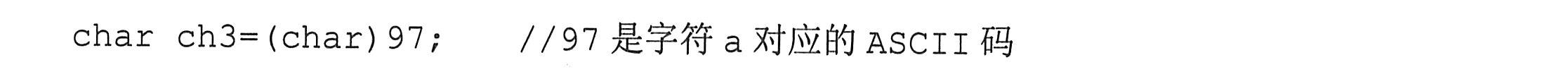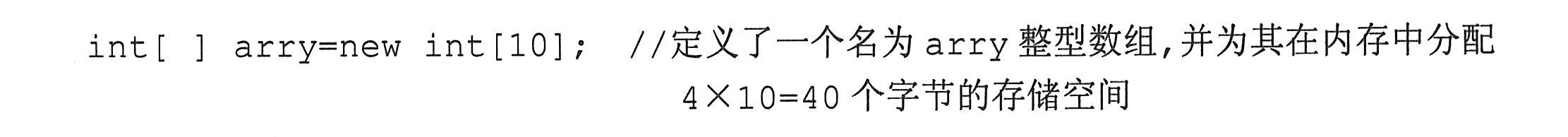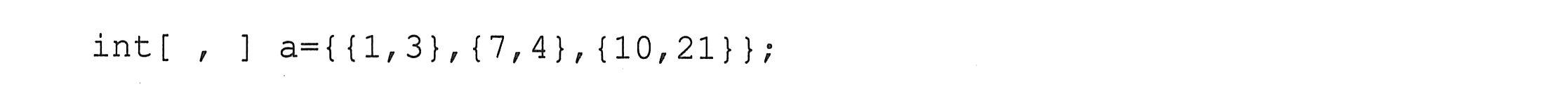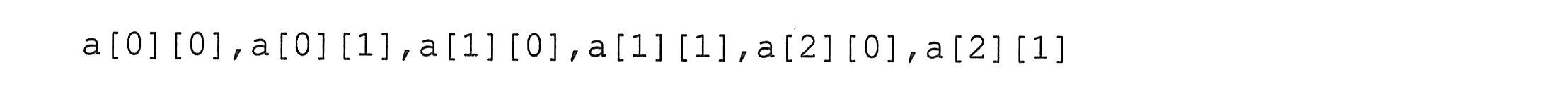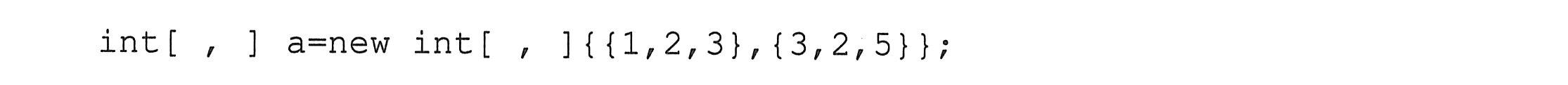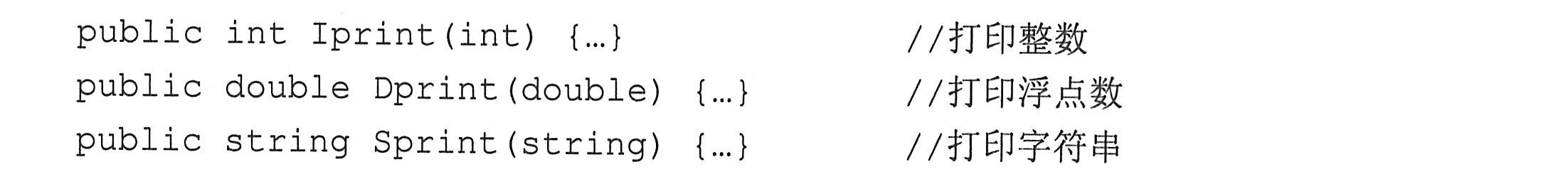|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
.NET是微软的新一代技术平台,根据微软的定义:.NET=新平台+标准协议+统一开发工具。从技术的角度,一个.NET应用是一个运行于.NET Framework之上的应用程序。更精确地说,一个.NET应用是一个使用.NET Framework类库来编写,并运行于公共语言运行时(Common Language Runtime)之上的应用程序。
|
|
|
|
.NET不仅可以管理代码的执行,而且能为代码提供服务,扮演双重角色。
|
|
|
|
其中.NET提供的服务包括:①.NET Framework,是.NET提供的一种新的运行环境;②ASP.NET,是为创建HTML页面而提供的一种新的编程模型;③Windows窗体,是为编写各种程序提供的新方法;④XML Web,为Internet服务器提供新的方法;⑤ADO.NET,支持数据库访问。
|
|
|
|
.NET Framework目标是成为新一代基于Internet的分布式计算应用开发平台。其框架层次结构如下图所示。
|
|
|
|
|
|
|
|
.NET框架支持多语言开发,便于建立Web应用程序及Web服务,加强Internet上各应用程序之间通过Web服务的沟通。
|
|
|
|
.NET框架主要包括三个主要组成部分:公共语言运行时(Common Language Runtime,CLR)、服务框架(Services Framework)以及应用模版。
|
|
|
|
其中,CLR管理了.NET中的代码,管理内存与线程;服务框架为开发人员提供了一套基于标准语言库的基类库,除了基类之外,包括接口、值类型、枚举和方法,可完成许多不同的任务,以简化编程工作;应用模版包括传统的Windows应用程序模板(Windows Forms)和基于ASP.NET的面向Web的网络应用程序模板(Web Forms和Web Services)。
|
|
|
|
|
|
|
|
面向对象编程(Object-Oriented Programming,OOP)技术是当今占主导地位的程序设计思想和技术,也是开发电子商务平台中使用的重要技术。面向对象程序设计首先针对问题要处理的数据特征找出相应的数据结构,然后设计解决问题的各种算法,并将数据结构和算法看做一个有机的整体,即“类”。由“类”可以实例化出一个或者多个对象,每个对象各尽其职,分别执行一组相关任务。OOP对问题的分析和解决基于两个原则:抽象和分类。
|
|
|
|
面向对象程序是由许多对象组成,对象是程序的实体,这个实体包含了对该对象属性的描述(数据结构)和对该对象进行的操作(算法)。
|
|
|
|
|
|
(1)封装。封装是面向对象编程的特征之一,也是类和对象的主要特征。封装将数据以及加在这些数据上的操作组织在一起,成为有独立意义的构件—类。外部无法直接访问这些封装了的数据,从而保证了这些数据的正确性。
|
|
|
|
(2)继承。面向对象编程语言的重要特点就是“继承”。从编程角度来说,如果类A继承类B,类A称为子类,类B称为父类,子类继承父类成为一个新类,直接获得父类的方法和属性,并在无需重新编写原来的类的情况下对这些功能进行扩展,是软件重用的重要方式。因此,一个子类完整的内容往往包括:从父类继承而来的成员;自身添加的成员;父类成员不符合要求而重写的成员。
|
|
|
|
(3)多态。多态是指面向对象程序运行时,相同的信息可能会送给多个不同的类型的对象,而系统可依据对象所属类型,引发对应类型的方法,而有不同的行为。简单来说,所谓多态意指相同的信息给予不同的对象会引发不同的行为。
|
|
|
|
|
|
|
|
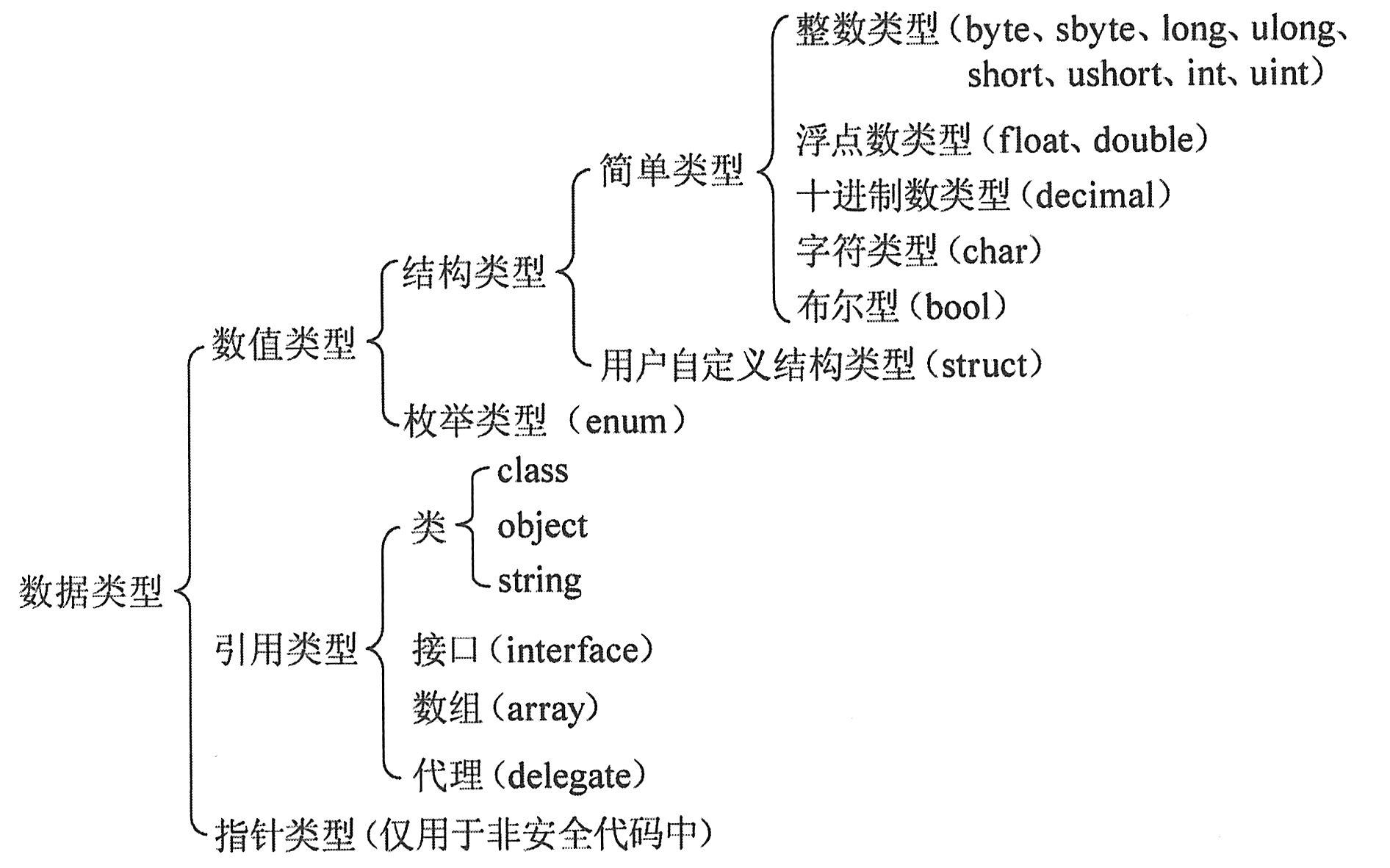
C#语言将数据分为不同的类型,它们分别表示不同范围、不同精度、不同用途的数据。C#语言数据类型体系如下图所示。
|
|
|
|
|
|
|
|
C#语言中具有数值类型的变量存储的是数值数据,而引用类型的变量则只存储数据的存储单元地址。
|
|
|
|
|
|
常量(Constant)是指在程序的运行过程中值不能改变的量。
|
|
|
|
|
|
|
|
变量是计算机内存中被命名的数据存储单元,其中存储的值是可以改变的。在程序中通过变量名来引用其中存储的信息。
|
|
|
|
在C#中,变量名必须遵守以下规则:变量名不能与C#中的库函数名称相同;首字符必须是字母、下画线或者“@”;区分大小写;变量名不能与C#关键字名相同。
|
|
|
|
C#规定在程序中所有用到的变量都必须在程序中定义,即遵守“先定义后使用”或“先声明后使用”的原则。
|
|
|
|
|
|
|
|
定义好的变量不能直接被用来使用和计算,需要先对其进行初始化才能使用。也就是说变量需要先赋值再使用。
|
|
|
|
|
|
|
|
|
|
整数类型是指那些没有小数部分的数字,包括整数常量和整数变量。
|
|
|
|
|
|
|
|
.十六进制数:这类数据以“0x”(其中0是数字0)开头,如:0x61,表示十六进制的61,相当于十进制数据97。
|
|
|
|
变量间进行赋值运算要注意其存储范围,一旦超出存储范围,否则会发生“溢出”现象,使程序报错。
|
|
|
|
|
|
在C#中,无论是字符类型常量还是字符类型变量,都是使用Unicode编码中的字符。
|
|
|
|
可使用关键字char来定义字符类型数据。char类型的变量占用2个字节的内存。
|
|
|
|
|
|
字符常量是用单引号括起来的一个字符。如‘s’、‘x’、‘Y’等都是字符常量。
|
|
|
|
除了以上形式的字符常量外,还允许使用一种特殊形式的字符常量,就是以一个“\”开头的“转义字符”。例如,字符‘\n’代表换行,‘\t’代表跳格等。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
float数据类型使用4个字节的内存来存储数字,float型绝对值的最小值是1.5×10-45这表示在小于1.5×10-45和大于-1.5×10-45之间的数据是无法表示的。float型精度为7位有效数字。
|
|
|
|
|
|
double类型的变量占用8个字节的内存,精度为15~16位有效数字。
|
|
|
|
|
|
C#提供了decimal类型。这是一个占用16个字节(128位)的数据类型,适用于金融货币计算,精度为28~29位有效数字。与其他数据类型不同的是,decimal没有无符号形式。
|
|
|
|
|
|
布尔类型是一种用来表示“真”和“假”的逻辑数据类型。布尔类型占用1个字节的内存。布尔类型变量只有两种取值:true(代表“真”),false(代表“假”)。
|
|
|
|
|
|
C#提供了两种主要的信息存储方式:按值(by value)和按引用(by reference)。
|
|
|
|
当变量按值存储信息时,变量将包含实际的信息。当变量按引用存储信息时,存储的不是信息本身,而是信息在内存中的存储位置。
|
|
|
|
C#语言中属于引用类型的数据类型有:对象类型(object)、类类型(class)、字符串类型(string)、接口类型(interface)、数组类型(array)、代理类型(delegate)。
|
|
|
|
|
|
字符串类型的变量是由关键字string来定义的,它是类System.String的别名。
|
|
|
|
字符串类型也有常量和变量之分。字符串变量由关键字string来定义,而字符串常量用“”括起来表示,例如“jack”。
|
|
|
|
|
|
|
|
|
|
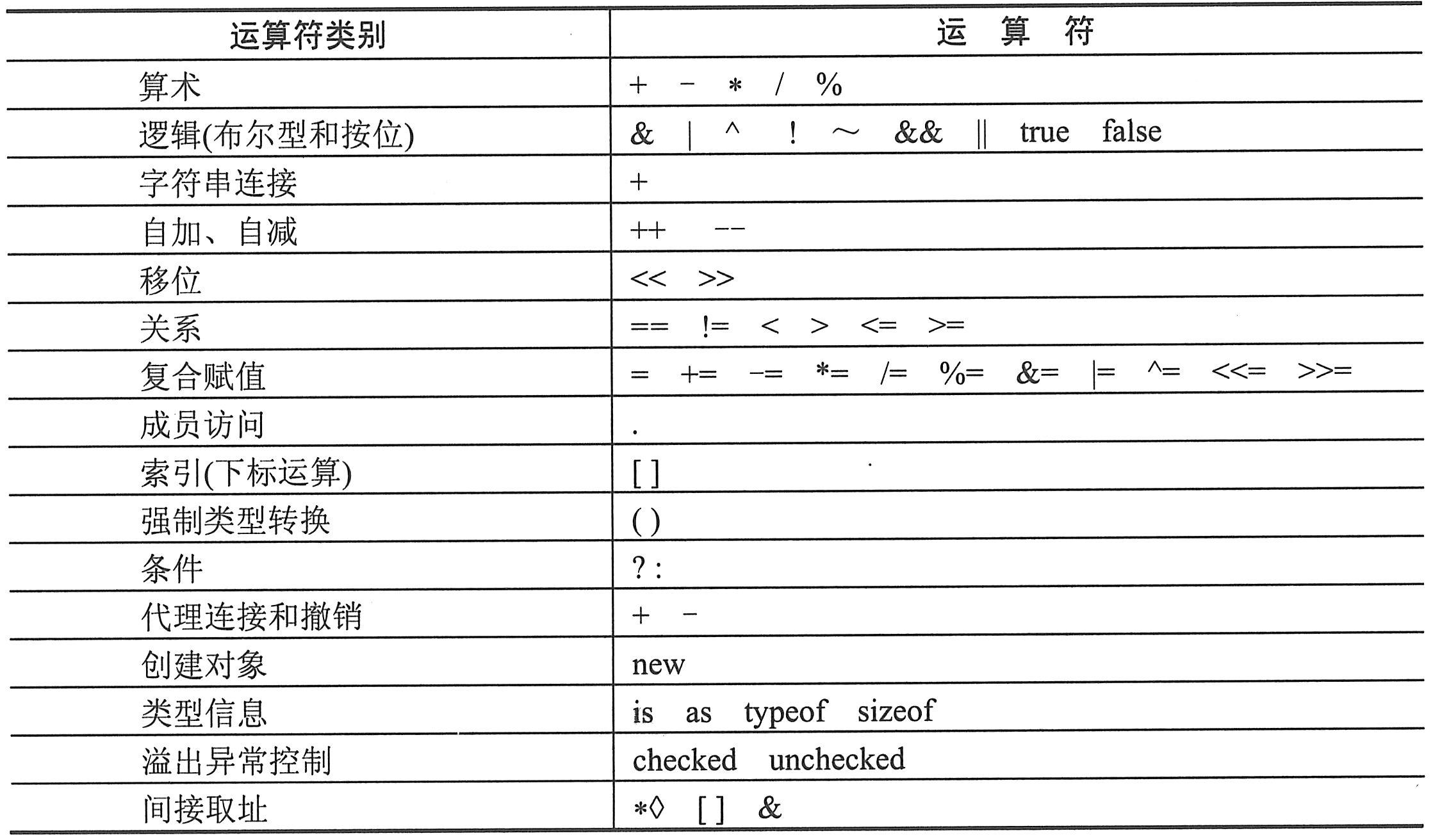
C#语言包括以下3种类型的运算符:单目运算符(带有1个操作数);双目运算符(带有2个操作数);三目运算符(带有3个操作数),目前只有条件运算符“?:”是三目运算符。
|
|
|
|
|
|
|
|
|
|
当一个表达式含有多个运算符时,运算符的优先级就控制了单个运算符的求值顺序。给出了运算符从高到低的优先级如下表所示。
|
|
|
|
|
|
|
|
|
|
|
|
C#提供了复合赋值运算符(如上表所示),例如:x+=10;等价于赋值语句:x=x+10;
|
|
|
|
|
|
算数运算符包括基本算术运算符“+、-、*、/、%”和自加自减运算符“++、--”等。
|
|
|
|
|
|
参与运算的操作数都是数字时,加法运算同一般的数学运算是一致的。参与运算的操作数都是字符串,相加的结果是两字符串连接在一起。参与运算的操作数分别是数字和字符串,得到的结果是将数字转变为字符串,然后将两个字符串连接在一起。
|
|
|
|
|
|
自增运算符++将操作数的值自动加1,自减运算符--将操作数的值自动减1。含有自增和自减运算符表达式的两种应用形式:
|
|
|
|
y=++(或--)x:先将x值做++(或--)运算,然后再赋值给y;
|
|
|
|
y=x++(或--):先将x值赋给y,然后再将x值做++(或--)运算。
|
|
|
|
|
|
一般来说,所有的数值类型都可以参与乘、除法运算,但在进行乘法运算时需考虑其运算结果是否超越了数据类型所能够容纳的最大值。如果超出则会发生溢出现象,程序无法通过编译。
|
|
|
|
|
|
|
|
第一,对于除数和被除数都是正数(包括正整数和正浮点数),将除数和被除数做减法,直到得到的结果小于被除数,这时的结果就是取余运算的结果。
|
|
|
|
第二,对于负数或负浮点数的取余运算,如果除数和被除数互相异号,即除数和被除数一个是正数一个是负数,则将除数和被除数做加法,直到得到的结果的绝对值小于被除数的绝对值为止,这时得到的结果就是取余运算的结果;如果除数和被除数都是负数,则按照两者都是正数时的运算方法求余数,判断终止取余运算同样也使用绝对值。
|
|
|
|
|
|
比较运算符“<、>、>=、<=”是二目运算符,作用是比较两操作数的大小。其操作数可以是所有的数值类型变量,比较的结果是“true”或“false”。相等运算符“==”和不等运算符“!=”是用来判断操作数是否相等或不等。等式运算的操作数可以是数值类型变量,也可以是引用类型变量。
|
|
|
|
|
|
“&&”运算符表示逻辑“与”,它被用于判断是否同时满足两个或两个以上的条件的时候。其操作数可以是布尔类型变量或关系表达式。在一个“与”操作中,如果第一个操作数是假,则不管第二个操作数是什么值,结果都是假。
|
|
|
|
“||”运算符表示逻辑“或”,它用来判断是否满足两个或两个以上的条件之一,其操作数可以是布尔类型变量或关系表达式。在一个“||”操作中,如果第一个操作数是真,则不管第二个操作数是什么值,结果都是真。
|
|
|
|
“!”运算符是一个一元运算符,表示逻辑非。同样,其操作数可以是布尔类型变量或者关系表达式。
|
|
|
|
|
|
条件运算符“?:”是唯一的一个三目运算符,它需要3个操作数。
|
|
|
|
条件运算表达式的一般格式是:关系表达式?表达式1:表达式2
|
|
|
|
功能:如果关系表达式的值是true,则条件运算表达式得到的值为表达式1的值,否则为表达式2的值。
|
|
|
|
|
|
程序的执行过程控制是算法思路实现的逻辑路径,是程序设计的核心。根据结构化程序设计思想,程序的流程主要由3种基本结构组合而成:顺序结构、选择结构和循环结构,它们是现代程序设计的基础。
|
|
|
|
|
|
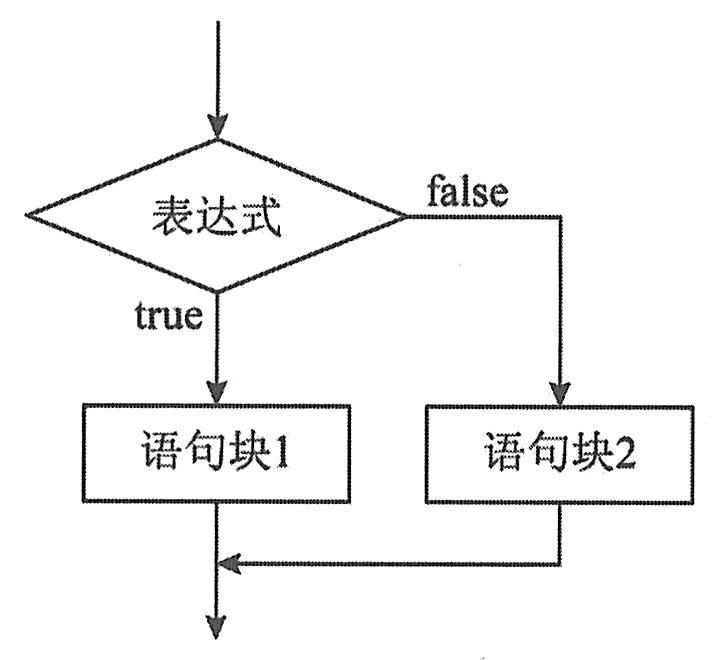
在C#语言中,提供了两种选择结构程序设计的语句结构:if-else语句和switch语句。它们的作用就是根据某个条件是否成立,控制程序的执行流程。
|
|
|
|
|
|
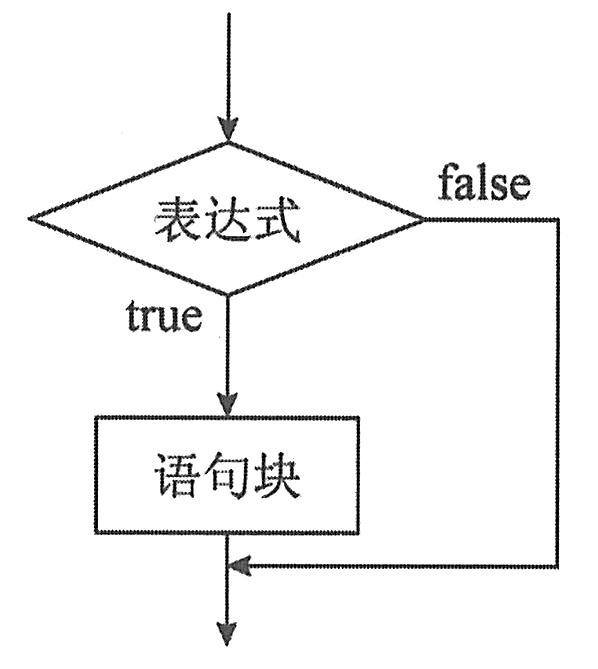
if语句是最常用的选择语句,它的功能是根据所给定的条件(常由关系、布尔表达式表示)是否满足,决定是否执行后面的操作。
|
|
|
|
|
|
功能:如果表达式的值为真(即条件成立),则执行if语句所控制的语句块;如果表达式的值为假(即条件不成立),则直接执行语句块后面的语句。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
功能:如果表达式成立,则执行语句组1,然后执行语句组2的下一条语句。如果表达式不成立,则跳过语句组1,执行语句组2,然后执行语句组2的下一条语句。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
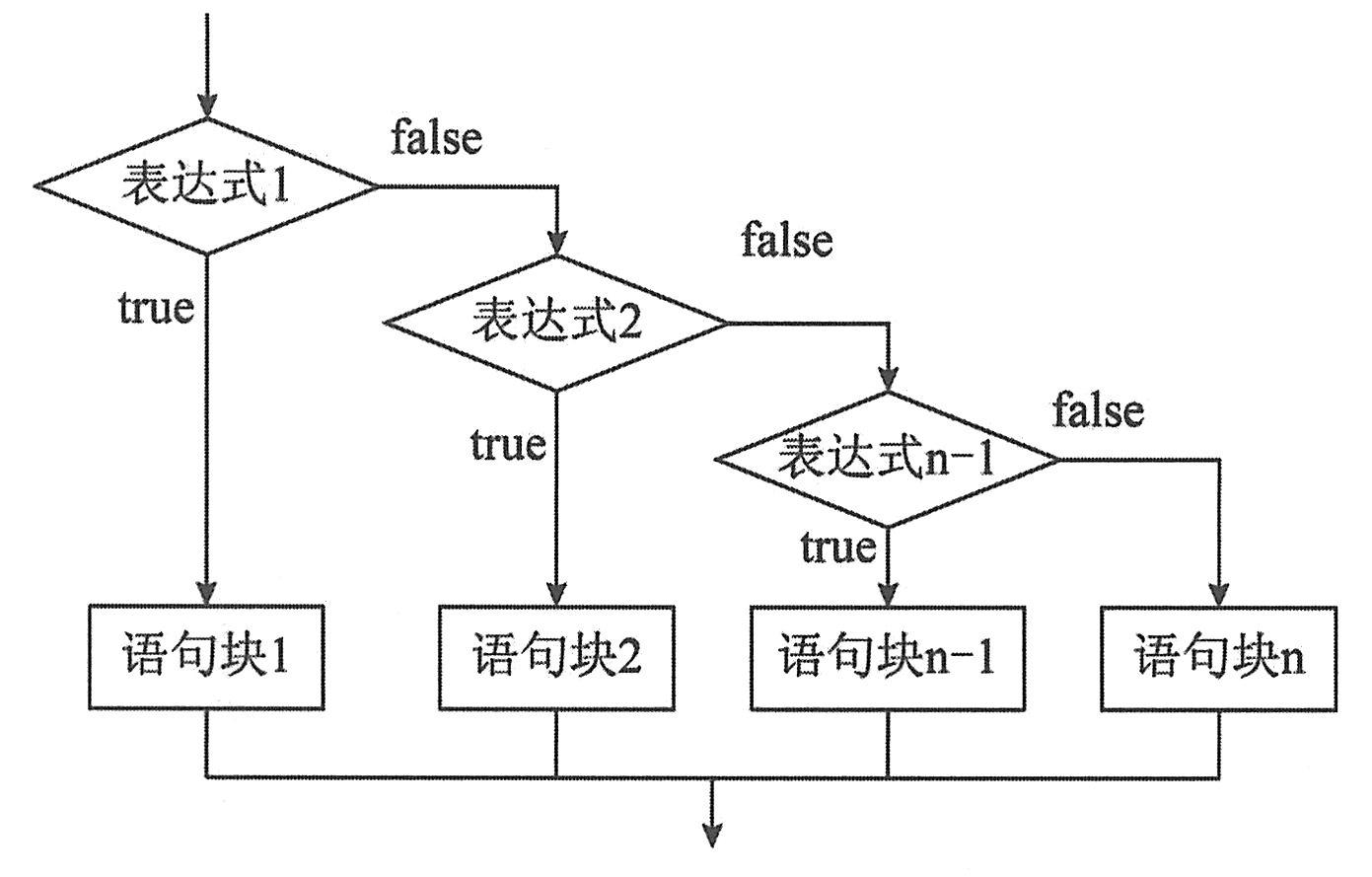
功能:当表达式1为真时,执行语句组1,然后跳过整个结构执行下一个语句;当表达式1为假时,跳过语句组1去判断表达式2。若表达式2为真时,执行语句组2,然后跳过整个结构去执行下一个语句;若表达式2为假时,则跳过语句组2去判断表达式3。以此类推,当表达式1、表达式2……表达式n-1全为假时,则执行语句组n,再转而执行下一条语句。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
“表达式”也可以是变量,但必须是能计算出具体的“常量表达式”表示的量。
|
|
|
|
“常量表达式”是“表达式”的计算结果,可以是整型数值、字符或字符串。switch语句的执行过程:首先计算switch后面的表达式的值。其次,将上述计算出的表达式的值依次与每一个case语句的常量表达式的值比较。如果没有找到匹配的值,则进入default,执行语句组n+1;如果没有default,则执行switch语句后的第一条语句;如果找到匹配的值,则执行相应的case语句组语句,执行完该case语句组后,整个switch语句也就执行完毕。因此,最多只执行其中的一个case语句组,然后将执行switch语句后的第一条语句。
|
|
|
|
|
|
在程序中除了使用语句改变流程外,有时还需要重复执行某个代码段多次。为了实现重复执行代码的功能,C#提供了while、do-while、for和foreach-in 4种循环语句。
|
|
|
|
|
|
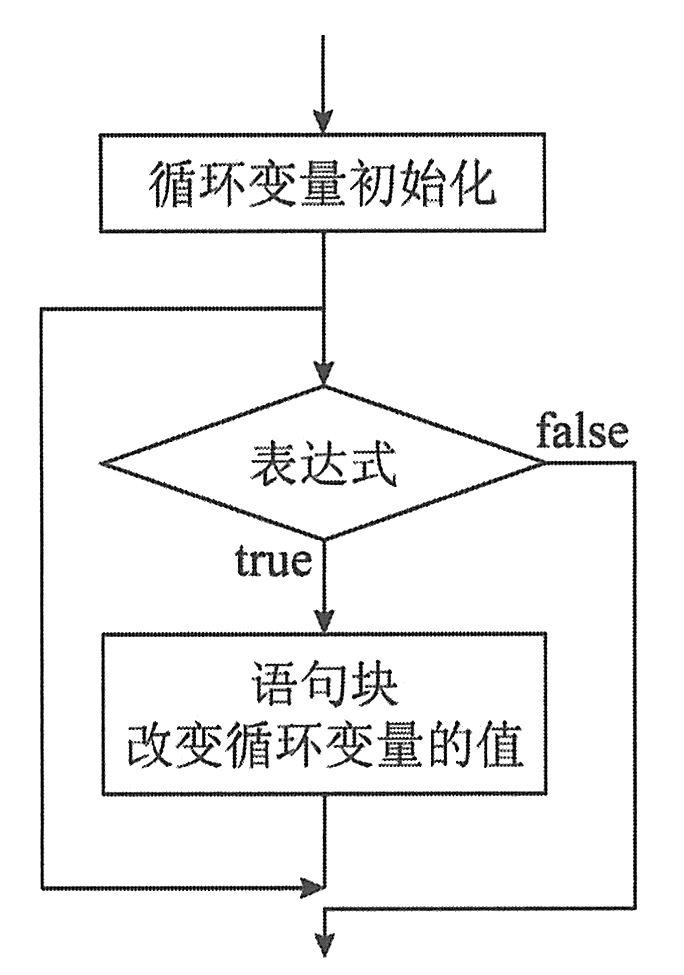
while语句可用来实现当条件为“真”时,不断重复执行某个代码块的功能,其语句格式为:
|
|
|
|
|
|
|
|
|
|
②如表达式的值为真,则执行循环体“语句块”,并改变控制循环变量的值。
|
|
|
|
③返回while语句的开始处,重复执行步骤a和b,直到表达式的值为假,跳出循环并执行下一条语句。
|
|
|
|
|
|
|
|
|
|
|
|
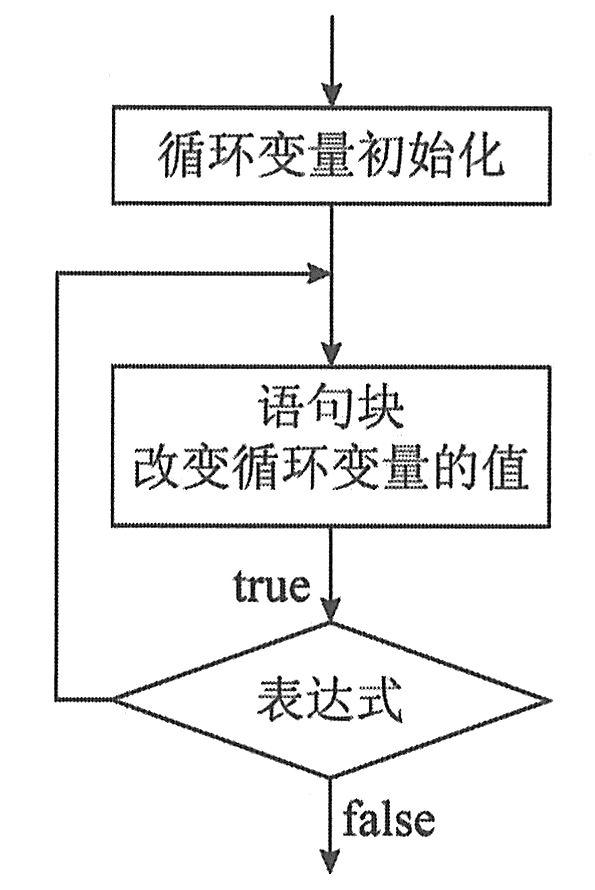
do-while语句的特点是先执行循环,然后判断循环条件是否成立。其语句格式为:
|
|
|
|
|
|
|
|
①当程序执行到do语句后,就开始执行循环体语句块,并改变循环变量的值。
|
|
|
|
②执行完循环体语句后,再对while语句括号内的条件表达式进行判断。若表达式条件成立(为真),转向步骤a继续执行循环体语句;否则退出循环,执行下一条语句。
|
|
|
|
|
|
|
|
|
|
|
|
do-while语句不论条件表达式的值是什么,其循环体语句都至少要执行一次,而while语句只有当条件表达式的值为真时,才执行循环体语句,如果条件表达式一开始就不成立,则循环体语句一次都不必执行。总之,do-while循环是先执行循环体,后判断条件表达式是否成立;而while语句是先判断条件表达式,再决定是否执行循环体。
|
|
|
|
|
|
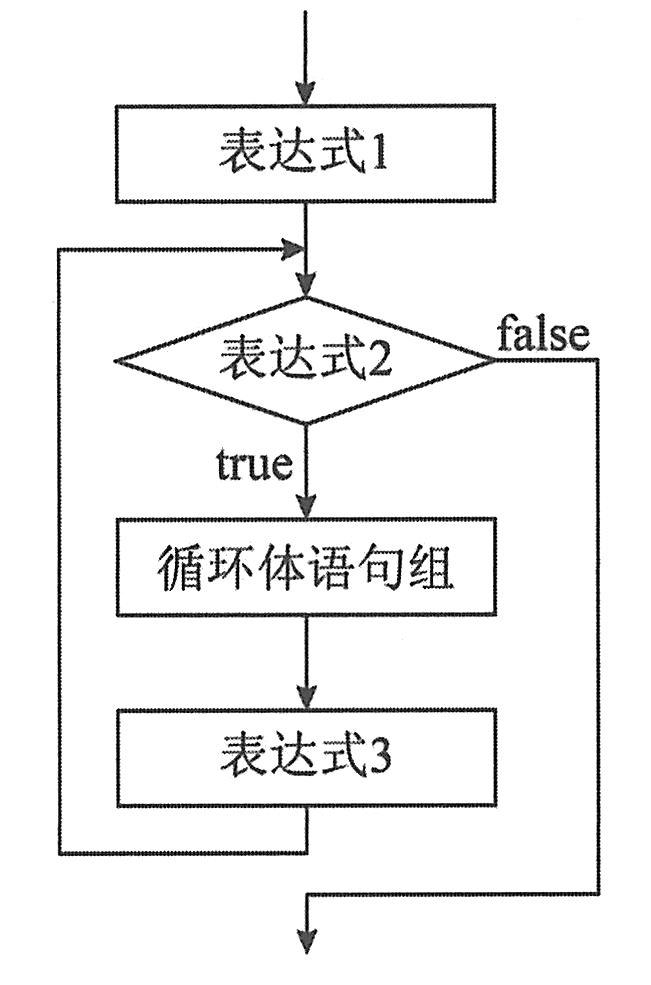
for语句是构成循环最灵活简便的一种方法。for语句的一般格式为:
|
|
|
|
|
|
|
|
|
|
②求解表达式2的值,若表达式2条件成立,则执行for语句的循环体语句组,然后执行下面的第c步;若条件不成立,则转到第e步。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
break语句通常用在switch语句和各种循环语句中。
|
|
|
|
|
|
在switch语句中,break语句的作用是使程序流程跳出switch语句结构。在各种循环语句中,break语句的作用是使程序中止整个循环。注意,如是多重循环,break不是使程序跳出所有循环,而只是使程序跳出break本身所在的循环。
|
|
|
|
continue语句用于各种循环语句中,continue语句的使用格式为:continue;
|
|
|
|
continue语句的作用是跳过循环体中剩余的语句而强行执行下一次循环。
|
|
|
|
continue语句与break语句的区别:continue语句用于结束本次循环,即跳过循环体中continue语句下面尚未执行的语句,再判断表达式的条件,以决定是否执行该循环体的下一次循环。而break语句则是终止当前整个循环,不再进行条件表达式的判断。在while和do-while语句中,continue语句用于把程序流程转至执行条件测试部分,而在for循环中,则转至表达式3处,以改变循环变量的值。
|
|
|
|
|
|
数组是一种一对多的数据类型,即它是可以存储多个同类型值(或元素)的单个数据类型,其中所有的值(或元素)可以通过数组的下标来访问,并且这些元素在内存中占据着一块连续的存储空间,这里介绍一维数组和二维数组。
|
|
|
|
|
|
同变量一样,数组也必须“先定义,后使用”。定义一维数组的格式如下:
|
|
|
|
|
|
方括号“[]”在这里表示是定义一个数组,而不是普通的一个变量或对象。
|
|
|
|
例如:int[]arry;定义了一个名为arry的整型数组,意味着该数组可用来存放多个整数,但此时并没有为存储变量分配空间。在C#语言中,定义数组后必须对其初始化(为数组分配内存空间)才能使用。初始化数组有两种方法:静态初始化和动态初始化。
|
|
|
|
①静态初始化。如果数组中包含的元素不多,且初始元素值是已知的,则可以采用静态初始化方法。静态初始化数组时,必须与数组定义结合在一起,否则会报错。
|
|
|
|
|
|
|
|
②动态初始化。动态初始化需用new关键字将数组实例化为一个对象,再为该数组对象分配内存空间,并为数组元素赋初值。动态初始化数组的格式为:
|
|
|
|
|
|
|
|
|
|
|
|
当定义完一个数组,并对其初始化后,就可以引用数组中的元素了。一维数组的引用方式是:
|
|
|
|
|
|
数组的下标是元素的索引值,它代表了要被访问的数组元素在内存中的相对位置,就是从数组的第1个元素到某个数组元素的偏移量。在C#中数组元素的索引是从0而不是1开始的,如数组arry的第1个元素是arry[0],第2个元素是arry[1],以此类推。
|
|
|
|
|
|
在C#语言中,多维数组可看作是数组的数组,即高维数组中的每一个元素本身也是一个低维数组,二维数组的定义格式:
|
|
|
|
|
|
二维数组也包括两种初始化方法,即:静态初始化和动态初始化,并且其初始化形式也非常相似。
|
|
|
|
例如,以下定义一个3行2列的整型二维数组并对其静态初始化:
|
|
|
|
|
|
二维数组经过初始化后,其元素在内存中将按一定的顺序排列存储。二维数组的存储序列为按矩阵的“行”顺序存储,例如上例中a数组的存储顺序为:
|
|
|
|
|
|
|
|
|
|
|
|
在动态初始化二维数组时,也可直接为其赋予不同的初始值。例如:
|
|
|
|
|
|
与一维数组类似,二维数组也是通过数组名和下标值来访问数组元素的。唯一与一维数组不同的是,二维数组需由两个下标来标识一个数组元素,二维数组的引用形式为:
|
|
|
|
|
|
例如:a[2,3]表示是a数组的第3行、第4个元素。
|
|
|
|
|
|
类是C#语言实现面向对象程序设计的基础,它是C#封装的基本单元,类把对象、属性和方法这些类成员封装在一起构成一个有机整体,即数据结构。当类的成员定义为保护或私有(protected或private)时,外部不能访问;定义为公有(public)时,则任何用户均可访问。
|
|
|
|
|
|
在C#中用关键字class来定义类,其基本格式为:
|
|
|
|
|
|
类是由数据成员和函数成员组成,它们分别是面向对象理论中类的属性和方法。类的数据成员包含类的常量成员和类的变量成员,它们可以是前面介绍的任何数据类型的变量,甚至可以是其他类。
|
|
|
|
类成员的访问权限用来限制外界对某一个类成员的访问。类成员的访问权限有以下几种:
|
|
|
|
|
|
.private:不允许外界访问,也不允许派生类访问,只能在定义该成员的类中调用。
|
|
|
|
.protected:只允许在定义该成员的类或其派生类的内部被调用。
|
|
|
|
.internal:使用该声明符的类型或成员只允许在同一程序集内访问。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
定义(构造)一个Point类的对象StringPoint,并为该对象分配存储空间。
|
|
|
|
|
|
类数据成员在C#中用来描述一个类的特征,即面向对象理论中类的属性。C#中有两类数据成员,一类是常量成员,另一类是变量成员。
|
|
|
|
在某个类中定义的常量就是这个类的常量成员,这个类的所有其他成员都可以使用这个常量来代表某个值。
|
|
|
|
|
|
|
|
在应用中,一般将变量成员分为两类,静态变量成员(带static修饰符定义的变量)和非静态变量成员(又称为实例变量成员,即定义时不带static修饰的)。
|
|
|
|
|
|
方法是指类中用于对数据进行某种处理操作的算法,它就是实现某种功能的程序代码模块,在C/C++中称作函数,在面向对象编程技术中,将函数称为方法。在方法中,代码必须是结构化的。方法是访问、使用私有成员变量的途径。在C#中,方法与它操作的对象封装在一起构成类,所以方法是类的成员。在一个类中定义成员方法的格式为:
|
|
|
|
|
|
|
|
在程序中调用方法都是通过方法名来实现的,如果对于具有相同功能而参数不同的方法取不同的方法名,不但会降低程序员编写程序的效率,也降低了程序的可读性。
|
|
|
|
例如,以下是一些执行打印不同数据类型数据的打印方法,各种方法取不同的方法名。
|
|
|
|
|
|
以上3个方法都是执行打印功能,但却使用了3个不同的方法名,给编写、阅读和调用程序都带来了不便,如能使用同一个方法名,则会方便得多。在C#语言中,可以在同一个类的内部定义多个名字相同而参数表不同的方法,这就是所谓的方法重载。换个说法,实现用同名的方法对不同类型的数据做不同的运算,就称为方法重载。
|
|
|
|
使用方法重载技术后,上述3个打印的方法可以如下定义:
|
|
|
|
|
|
对于重载的方法,C#是通过方法中的参数匹配来决定调用哪个方法。所以调用方法时的参数类型、属性和个数一定要与类中将要被调用的方法的参数列表对应,这样才能实现正确调用。
|
|
|
|
|
|
“继承”机制使我们能用一种简单的方式来描述事物。例如可以这样描述菱形:菱形是一种一组邻边相等的平行四边形。这里表明:菱形是由平行四边形类派生出来的,它是平行四边形类中的一种,即菱形继承了平行四边形的特性(两组对边分别平行的四边形),但它又同时具有自己的特征(有一组邻边相等)。“一组邻边相等”是菱形区别于平行四边形类中其他子类的属性。所以当我们已描述了平行四边的特征,再描述菱形时,只要举出菱形的个性化特征,就完全可以让人们理解什么叫菱形了。由此我们可以说,菱形继承了平行四边形的特征,或者说平行四边形派生了菱形。
|
|
|
|
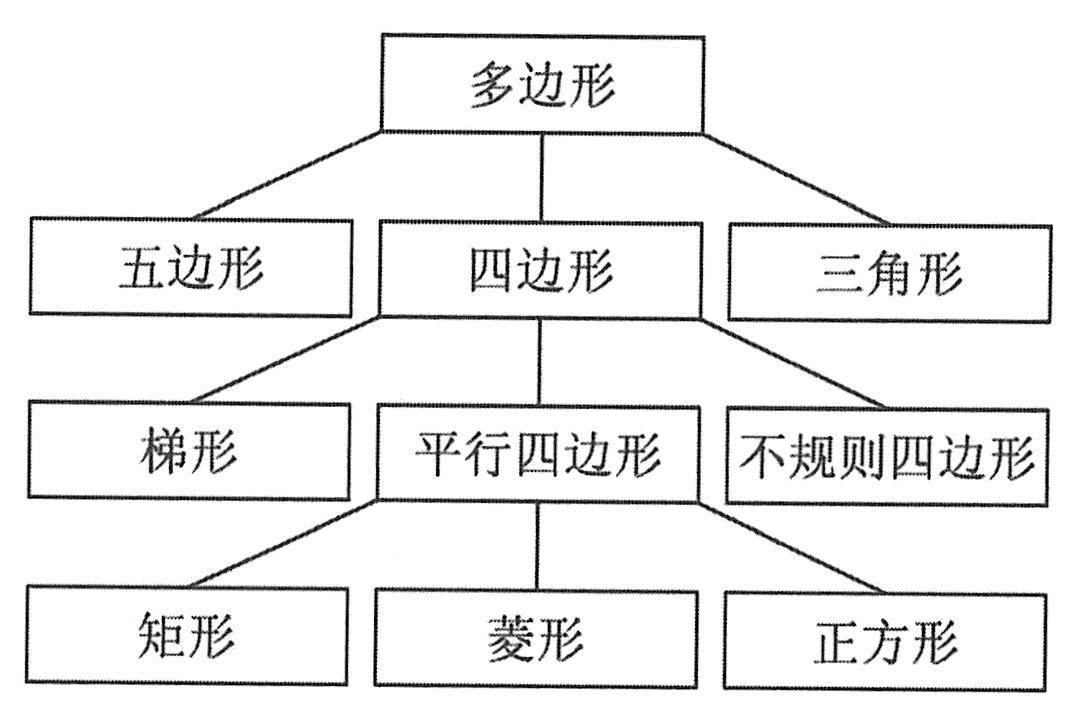
从下图的继承关系上看,每个子类有且只有一个父类,所有子类都是其父类的派生类,它们都分别是父类的一种特例,父类和子类之间存在着一种“继承”关系。不同图形之间的继承层级结构示意图如下图所示。
|
|
|
|
|
|
|
|
我们在面向对象程序设计中就利用这种“继承”和“派生”关系来组织和描述及表达事物,常使用以下基本术语:
|
|
|
|
.基类:指被继承的类,也就是父类。通过继承,用户可以重用父类的代码,而只需专注编写子类的新代码。
|
|
|
|
.派生类:指通过继承基类而创建的新类,也就是子类。
|
|
|
|
.单继承:派生类是由一个(且只能是一个)基类创建的。C#只支持单继承。
|
|
|
|
.多继承:派生类是由两个或以上的基类创建的。C#不支持多继承,而是通过“接口”来实现的。
|
|
|
|
|
|
|
|
现在我们构造一个学生类Student作为基类,然后增加研究生类,由于研究生除了有其本身的特点外,还具有学生的所有属性,所以我们利用继承机制在研究生类中重用学生类的成员,同时在研究生类中再补充新的成员。
|
|
|
|
|
|
在C#中,多态性是通过“虚方法重载”来实现在程序中调用相应对象所属类中的方法,而不是调用基类的方法。
|
|
|
|
C#语言可以在派生类中实现对基类的某个方法、属性或索引等类成员重新定义,而这些成员名和相应的参数都不变,这种特性叫虚成员重载。所以虚方法重载就是指将基类的某个方法在其派生类中重新定义,也叫重写方法,而方法名和方法的参数都不改变。实现虚成员重载的C#语言编程构架是:
|
|
|
|
先在基类中用virtual修饰符定义虚成员。虚成员可以是类的方法、属性和索引等,不能是域或私有变量成员。定义虚成员与定义普通成员的格式是一样的,只是另加修饰符virtual即可。
|
|
|
|
|
|
|
|
在派生类中用override修饰符重新定义与基类同名的覆盖成员,并根据需要重新定义基类中虚成员的代码(方法重写),以满足不同类的对象的使用需求,这就是重载虚成员多态的实现。
|
|
|
|
|
|
|
|
|
|
所谓异常就是指在程序运行期间发生的错误或意外情况。总之程序在运行期间出现异常是不可避免的,我们不能回避异常,而是要积极采取措施来控制和解决出现的异常现象。一般我们将产生异常的原因分为两种:由程序本身产生的和由程序运行环境(公共语言运行时环境)引起的。如果异常是由于运行的程序本身引起,则大多数情况下这种异常是可以恢复的;但如果异常是由于公共语言运行时环境所引起,则大多数异常难以恢复。
|
|
|
|
C#的异常处理指的是在程序中加入异常控制代码,使用try/catch语句块配合完成捕获异常和处理异常的任务。不能单独使用try或catch语句块,它们必须同时使用。通常情况下,try可配合多个catch子句,每个catch子句对应一种特定的异常,就好像switch…case语句一样。try/catch语句块基本格式如下:
|
|
|
|
|
|
当try子句中的程序代码产生异常时,系统就会在catch子句中查找,看是否有与设置的异常类型相同的catch子句,如果有,就会执行该子句中的语句;如果没有,则转到调用当前方法的方法中继续查找。该过程一直继续下去,直至找到一个匹配的catch子句为止;如果一直没有找到,则运行时将会产生一个未处理的异常错误。
|
|
|
|
catch子句也可以不包含参数,即不包含对某种类型异常对象的捕获,这时catch子句将捕获所有类型的异常,这就好比switch…case语句中的default语句。
|
|
|
|
最后要说明一点:如果没有发生异常,那么try块正常结束,所有的catch语句被忽略,程序转到最后一个catch语句之后的第一条语句处开始执行。因此,只有发生异常,catch语句才会执行。
|
|
|
|
有时候,我们希望在执行完try/catch块后再做一些善后处理。如果想要在try/catch结束后再执行一些关闭资源的操作,就在程序中包含一个finally语句块,可以根据需要构成try…finally或try…catch…finally语句结构形式。
|
|
|
|
|
|
try…catch…finally语句的执行功能:不论try块是正常退出,还是因为发生了异常而退出,最后执行的都是由finally语句定义的代码块。即使try块中或者任何catch语句中的代码从方法中返回,finally块也会得到执行。
|
|
|
|
|
|
|
|
|
|
目前,Java 2平台有3个版本,它们是适用于小型设备和智能卡的Java 2平台Micro版(Java 2 Platform Micro Edition,J2ME)、适用于桌面系统的Java 2平台标准版(Java 2 Platform Standard Edition,J2SE)、适用于创建服务器应用程序和服务的Java 2平台企业版(Java 2 Platform Enterprise Edition,J2EE)。J2EE是一种利用Java 2平台来简化企业解决方案的开发、部署和管理相关的复杂问题的体系结构。
|
|
|
|
J2EE平台已经成为使用最广泛的Web程序设计技术。该技术主要支持两类软件的开发和应用。一类是做高级信息系统框架的Web应用服务器;另一类是在Web应用服务器上运行的Web应用程序。目前很多商业网站和管理信息系统大多采用J2EE平台作为首选的Web开发技术,每一个Web应用服务器都将需要企业开发和运行多种Web服务软件。
|
|
|
|
J2EE核心是一组技术规范与指南,其中所包含的各类组件、服务架构及技术层次,均有共同的标准及规格,让各种依循J2EE架构的不同平台之间,存在良好的兼容性,解决过去企业后端使用的信息产品彼此之间无法兼容,企业内部或外部难以互通的窘境。
|
|
|
|
|
|
|
|
|
|
|
|
J2EE为搭建具有可伸缩性、灵活性、易维护性的商务系统提供了良好的机制,表现在如下几个方面:
|
|
|
|
(1)保留现存的IT资产。J2EE架构可以充分利用用户原有的投资,并且由于基于J2EE平台的产品几乎能够在任何操作系统和硬件配置上运行,现有的操作系统和硬件也能被保留使用。
|
|
|
|
(2)高效的开发。J2EE允许公司把一些通用的、很烦琐的服务端任务交给中间供应商去完成。这样开发人员可以集中精力在如何创建商业逻辑上,相应地缩短了开发时间。高级中间件供应商提供状态管理服务和持续性服务等。
|
|
|
|
(3)支持异构环境。J2EE能够开发部署在异构环境中的可移植程序。基于J2EE的应用程序不依赖任何特定操作系统、中间件、硬件。因此设计合理的基于J2EE的程序只需开发一次就可部署到各种平台。J2EE标准也允许客户订购与J2EE兼容的第三方的现成的组件,把它们部署到异构环境中,节省了由自己制订整个方案所需的费用。
|
|
|
|
(4)可伸缩性。基于J2EE平台的应用程序可被部署到各种操作系统上。J2EE领域的供应商提供了更为广泛的负载平衡策略,能消除系统中的瓶颈,允许多台服务器集成部署。这种部署可达数千个处理器,实现可高度伸缩的系统,满足未来商业应用的需要。
|
|
|
|
(5)稳定的可用性。一个服务器端平台必须能全天候运转以满足公司客户、合作伙伴的需要。J2EE部署到可靠的操作环境中,它们支持长期的可用性。
|
|
|
|
|
|
这种基于组件,具有平台无关性的J2EE结构使得J2EE程序的编写十分简单,因为业务逻辑被封装成可复用的组件,并且J2EE服务器以容器的形式为所有的组件类型提供后台服务。容器和服务容器设置定制了J2EE服务器所提供得内在支持,包括安全,事务管理,JNDI(Java Naming and Directory Interface)寻址,远程连接等服务,以下列出最重要的几种服务:
|
|
|
|
.J2EE安全(Security)模型,可以配置Web组件或Enterprise Bean(服务器端组件模型),这样只有被授权的用户才能访问系统资源。每一客户属于一个特别的角色,而每个角色只允许激活特定的方法。
|
|
|
|
.J2EE事务管理(Transaction Management)模型,指定组成一个事务中所有方法间的关系,这样一个事务中的所有方法被当成一个单一的单元。当客户端激活一个enterprise bean中的方法,容器介入管理事务。因为有容器管理事务,在enterprise bean中不必对事务的边界进行编码。只需在布置描述文件中声明enterprise bean的事务属性,而不用编写并调试复杂的代码。容器将读此文件并处理此enterprise bean的事务。
|
|
|
|
.J2EE远程连接(Remote Client Connectivity)模型,管理客户端和enterprise bean间的底层交互。
|
|
|
|
.生存周期管理(Life Cycle Management)模型,管理enterprise bean的创建和移除,一个enterprise bean在其生存周期中将会历经几种状态。容器创建enterprise bean,并在可用实例池与活动状态中移动它,而最终将其从容器中移除。即使可以调用enterprise bean的create及remove方法,容器也将会在后台执行这些任务。
|
|
|
|
.数据库连接池(Database Connection Pooling)模型,因为获取数据库连接是一项耗时的工作,而且连接数非常有限。容器通过管理连接池来缓和这些问题。enterprise bean可从池中迅速获取连接。
|
|
|
|
|
|
J2EE平台由一整套服务(Services)、应用程序接口(APIs)和协议构成,它对开发基于Web的多层应用提供了功能支持,下面对J2EE中的13种技术规范进行简单的描述:
|
|
|
|
.JDBC(Java Database Connectivity):JDBC API为访问不同的数据库提供了一种统一的途径。JDBC对开发者屏蔽了一些细节问题,另外,JDCB对数据库的访问也具有平台无关性。
|
|
|
|
.JNDI(Java Name and Directory Interface):被用于执行名字和目录服务。它提供了一致的模型来存取和操作企业级的资源,本地文件系统或应用服务器中的对象。
|
|
|
|
.EJB(Enterprise JavaBean):J2EE技术提供了一个框架来开发和实施分布式商务逻辑,由此很显著地简化了具有可伸缩性和高度复杂的企业级应用的开发。EJB规范定义了EJB组件在何时如何与它们的容器进行交互作用。容器负责提供公用的服务,例如目录服务、事务管理、安全性、资源缓冲池以及容错性。但这里值得注意的是,EJB并不是实现J2EE的唯一途径。正是由于J2EE的开放性,使得有的厂商能够以一种和EJB平行的方式来达到同样的目的。
|
|
|
|
.RMI(Remote Method Invoke):正如其名字所表示的那样,RMI协议调用远程对象上方法。它使用了序列化方式在客户端和服务器端传递数据。RMI是一种被EJB使用的更底层的协议。
|
|
|
|
.Java IDL/CORBA:Java IDL(Interface Definition Language)可实现网络上不同平台上的对象相互之间的交互。在Java IDL的支持下,开发人员可以将Java和CORBA(Common Object Request Broker Architecture,公共对象请求代理体系结构)集成在一起。
|
|
|
|
.JSP(Java Server Pages):JSP页面由HTML代码和嵌入其中的Java代码所组成。服务器在页面被客户端所请求以后对这些Java代码进行处理,然后将生成的HTML页面返回给客户端的浏览器。
|
|
|
|
.Java Servlet:Servlet是一种小型的Java程序,它扩展了Web服务器的功能。作为一种服务器端的应用,当被请求时开始执行。Servlet提供的功能大多与JSP类似,不过实现的方式不同。JSP通常是大多数HTML代码中嵌入少量的Java代码,而Servlet全部由Java写成并且生成HTML。
|
|
|
|
.XML(Extensible Markup Language):XML是一种可以用来定义其他标记语言的语言。它被用来在不同的商务过程中共享数据。XML的发展和Java是相互独立的,但是,它和Java具有的相同目标正是平台独立性。通过将Java和XML的组合,可以得到一个具有平台独立性的解决方案。
|
|
|
|
.JMS(Java Message Service):JMS是用于和面向消息的中间件相互通信的应用程序接口。它既支持点对点的域,又支持发布/订阅(publish/subscribe)类型的域,并且提供对下列类型的支持:经认可的消息传递、事务型消息的传递、一致性消息和具有持久性的订阅者支持。
|
|
|
|
.JTA(Java Transaction Architecture):JTA定义了一种标准的API,应用系统由此可以访问各种事务监控。
|
|
|
|
.JTS(Java Transaction Service):JTS是一个组件事务监视器。其规定了事务管理器的实现方式。JTS事务管理器为应用服务器、资源管理器、独立的应用以及通信资源管理器提供了事务服务。
|
|
|
|
.JavaMail:JavaMail是用于存取邮件服务器的API,它提供了一套邮件服务器的抽象类。
|
|
|
|
.JAF(JavaBeans Activation Framework):JavaMail利用JAF来处理MIME编码的邮件附件。MIME的字节流可以被转换成Java对象,或者转换自Java对象。
|
|
|
|
|
|
J2EE是一种利用Java2平台来简化与多级企业解决方案的开发、部署和管理相关复杂问题的体系结构。J2EE提供了一套完整的开发多层分布式应用的技术和设施,是为当今众多厂商支持的多层分布式应用的标准,为快速灵活地建立大规模的分布式企业应用提供了高效的解决方案。
|
|
|
|
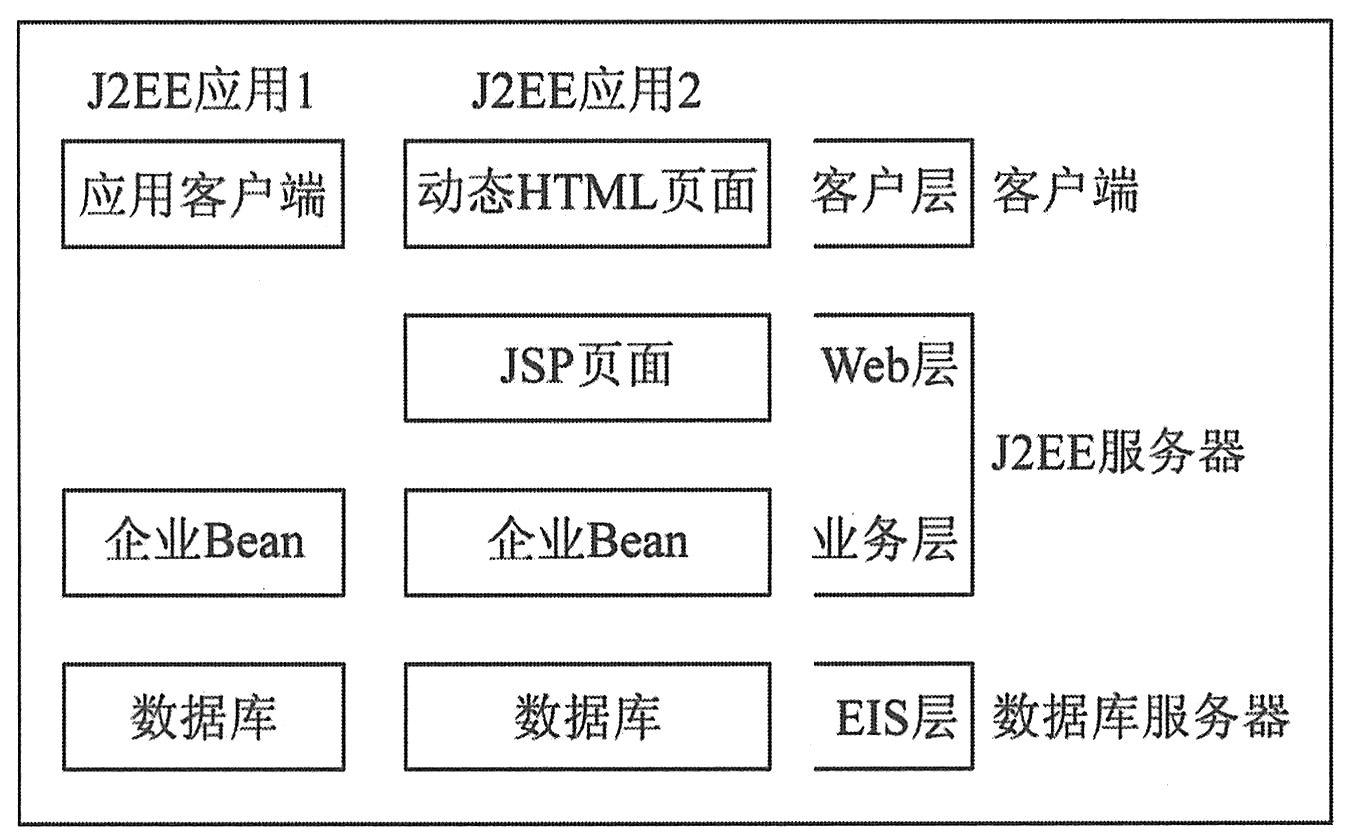
J2EE使用多层分布式的应用程序模型,根据功能的不同把应用程序逻辑划分为各个组件。一个组件应该被安装在什么地方,取决于该组件属于多层J2EE应用的哪一层。这些层分别是客户层、Web层、业务层、企业信息系统层(EIS),结构如下图所示。
|
|
|
|
|
|
|
|
|
|
J2EE应用可以是基于Web的,也可以是不基于Web的。在一个基于Web的J2EE应用中,用户的浏览器在客户层中运行,并从一个Web服务器下载Web层中的静态HTML页面或者由JSP/Servlet生成的动态HTML页面。在一个不基于Web的J2EE应用中,一个独立客户程序,或者一个不是运行在HTML页面中,而是运行在其他基于网络的系统(如手持设备或者汽车电话)中的Applet程序。
|
|
|
|
|
|
J2EE Web组件可以由JSP页面、基于Web的Applet(Java创建的基于HTML的程序)以及显示HTML页面的Servlet(一种服务器端的Java应用程序,可以生成动态的Web页面)组成。Web层可能包含一个JavaBean(Java语言写成的可重用组件)来管理用户输入,并将输入发送给在业务层中运行的EJB(Enterprise JavaBean)来处理。Web层也称表示层。
|
|
|
|
|
|
作为满足某个特定业务领域(如银行、零售或金融业)需要的业务逻辑代码由运行在业务层的EJB(Enterprise JavaBean)来执行。一个EJB从客户程序处接收数据,在需要的情况下对数据进行处理,再将数据发送到企业信息系统层存储。一个EJB还从存储中检索数据,并将数据送回客户程序。运行在业务层的EJB依赖于容器提供诸如事务、生命期、状态管理、多线程及资源缓冲池等十分复杂的系统级功能。业务层也称EJB层。
|
|
|
|
|
|
|
|
企业信息系统层运行企业信息系统软件,这层包括企业基础设施系统。例如企业资源计划(EPR)、大型机事务处理(Mainframe Transaction Processing)、数据库系统等。J2EE应用组件因为某种原因(如访问数据库)可能需要访问企业信息系统。
|
|
|
|
|
|
框架(Framework)是一个提供了可重用的公共结构的半成品。它为我们构件新的应用提供了极大的方便。一方面给我们提供了可以直接使用的工具,同时给我们提供了可重用的设计。框架这个词最早出现在建筑领域,指的是在建造房屋前构建的建筑骨架。对应用程序来说,“框架”的意义也在于此,是应用程序的骨架。开发者可以在这个骨架上添加自己的东西,完成符合自己需要的应用系统。
|
|
|
|
框架保证了我们程序结构风格统一,从企业的角度来说,降低了培训成本和软件的维护成本。框架在结构统一和创造力之间维持着一个平衡。框架和组件的意义是不同的。组件是构件应用程序的零件。而框架是一系列预装的,组合在一起的“零件”,而且还定义了“零件”间协同工作的规则。
|
|
|
|
|
|
Struts是一种基于Java技术的JSP Web开发框架,Web应用程序开发人员通过Struts框架即可充分利用面向对象设计、代码重用以及“一次编写、到处运行”的优点。Struts提供了一种创建Web应用程序的框架,对应用程序的显示、表示和数据的后台代码进行了抽象。
|
|
|
|
Struts是对MVC(Model View Controller)设计模式的一种实现。MVC设计模式为构建可扩展、可重用的代码打下了坚实的基础。以MVC设计模式构造软件,可以使软件结构灵活、重用性好、扩展性好。
|
|
|
|
MVC设计模式目的就是将模型(业务逻辑)和视图(页面展示)分离,使模型和视图可以独立修改,而不会影响到对方。在MVC中,M指的是Model(模型),表示程序处理业务逻辑的部分;V指的是View(视图),表示程序负责展示数据、获得用户输入的部分;C指的是Controller(控制器),负责从V接收用户输入,调用M,返回数据到V。我们可以看出,C在MVC起到“中介”的作用,从而保证M和V不会直接交互。
|
|
|
|
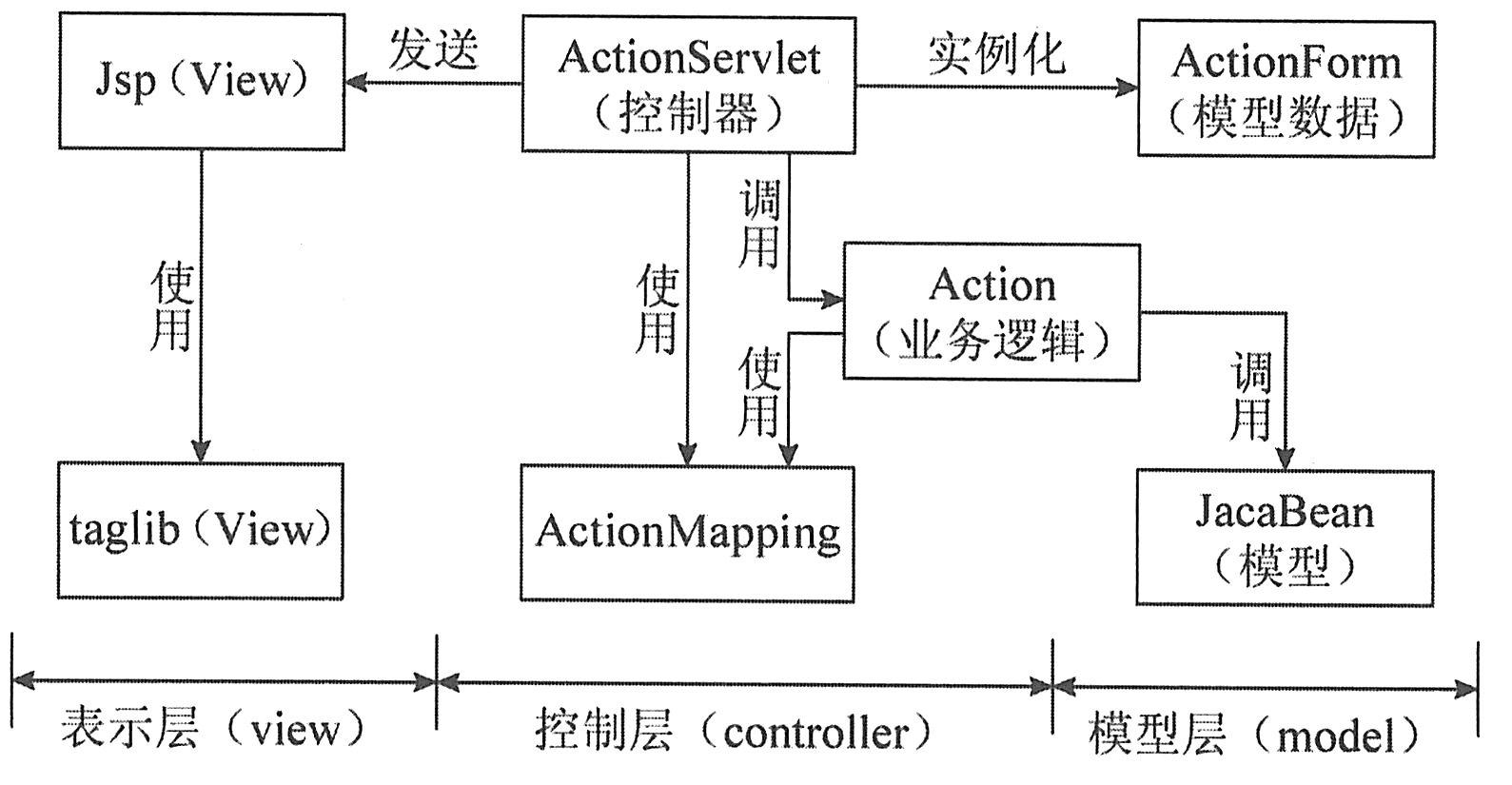
在Struts中,ActionServlet起着一个控制器的作用。视图主要由JSP来控制页面输出。模型在Struts中,主要存在三种bean,分别是:Action、ActionForm、EJB或者Java Bean。Struts框架结构如下图所示。
|
|
|
|
|
|
|
|
|
|
Spring是轻量级的J2EE应用程序开源框架。它是为了解决企业应用开发的复杂性而创建的。Spring使用基本的JavaBean来完成以前只可能由EJB完成的事情。并且Spring的用途不仅限于服务器端的开发。从简单性、可测试性和松耦合的角度而言,任何Java应用都可以从Spring中受益。
|
|
|
|
Spring的核心是个轻量级容器(container),是实现了IoC(Inversion of Control)模式的容器;Spring的目标是实现一个全方位的整合框架,在Spring框架下实现多个子框架的组合,这些子框架之间彼此可以独立,也可以使用其他的框架方案加以替代。
|
|
|
|
Spring支持AOP(Aspect-Oriented Programming),Spring也提供MVC Web框架的解决方案,并且可以将MVC Web框架与Spring结合。Spring还提供其他方面的整合,如JDBC(Java Data Base Connectivity,Java数据库连接)、事务处理等。Spring框架结构如下图所示。
|
|
|
|
|
|
|
|
Spring的核心概念是IoC(Inversion of Control),IoC的抽象概念是“依赖关系的转移”,中文可以译为“控制反转”。IoC表现在:高层模块不应该依赖低层模块,而是模块都必须依赖于抽象;实现必须依赖抽象,而不是抽象依赖实现;应用程序不应依赖于容器,而是容器服务于应用程序。
|
|
|
|
IoC是由容器控制程序之间的关系,而非由程序代码直接操控。控制权由应用代码转到了外部容器。控制权的转移,就是所谓的反转。使用IoC,对象是被动的接受依赖类,容器在实例化的时候主动将它的依赖类注入给它。
|
|
|
|
Spring所采用的是依赖注入(Dependency Injection)。依赖注入的意义是:保留抽象接口,让组件依赖于抽象接口,当组件要与其他实际的对象发生依赖关系时,通过抽象接口来注入依赖的实际对象。依赖注入的目标是为了提升组件重用的几率,并为系统搭建一个灵活和可扩展的平台。
|
|
|
|
另外,Spring提供一种无侵入式的高扩展性框架,不需要代码中涉及Spring专有类,即可纳入Spring容器进行管理。org.springframework.beans包中包括了这些核心组件的实现类。
|
|
|
|
Spring框架另一个重要方面是对AOP提供了一种优秀的实现。AOP(Aspect Oriented Programming),可翻译为“面向切面编程”。AOP是针对业务处理过程中的切面进行提取,它所面对的是处理过程中的某个步骤或阶段,以获得逻辑过程中各部分之间低耦合性的隔离效果。AOP组件与应用代码无关,应用代码可以脱离AOP组件独立编译。Spring中的AOP通过运行期动态代理模式实现。
|
|
|
|
|
|
①基于Java Beans的配置管理,减少各组件间相互依赖。
|
|
|
|
|
|
|
|
④建立在框架内对Java数据处理API和单独的JDBC数据源的一般性策略。
|
|
|
|
⑤Web应用中的MVC框架,基于核心的Spring功能,支持多种产生视图的技术。
|
|
|
|
|
|
|
|
Hibernate是一个开放源代码的对象关系映射框架,它对JDBC进行了非常轻量级的对象封装,使得Java程序员可以使用对象编程思维来操纵数据库。
|
|
|
|
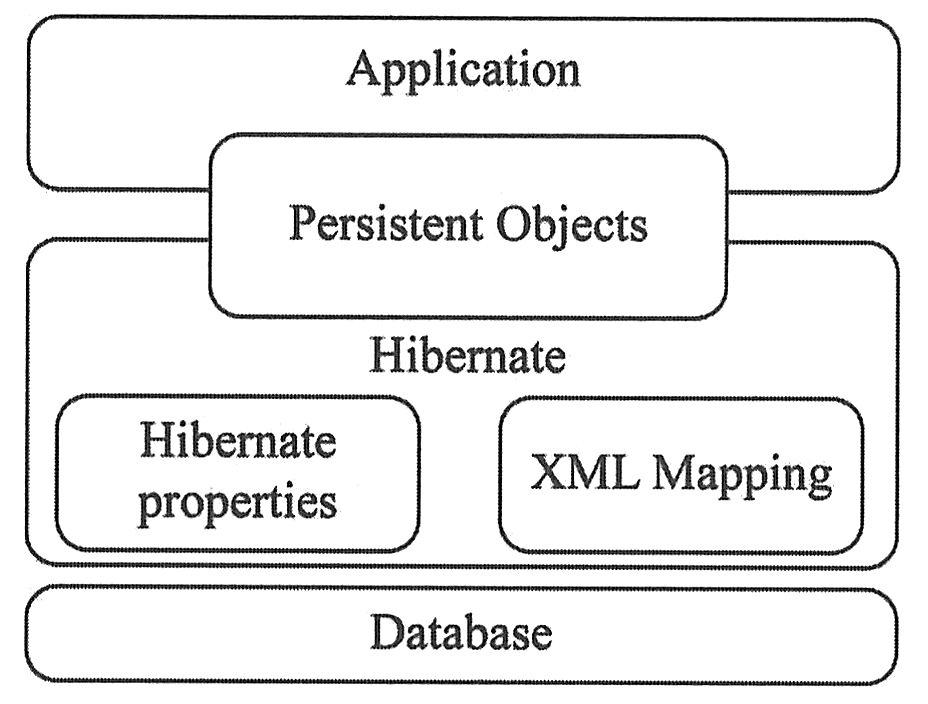
“对象/关系”映射(O/R Mapping)是一门非常实用的工程技术,它实现了Java应用中的对象到关系数据库中的表的持久化。使用元数据(meta data)描述了对象与数据库间的映射。Hibernate是非常优秀、成熟的O/R Mapping框架,它提供了强大的对象和关系数据库映射以及查询功能。Hibernate体系结构如下图所示。
|
|
|
|
|
|
|
|
Hibernate的核心接口一共有6个,分别为:Session、SessionFactory、Transaction、Query、Criteria和Configuration。这6个核心接口在任何开发中都会用到。通过这些接口,不仅可以对持久化对象进行存取,还能够进行事务控制。下面对这6个核心接口分别加以介绍。
|
|
|
|
(1)Session接口。Session接口负责执行被持久化对象的增删改查操作(增删改查的任务是完成与数据库的交流,包含了很多常见的SQL语句)。但需要注意的是Session对象是非线程安全的。
|
|
|
|
(2)SessionFactory接口。SessionFactory接口负责初始化Hibernate。它充当数据存储源的代理,并负责创建Session对象。这里用到了工厂模式。需要注意的是SessionFactory并不是轻量级的,因为一般情况下,一个项目通常只需要一个SessionFactory就够,当需要操作多个数据库时,可以为每个数据库指定一个SessionFactory。
|
|
|
|
(3)Configuration接口。Configuration接口负责配置并启动Hibernate,创建SessionFactory对象。在Hibernate的启动的过程中,Configuration类的实例首先定位映射文档位置,读取配置,然后创建SessionFactory对象。
|
|
|
|
(4)Transaction接口。Transaction接口负责事务相关的操作。它是可选的,开发人员也可以设计编写自己的底层事务处理代码。
|
|
|
|
(5)Query和Criteria接口。Query和Criteria接口负责执行各种数据库查询。它可以使用HQL(Hibernate Query Language,官方推荐的Hibernate检索方式)或SQL语句两种表达方式。
|
|
|
|
|
|
目前,移动互联网已经深入到人们生活中的各个方面,如购物、社交、日常工作等,为人们的衣食住行提供了极大的便利,改变了人们的生活方式。传统的IT企业都在向移动互联转型,以拓宽业务空间来获得更大的利润增长点。当前互联网移动端开发主流的平台主要有Android和iOS两大平台,基本完全占据了移动市场操作系统,2018年1季度时,安卓操作系统市场份额71.82%,iOS系统为28.03%,其他平台占有率不足1%。
|
|
|
|
|
|
|
|
Android是一个以Linux为基础的开源移动设备操作系统,主要用于智能手机和平板电脑,由Google成立的Open Handset Alliance(OHA,开放手持设备联盟)持续领导与开发中。
|
|
|
|
|
|
基于Linux内核操作系统,Android系统对Linux内核进行了加强。其系统架构如下图所示,采用了分层架构思想,从上到下分为4层,分别为Application(应用层)、Application Framework(应用框架层)、Libraries and Android Runtime(系统库及Android运行时,系统运行库层)和Linux Kernel(Linux内核层),各层采用Software Stack(软件栈)的方式进行构建。
|
|
|
|
|
|
|
|
(1)Android应用层。Android应用层提供的服务即我们常说的应用,它是与用户直接交互的。所有的应用程序(包括原生和第三方)都在应用层上进行构建,如系统自带的日历、通话、短信、浏览器等以及在Android应用商店中下载的游戏、音乐软件等;应用层运行在Android运行时内,并且使用了应用程序框架的类和服务。
|
|
|
|
(2)Android应用框架层。Android应用框架层提供了开发Android应用程序所需的一系列类库,通常是系统API接口,使开发人员可以方便、快速地构建应用整体框架,其具体的模块内容及功能如下:
|
|
|
|
①Activity Manager(活动管理器)。管理各个应用程序活动窗口并为窗口提供交互的接口。
|
|
|
|
②Window Manager(窗口管理器)。管理所有开启的窗口程序。
|
|
|
|
③Content Provider(内容提供者)。提供应用内或应用程序间数据共享功能。
|
|
|
|
④View System(视图)。创建应用程序基本视图组件,如ListView、TextView、WebView等控件。
|
|
|
|
⑤Notification Manager(通知管理器)。用户可以自定义状态栏中的提示信息。
|
|
|
|
⑥Package Manager(包管理器)。应用程序安装进手机后,以包名作为文件夹名进行存储,此API提供诸如应用程序的安装与卸载功能以及提示相关的权限信息。
|
|
|
|
⑦Resource Manager(资源管理器)。提供图片、音视频等非代码资源。
|
|
|
|
⑧Location Manager(位置管理器)。提供位置信息服务。
|
|
|
|
⑨Telephony Manager(电话管理器)。管理所有移动设备功能。
|
|
|
|
|
|
(3)Android系统运行库层。Android系统运行时库层包含两部分内容,一个是系统库,一个是Android运行时。
|
|
|
|
系统库提供了系统功能通过Android应用程序框架层为开发者提供服务,其类库的主要内容包含各种C/C++核心库(如Libc和SSL)、支持音频视频的多媒体库、用于本地数据库支持的SQLite、2D/3D图形处理引擎、外观管理器、数据传输服务(WebKit、SSL)等。另外,Android NDK(Android Native Development Kit,Android原生库)也为开发者提供了直接使用Android系统资源的能力。
|
|
|
|
Android运行时包含核心库与Dalvik虚拟机两部分:
|
|
|
|
①核心库提供了Java SE API的绝大多数功能,并提供Android的核心API,如android.os、android.net、android.util、android.meida等。
|
|
|
|
②Dalvik虚拟机是基于Apache的Java虚拟机,被改进以适应低内存、低处理速度的移动设备环境,负责运行Android应用程序,提供实现进程隔离与线程调试管理、安全和异常管理、垃圾回收等重要功能。
|
|
|
|
(4)Android Linux内核层。Android Linux内核层作为系统架构的最底层借助Linux内核服务实现硬件设备驱动,从而为上层提供诸如进程与内存管理、网络协议栈、电源管理以及驱动程序等功能,同时Linux内核也是硬件与软件之间的抽象层(Hardware Abstract Layer,HAL),它是对硬件设备具体实现的抽象,这样程序开发人员就无须考虑系统底部的实现细节,提高了开发效率。
|
|
|
|
|
|
Android应用程序是由一些松散的组件构成,每个应用程序中都会包含一个配置文件AndroidManifest.xml,主要描述应用程序中所用到的各组件及其相互关系,还包括硬件要求、权限声明等。Android应用程序各组件之间可以调用相互独立的基本功能模块,其中根据功能的不同,可以划分为四类不同的组件,即:
|
|
|
|
|
|
②Service(服务)。后台运行服务,不提供界面呈现。
|
|
|
|
③BroadcastReceiver(广播接收器)。用于接收广播。
|
|
|
|
④ContentProvider(内容提供者)。支持在多个应用中存储和读取数据,相当于数据库。
|
|
|
|
各组件之间是通过Intent来实现消息传递,Intent可以理解为不同组件通信的媒介或者信使。Intent可以启动或停止一个Activity或Service,还可以发起一个广播Broadcast,Android系统中大量使用了Intent,在实际的应用程序开发中也会频繁使用Intent传递信息。
|
|
|
|
(1)Activity(活动)。是Android应用程序核心组件中最基本的一种,也是最常见的组件,是用户和应用程序交互的窗口。通常一个Android应用程序由一个或多个Activity组成,多个Activity之间可以进行相互跳转,例如按下一个Button按钮后,可能会跳转到其他的Activity。与Web网页跳转不同的是,Activity之间的跳转可以有返回值,例如从Activity A跳转到Activity B,那么当Activity B运行结束的时候,有可能会给Activity A一个返回值,这样做在很多时候是非常方便。虽然Android应用程序有多个Activity组成,但是其中却只有一个主Activity。
|
|
|
|
(2)Service(服务)。是一种类似Activity但没有用户界面的组件,运行在后台,相当于操作系统中的一个服务,并且可以和其他组件进行交互。Service也是一种程序,是没有界面的长生命周期的代码,它可以运行很长时间,例如打开一个音乐播放器的程序,这个时候若想上网,再打开一个Android浏览器,歌曲播放并没有停止,而是在后台继续播放,就是由播放音乐的Service进行控制。
|
|
|
|
(3)BroadcastReceiver(广播接收器)。是一种全局监听器,用来接收来自系统或其他应用程序的广播。并作出回应,在Android系统中,当有特定的事件发生时就会产生相应的广播,并通过NotificationManager来通知用户有事件发生。
|
|
|
|
(4)ContentProvider(内容提供者)。主要是实现在不同应用程序之间数据的共享与交换,使得其他应用可以对自身的数据进行增、删、改、查操作(通常结合SQLite使用)。由于Android中的文件、数据库在系统内都是私有的,仅允许被特定的应用程序直接使用,所以ContentProvider类实现了一组标准方法的接口,从而能让其他的应用程序读取或保存ContentProvider提供的各类数据。Android系统使用了许多ContentProvider,例如:联系人资料、通话记录、短信、相册等,一般这些数据都存放于不同的数据库中。
|
|
|
|
|
|
Android开发的常用框架分别为MVC(Model-View-Controller)框架、MVP(Model-View-Presenter)框架和MVVM(Model-View-ViewModel)框架,目前Google主推MVVM开发框架模式。MVC前文已有介绍,在此主要介绍MVP和MVVM框架。
|
|
|
|
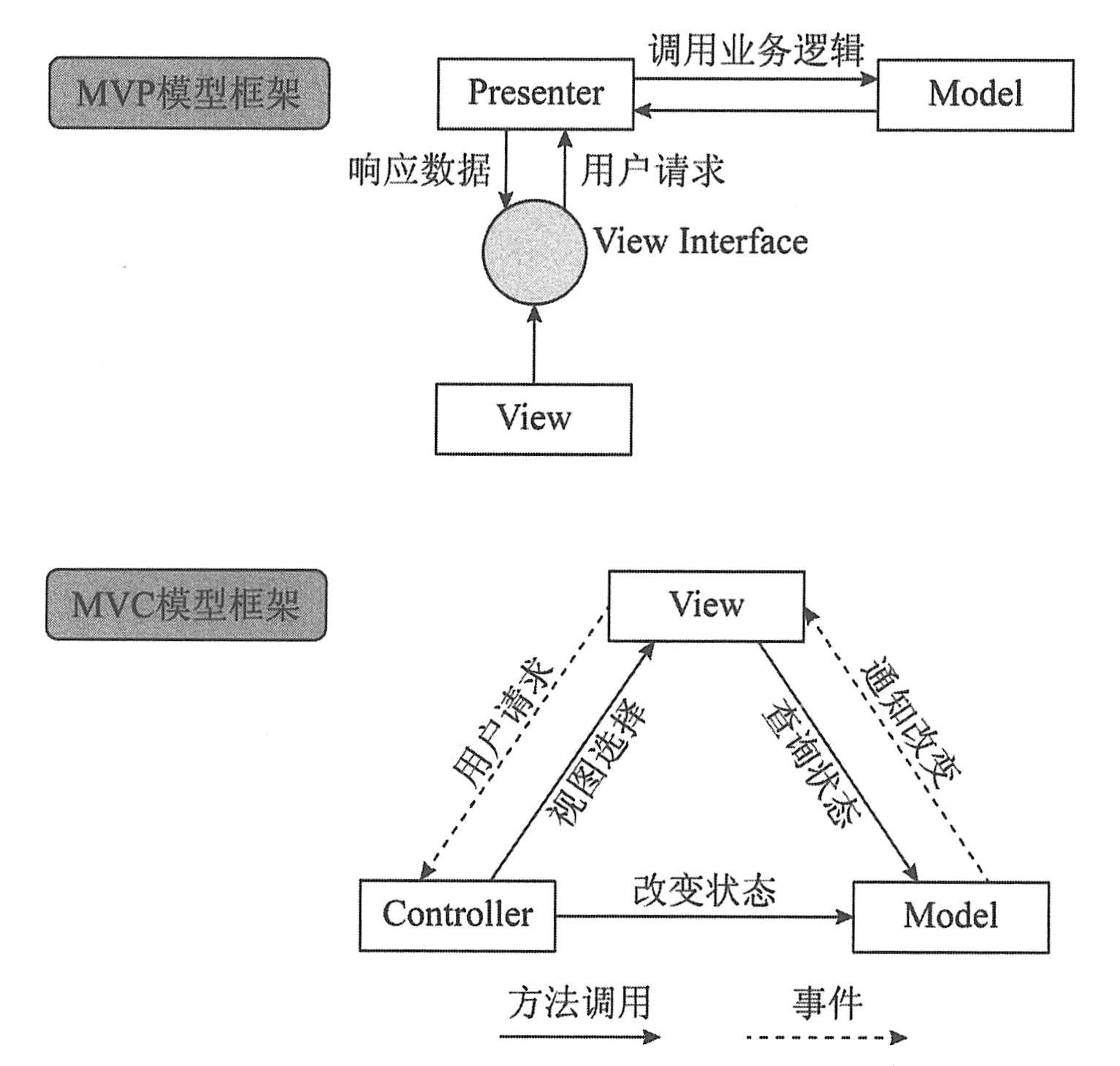
(1)MVP(Model-View-Presenter)。MVP模式是目前Android系统非常流行的框架,是从MVC模式演变过来的,它们的基本思想有相通的地方:Controller/Presenter负责逻辑的处理,Model提供数据,View负责显示。但是MVP与MVC有着一个重大的区别,如下图所示:在MVP中View并不直接使用Model,二者完全分离以减少耦合,它们之间的通信是通过Presenter(MVC中的Controller)来进行的,所有的交互都发生在Presenter内部,而在MVC中View会直接从Model中读取数据而不是通过Controller。MVP大大降低了耦合度(Activity不再进行复杂的操作),层级更明显,相对MVC来说MVP更加适用于Android应用的开发。
|
|
|
|
|
|
|
|
.Model(模型):依然是实体模型(作用与MVC相同)。
|
|
|
|
.View(视图):在对应的Activity和XML文件中,负责View的绘制以及与用户的交互。
|
|
|
|
.Presenter(交互器/表示器):负责完成View与Model间的交互和业务逻辑。
|
|
|
|
MVP核心是过一个抽象的View接口(IView)将Presenter与View层进行解耦。Persenter持有该View接口,对该接口进行操作,而不是直接操作View层。这样就可以把视图操作和业务逻辑解耦,从而使得Activity成为真正的View层。
|
|
|
|
虽然MVP使得Android开发变得更简单,但是也存在以下弊端:
|
|
|
|
①Presenter层与View层是通过接口进行交互的,接口粒度不好控制。粒度太小,就会存在大量接口的情况,使代码太过碎版化;粒度太大,解耦效果不好。同时对于界面UI的输入和数据的变化,需要手动调用View层或Presenter层相关的接口,相对来说缺乏自动性、监听性。
|
|
|
|
②MVP是以界面UI和事件为驱动的传统模型,更新UI都需要保证能获取到控件的引用,同时更新UI的时候还要考虑当前是否是UI线程,也要考虑Activity的生命周期。而且数据都是被动地通过UI控件做展示,但是由于数据的时变性,因此更希望数据能转被动为主动,数据能更有活性,由数据来驱动UI。
|
|
|
|
③View层与Presenter层还是有一定的耦合度。一旦View层某个UI元素更改,那么对应的接口就必须得改,数据如何映射到UI上、事件监听接口这些都需要转变。同时,复杂的逻辑业务处理也可能会导致Presenter层代码变得异常臃肿。
|
|
|
|
(2)MVVM(Model-View-ViewModel)。为了解决MPV框架结构的弊端,MVVM框架利用数据绑定(Data Binding)、依赖属性(Dependency Property)、命令(Command)、路由事件(Routed Event)等新特性打造了一个更加灵活高效的架构。Google于2016年正式推出MVVM正式库,目前的Android Studio能够很好的支持在MVVM框架下开发应用程序。
|
|
|
|
作为MVP的升级版,MVVM将Presenter改名为ViewModel(视图模型)。如下图所示,MVVM的核心思想是实现View和Model的双向绑定,当View有用户输入后,ViewModel通知Model更新数据,同理Model数据更新后,ViewModel通知View更新。
|
|
|
|
|
|
|
|
.Model(模型):和MVP相同,基本就是实体模型(Bean),包括Retrofit的Service。ViewModel可以根据Model获取一个Bean的Observable(RxJava),然后做一些数据转换操作和映射到ViewModel中的一些字段,最后把这些字段绑定到View层上。
|
|
|
|
.View(视图):View层实现和界面UI相关的工作,开发人员只在XML和Activity或Fragment写View层的代码。View层不做和业务相关的事,Activity不写和业务逻辑相关代码,也不需要根据业务逻辑来更新UI的代码,而更新界面UI通过Binding实现,在ViewModel里面更新绑定的数据源即可,Activity要做的事就是初始化一些控件。Activity可以更新UI,但是更新的UI必须和业务逻辑和数据是没有关系的,只是单纯的根据点击或者滑动等事件更新UI(如根据滑动颜色渐变、根据点击隐藏等单纯UI逻辑),Activity(View层)只是处理UI本身的事件,简单地说:View层不做任何业务逻辑、不涉及操作数据、不处理数据、UI和数据严格分开。
|
|
|
|
.ViewModel(视图模型):ViewModel层做的事情刚好和View层相反,它只做和业务逻辑和业务数据相关的事,不做任何和界面UI、控件相关的事,ViewModel层不会持有任何控件的引用,不会在ViewModel中通过UI控件的引用去更新UI。ViewModel专注于业务的逻辑处理,操作也都是对数据进行操作,数据源绑定在相应的控件上会自动去更改UI,开发者不需要关心更新UI。
|
|
|
|
|
|
①数据驱动。在常规的开发模式中,数据变化需要更新界面UI的时候,需要先获取UI控件的引用,然后再更新UI。在MVVM中,这些都是通过数据驱动来自动完成,数据变化后会自动更新UI,UI的改变也能自动反馈到数据层,数据成为主导因素。这样MVVM在业务逻辑处理中只要关心数据。对于版本迭代中频繁的UI改动,更新或新增一套View即可。
|
|
|
|
②低耦合度。MVVM框架的分工是非常明确,数据是独立于UI。数据和业务逻辑处于一个独立的ViewModel中,ViewModel只需要关注数据和业务逻辑,不需要和UI或者控件打交道,即便是控件改变了(例如:TextView换成EditText),ViewModel也几乎不需要更改的。
|
|
|
|
③可复用性。一个ViewModel可以复用到多个View中。对于版本迭代中频繁的UI改动,更新或新增一套View即可。
|
|
|
|
MVVM的优点还体现在团队协作、单元测试等方面。总之,Google推进的MVVM开发框架优势非常明显,是今后Android开发框架的主要发展趋势。
|
|
|
|
|
|
|
|
iOS是由苹果公司开发的移动操作系统,最初是设计给iPhone使用的,后来陆续套用到iPod touch、iPad以及Apple TV等产品上。
|
|
|
|
|
|
iOS系统分为可分为四级结构,如下图所示:由上至下分别为Cocoa Touch Layer(可触摸层)、Media Layer(多媒体层)、Core Services Layer(核心服务层)、Core OS Layer(核心系统层),每个层级提供不同的服务。低层级结构提供基础服务如文件系统、内存管理、I/O操作等。高层级结构建立在低层级结构之上提供具体服务如UI控件、文件访问等。
|
|
|
|
|
|
|
|
(1)Cocoa Touch Layer(可触摸层)。Cocoa Touch Layer是基于Objective-C的API接口,大部分功能与用户界面有关,主要负责用户在iOS设备上的触摸交互操作。该层共11个framwork(框架),最核心的部分是UIKit.framework,应用程序界面上的各种组件,全是由它来提供呈现的,除此之外,UIKit还负责处理屏幕上的多点触摸事件、文字输出、图片/网页显示、相机或文件存取,以及加速感应的部分等。
|
|
|
|
该层还提供与用户交互相关的EventKit(日历事件提醒等)、Notification Center(通知中心)、MapKit(地图显示)、Address Book(联系人)、iAd(广告)、Message UI(邮件与SMS显示)等框架。
|
|
|
|
(2)Media Layer(多媒体层)。Media Layer提供了图片、音乐、影片等多媒体功能。图像分为2D图像和3D图像,前者由Quartz2D引擎支持,后者则是由OpenglES引擎支持;与音乐对应是Core Audio和OpenAL,Media Player等框架模块实现了影片的播放,而最后还提供了Core Animation来对强大动画的支持。该层既有基于Objective-C的API接口也有基于C语言的API接口。
|
|
|
|
因此,Media Layer主要分为图像引擎、音频引擎、视频引擎:
|
|
|
|
.图像引擎(Core Graphics、Core Image、Core Animation、OpenGLES、Quartz、OpenAL、Image IO等)
|
|
|
|
.音频引擎(Core Audio、AV Foundation、OpenAL、AudioToolbox、AudioUnit等)
|
|
|
|
.视频引擎(AV Foundation、Core Media、MediaPlayer等)
|
|
|
|
(3)Core Services Layer(核心服务层)。Core Services Layer是在Core OS基础上提供了更加丰富的服务,主要基于C语言API接口。该层包含了Foundation.Framework和Core Foundation.Framework,之所以叫Foundation,是因为它提供了一系列处理字串、排列、组合、日历、时间等基本功能。Foundation是属Objective-C的API,Core Fundation是属于C的API。另外Core Services Layer还提供了CFNetwork(网络访问)、Core Data(数据存储)、Core Location(定位功能)、Core Motion(重力加速度,陀螺仪)、Webkit(浏览器引擎)、JavaScript(JavaScript引擎)等模块框架。
|
|
|
|
(4)Core OS Layer(核心系统层)。Core OS Layer包含或提供了大多数低级别接近硬件的功能,例如:硬件驱动、内存管理、程序管理、线程管理(POSIX)、文件系统、网络(BSD Socket)以及标准输入输出等等,所有这些功能都会通过C语言的API来提供。它所包含的框架常常被其他框架所使用,其中Accelerate框架包含数字信号、线性代数、图像处理的接口。针对所有的iOS设备硬件之间的差异做优化,保证写一次代码在所有iOS设备上高效运行。CoreBluetooth框架利用蓝牙和外设交互,包括扫描连接蓝牙设备、保存连接状态、断开连接、获取外设的数据或者给外设传输数据等;Security框架提供管理证书,公钥和私钥信任策略,keychain、hash认证数字签名等与安全相关的解决方案。
|
|
|