|
|
|
|
|
|
|
|
|
|
|
图存储在那些需要分析对象之间的关系或者通过一个特定的方式访问图中所有节点的应用中尤为重要。图存储针对有效存储图节点和联系进行了优化,让你可以对这些图结构进行查询。图数据库对于那些对象之间具有复杂关系的业务问题很有用,如社交网路、规则引擎、生成组合和那些需要快速分析复杂网络结果并从中找出模式的图系统。
|
|
|
|
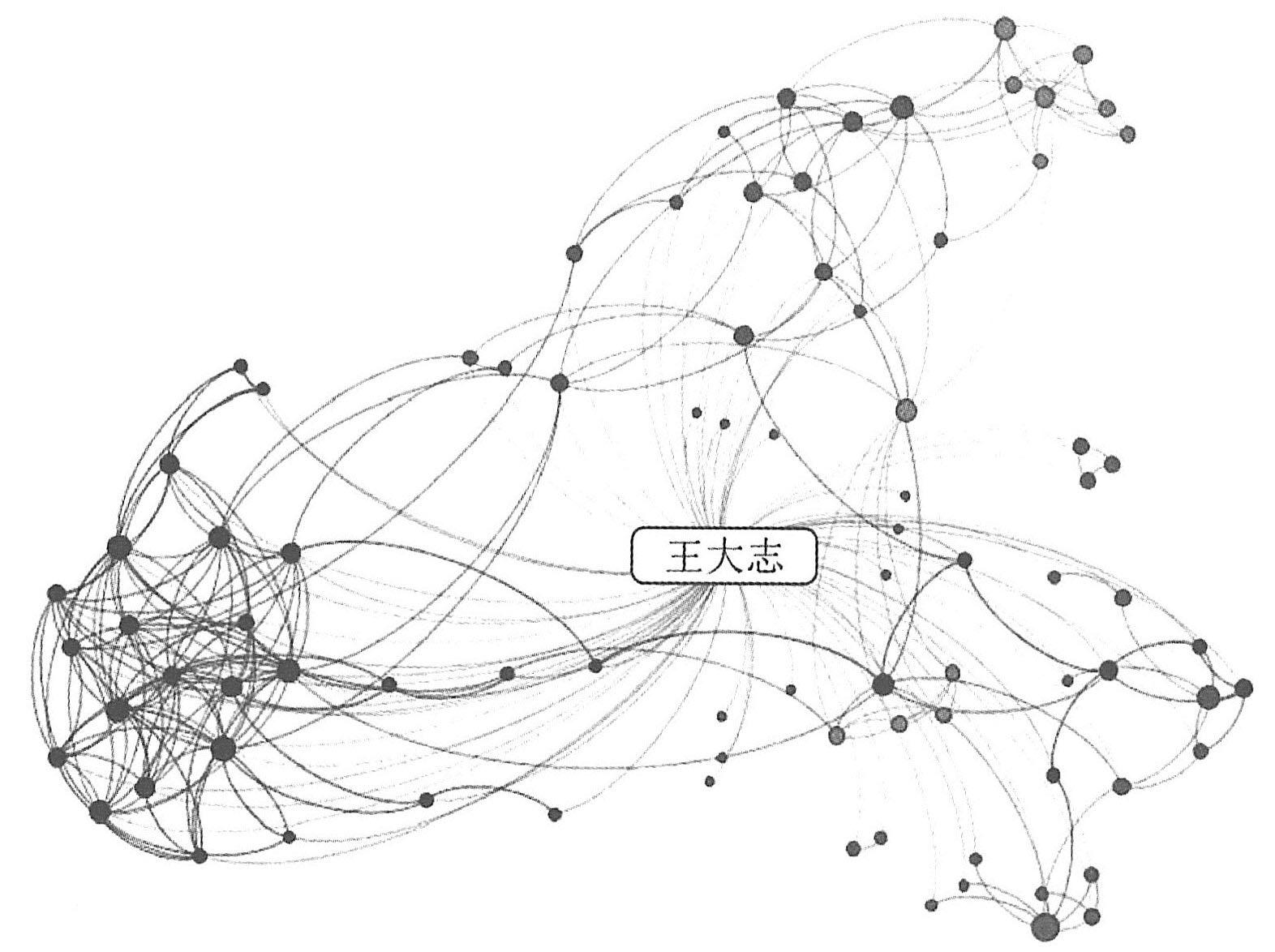
图存储是一个包含一连串的节点和关系的系统,当它们结合在一起时,就构成了一个图。图存储有三个字段:节点、关系和属性。图节点通常是现实世界中对象的表现,如人名、组织、电话号码、网页或计算机节点。而关系可以被认为是这些对象之间的联系,通常被表示为图中两个节点之间连接线。如下图是“王大志”这个人的社交网络示意图,从图中可以看出与他建立直接或者间接联系的朋友的数量,以及不同朋友之间的紧密程度。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
如果图存储的节点众多、关系复杂、属性很多,那么传统的关系型数据库将要建很多大型的表,并且表的很多列可能是空的,在查询时还极有可能进行多重SQL语句的嵌套。可是图存储就可以很优异,基于图的很多高效的算法可以大大提高执行效率。
|
|
|
|
现总结一下图数据库和传统的关系型数据库在一些问题处理上的不同,如下表所示。
|
|
|
|
|
|
|
|
在很长一段时间里,图数据库只局限在学术圈子中,直到电子商务的业务模型逐渐成熟,挖掘用户的潜在喜好商品,并大量使用相关的挖掘算法,才使得图数据库逐渐“走出来”。目前常见的一些图数据库如下表所示。
|
|
|
|
|
|
|
|
其中,比较成熟的是Twitter的FlockDB。FlockDB是一个分布式的图数据库,但是它并没有优化遍历图的操作。它优化的操作包括:超大规模邻接矩阵查询,快速读写和可分页查询;它主要是要解决可伸缩性的问题,通俗点说就是通过增加服务器就能解决用户量上升造成的访问压力,而不需要在软件上做大的变动。FlockDB将图存储为一个边的集合,每条边用两个代表顶点的64位整数表示。对于一个社会化网络图,这些顶点ID即用户ID,但是对于“收藏”推文这样的边,其目标顶点(destination id)则是一条推文的ID。每一条边都被一个64位的位置信息标识,用于排序。(Twitter在“关注”类的边上用了时间戳标识,所以如果你的关注者列表是按时间排序的,那么总是最新的在最前面。)
|
|
|
|
对于一条复杂的查询,通常会被分解成一些单用户查询,并很快响应。数据根据节点分块,所以这些查询能分别在各自的数据块,通过一个索引过的范围查询得到结果。类似地,遍历一个长结果集是用位置作为游标,而不是用LIMIT/OFFSET,所有页的数据均被索引,访问一样快。
|
|
|
|
Neo4j也是一个典型的图数据库。它提供了大规模可扩展性,在一台机器上可以处理数十亿节点/关系/属性的图像,可以扩展到多台机器并行运行。相对于关系数据库来说,图数据库善于处理大量复杂、互连接、低结构化的数据,这些数据变化迅速,需要频繁的查询。在关系数据库中,这些查询会导致大量的表连接,因此会产生性能上的问题。Neo4j重点解决了拥有大量连接的传统RDBMS在查询时出现的性能衰退问题。通过围绕图进行数据建模,Neo4j会以相同的速度遍历节点与边,其遍历速度与构成图的数据量没有任何关系。此外,Neo4j还提供了非常快的图算法、推荐系统和OLAP风格的分析,而这一切在目前的RDBMS系统中都是无法实现的。
|
|
|