群众之间是多对多的关系。
|
|
|
|
|
|
.主管上级领导,属性可以有编号、姓名、性别、年龄、职务、任职时间、参加工作时间、入党时间、学历
|
|
|
|
|
|
.科员的属性包括编号、姓名、性别、年龄、职称、参加工作时间、入党时间、学历
|
|
|
|
|
|
|
|
通过以上分析,可以得到如下的E-R模型,如下图所示(部分属性)。
|
|
|
|
|
|
|
|
|
|
逻辑结构设计的任务是要将概念结构设计阶段完成的概念模型转换成能被选定的数据库管理系统支持的数据模型。现行的数据库管理系统一般支持网状、层次和关系三种数据模型中的一种,其中关系型的数据模型在DBMS中的应用和支持较为广泛,已成为主流。
|
|
|
|
下面简单介绍一下由E-R模型转换为关系数据模型的转化规则。在关系数据模型下,数据的逻辑结构是一张二维表,每个关系为一张二维表格。E-R模型转换为关系数据模型的转化规则如下。
|
|
|
|
.每一实体及其属性对应于一个关系模式。实体名作为关系名,实体的属性作为对应关系的属性。所谓关系模式,就是对关系的描述,用关系名(属性1、属性2、属性3,……属性n)来表示。
|
|
|
|
.两两实体之间的联系及其属性一般对应一个关系模式,联系名作为对应的关系名,联系的属性作为对应关系的属性;不带属性的联系可以去掉。
|
|
|
|
.实体和联系中关键字属性在关系模式中仍作为关键字。
|
|
|
|
上图中所示的实体关系图可以按照这些转换规则进行转化得到如下对应的关系模型。
|
|
|
|
.主管上级领导,编号、姓名、性别、年龄、职务、任职时间、参加工作时间、入党时间、学历
|
|
|
|
|
|
.科员,包括科室号、编号、姓名、性别、年龄、职称、参加工作时间、入党时间、学历
|
|
|
|
.群众,包括来访者编号、姓名、性别、年龄、来访日期、服务事宜
|
|
|
|
.服务,包括受理公务员编号、来访者编号、服务日期、服务事宜、处理结果
|
|
|
|
不同的系统配备的数据库管理系统性能不同,因而必须结合具体DBMS的性能和要求将一般数据模型转换成所选用的数据管理系统支持的数据模型,若选用的DBMS支持层次、网络模型,则还要完成从关系模型向层次或网络模型的转换。
|
|
|
|
|
|
数据库的物理设计以逻辑结构设计的结果为输入,结合关系数据库系统的功能和应用环境、存储设备等具体条件为数据模型选择合适的存储结构和存储方法。从而提高数据库的效率。物理结构设计的主要任务如下。
|
|
|
|
|
|
根据用户对数据结构和处理的要求,权衡数据存取时间、空间利用率和维护代价等三方面的利弊,综合考虑存储效率、维护成本等相关因素,从数据库管理系统提供的各种存储结构(例如顺序存储结构、索引存储结构,等等)中,选取合适的结构并加以实现。
|
|
|
|
|
|
数据库必须支持多个用户的多种应用,因此必须提供多个存取入口、多条存取路径,建立多个辅助索引。此过程中需要考虑一些问题,例如如何选取合适的数据项建立索引,如何建立辅助索引从而达到检索效率和存储空间的统一等。
|
|
|
|
|
|
按照不同的应用可将数据分为若干个组。根据各组数据利用频率和存储要求的不同,各类数据的存放位置、存储设备以及区域划分都应有所不同。应该把存取频率和存取速度要求较高的数据存储在高速存储器上,把存取频率和存取速度要求较低的数据存储在低速存储器上。
|
|
|
|
|
|
大多数据库管理系统会提供一些存储分配参数,例如溢出区大小、块大小、缓冲区大小和个数等,设计人员应全面考虑这些参数,以进行物理优化。
|
|
|
|
|
|
进行物理设计时不仅要考虑所选用数据库管理系统提供的安全机制和完整性约束,还要考虑用户使用制度、应用程序、计算机系统等各个涉及具体应用的方面。
|
|
|
|
|
|
数据库的物理设计阶段也要考虑数据库的恢复问题,采取必要的物理措施和手段,为突发事件和故障后的恢复做好准备,提供必要的物理工具。
|
|
|