|
|
|
|
|
|
|
|
|
|
|
语法分析的任务是根据语言的语法规则,分析单词串是否构成短语和句子,即是否为合法的表达式、语句和程序等基本语言结构,同时检查和处理程序中的语法错误。程序设计语言的绝大多数语法规则可以采用上下文无关文法进行描述。语法分析方法有多种,根据产生语法树的方向,可分为自底向上(或自下而上)和自顶向下(或自上而下)两类。
|
|
|
|
|
|
上下文无关文法属于乔姆斯基定义的2型文法,被广泛地用于表示各种程序设计语言的语法。对于上下文无关文法G[S]=(VN,VT,P,S),其产生式的形式都是A→β,其中A∈VN,β∈(VN∪VT)*。
|
|
|
|
若不加特别说明,下面用大写英文字母A、B、C等表示非终结符,小写英文字母a、b、c等表示终结符号,u、v、w等表示终结符号串,小写希腊字母α、β、γ、δ等表示终结符和非终结符构成的文法符号串。由于一个上下文无关文法的核心部分是其产生式集合,所以文法可以简写为其产生式集合的描述形式。
|
|
|
(1)规范推导(最右推导)。如果在推导的任何一步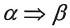 其中α、β是句型),都是对α中最右边的非终结符进行替换,则称这种推导为最右推导。最右推导常称为规范推导。同理可定义最左推导。 其中α、β是句型),都是对α中最右边的非终结符进行替换,则称这种推导为最右推导。最右推导常称为规范推导。同理可定义最左推导。
|
|
|
(2)短语、直接短语和句柄。设αδβ是文法G的一个句型,即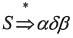 ,且满足 ,且满足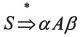 和 和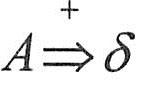 ,则称δ是句型αδβ相对于非终结符A的短语。特别地,如果有 ,则称δ是句型αδβ相对于非终结符A的短语。特别地,如果有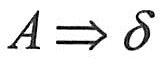 ,则称δ是句型αδβ相对于产生式A→δ的直接短语。一个句型的最左直接短语称为该句型的句柄。 ,则称δ是句型αδβ相对于产生式A→δ的直接短语。一个句型的最左直接短语称为该句型的句柄。
|
|
|
|
|
|
自顶向下分析法的基本思想是:对于给定的输入串ω,从文法的开始符号S出发进行最左推导,直到得到一个合法的句子或者发现一个非法结构。在推导的过程中试图用一切可能的方法,自上而下、从左到右地为输入串ω建立语法树。整个分析过程是一个试探的过程,是反复使用不同产生式谋求与输入序列匹配的过程。若输入串是给定文法的句子,则必能成功,反之必然出错。
|
|
|
|
文法中存在下述产生式时,自顶向下分析过程中会出现下面的问题:
|
|
|
|
(1)若文法中存在形如A→αβ|αδ的产生式,即A产生式中有多于一个候选项的前缀相同(称为公共左因子,简称左因子),则可能导致分析过程中的回溯处理。
|
|
|
|
(2)若文法中存在形如A→Aα的产生式,由于采取了最左推导,可能会造成分析过程陷入死循环的情况,产生式的这种形式被称为左递归。
|
|
|
|
因此,需要对文法进行改造,消除其中的左递归,以避免分析陷入死循环;提取左因子,以避免回溯。
|
|
|
|
(3)递归下降分析法。递归下降分析法直接以子程序调用的方法模拟产生式产生语言的过程,其基本思想是:为每一个非终结符构造一个子程序,每个子程序的过程体按该产生式候选项分情况展开,遇到终结符即进行匹配,而遇到非终结符则调用相应的子程序。该分析法从调用文法开始符号的子程序开始,直到所有非终结符都展开为终结符并得到匹配为止。若分析过程可以达到这一步,则表明分析成功,否则表明输入串中有语法错误。递归下降分析法的优点是简单且易于构造,缺点是程序与文法直接相关,对文法的任何改变都需要在程序中进行相应的修改。
|
|
|
|
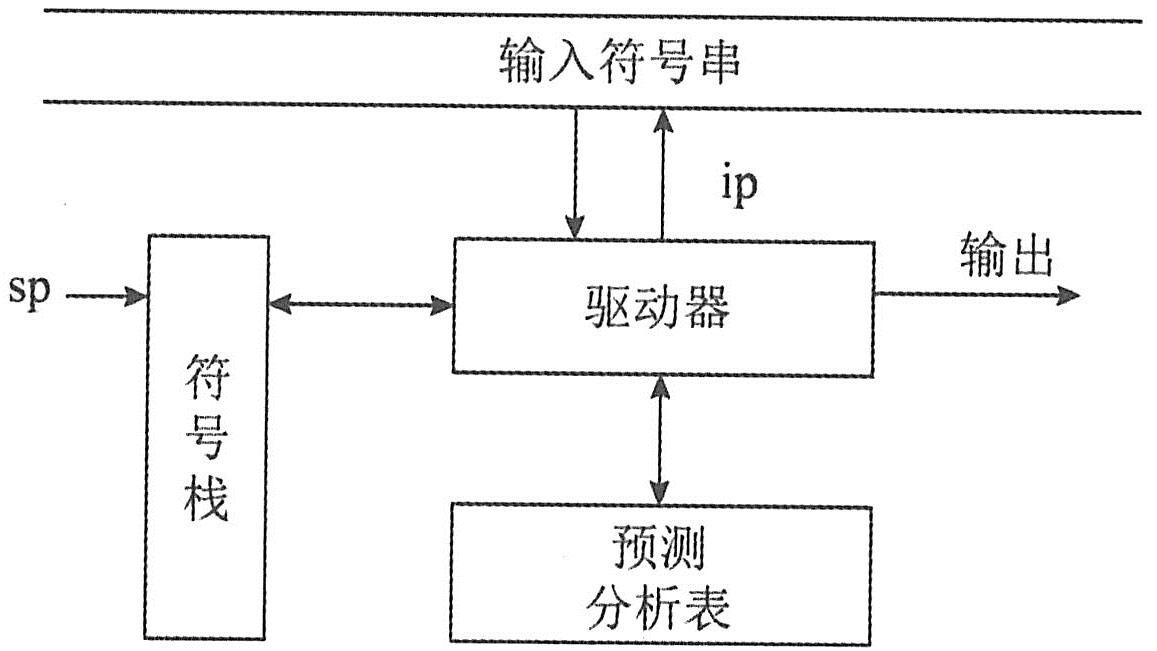
(4)预测分析法。预测分析法是另一种自顶向下的语法分析方法,其基本模型如下图所示。
|
|
|
|
|
|
|
|
预测分析法的核心是预测分析表,可以用一个二维数组M表示,其元素M[A,a](A∈VN,a∈VT∪#)存放关于A的产生式,表明当遇到输入符号为a且用A进行推导时,所应采用的产生式;若M[A,a]为error,则表明推导时遇到了不该出现的符号,应进行出错处理。
|
|
|
|
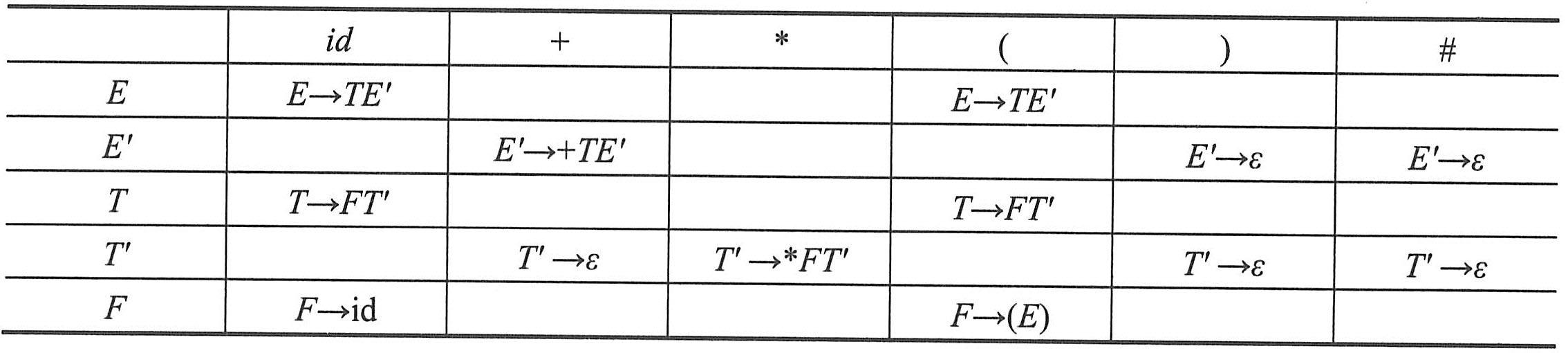
例如,根据文法G[E]={E→TE',E'→+TE'|ε,T→FT',T'→*FT'|ε,F→(E)|id|}的构造的预测分析表如下表所示。
|
|
|
|
|
|
|
|
预测分析法的工作过程是:初始时,将“#”和文法的开始符号依次压入栈中;在分析过程中,根据输入串中的当前输入符号a和当前的栈顶符号X进行处理。
|
|
|
|
若X=a='#',则分析成功;若X='#'且a≠'#',则出错。
|
|
|
|
若X∈VT且X=a,则X退栈,并读入下一个符号a;若X∈VT且X≠a,则出错。
|
|
|
|
若X∈VN且M[X,a]='A→α',则X退栈,α中的符号从右到左依次进栈(ε无须进栈);若M[X,a]='error',则调用出错程序进行处理。
|
|
|
|
|
|
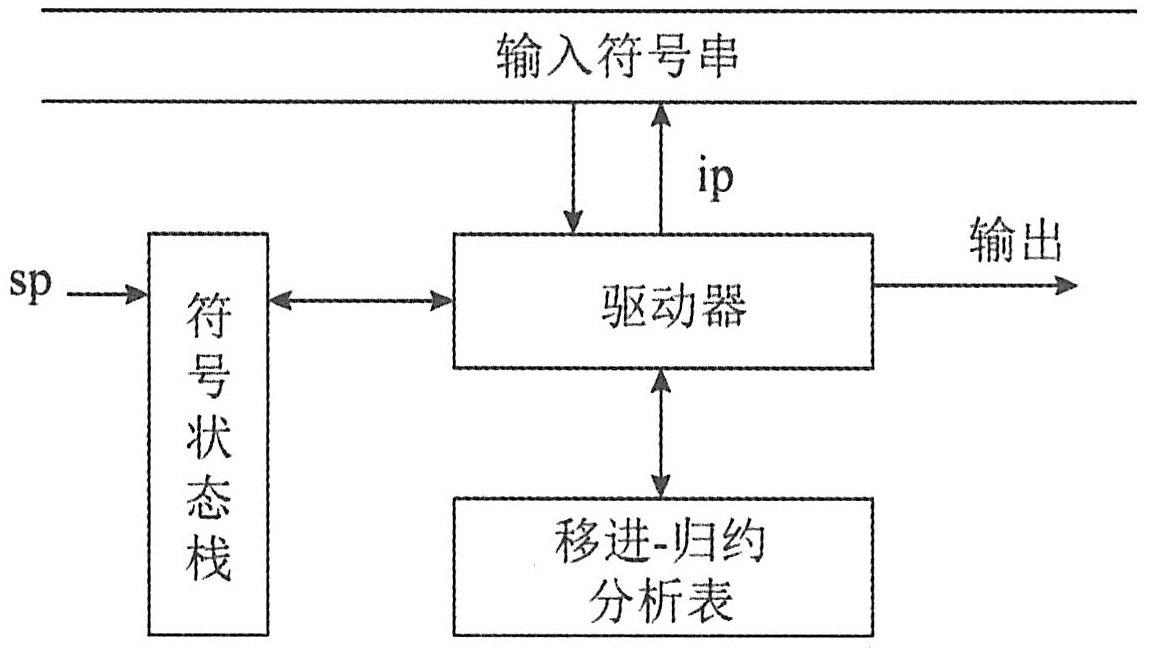
常用的自底向上分析方法也称移进-归约分析法,工作模型是下推自动机,如下图所示。其基本思想是对输入序列ω自左向右进行扫描,并将输入符号逐个移进一个栈中,边移进边分析,一旦栈顶符号串形成某个句型的可归约串(即句柄)时,就用某个产生式的左部非终结符来替代,这称为一步归约。重复这一过程,直至栈中只剩下文法的开始符号且输入串也被扫描完时为止,确认输入串ω是文法的句子,表明分析成功;否则,进行出错处理。
|
|
|
|
|
|
|
|
LR分析法是一种规范归约分析法。规范归约是规范推导(最右推导)的逆过程,下面举例说明规范归约的过程。
|
|
|
|
LR分析法根据当前分析栈中的符号串(通常以状态表示)和向右顺序查看输入串的k个(k≥0)符号,就可唯一确定分析器的动作是移进还是归约,以及用哪条产生式进行归约,因而也就能唯一地确定句柄。当k=1时,已能满足当前绝大多数高级语言编译程序的需求。常用的LR分析器有LR(0)、SLR(1)、LALR(1)和LR(1)。
|
|
|
|
|
|
(1)驱动器。或称驱动程序。对所有LR分析器,驱动程序都是相同的。
|
|
|
|
(2)分析表。不同的文法具有不同的分析表。同一文法采用不同的LR分析器时,分析表也不同。分析表又可分为动作表(ACTION)和状态转换表(GOTO)两个部分,它们都可用二维数组表示。
|
|
|
|
|
|
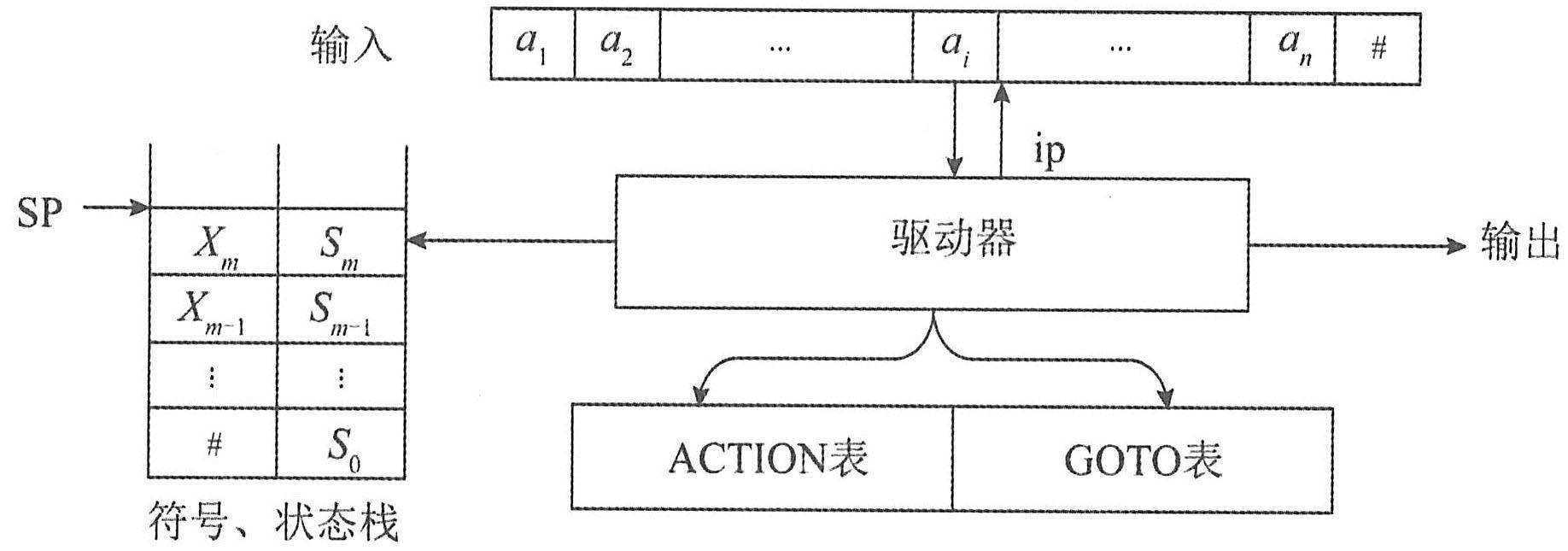
分析器的动作由栈顶状态和当前输入符号决定(LR(0)分析器不需向前查看输入符号),LR分析器的模型如下图所示。
|
|
|
|
|
|
|
|
其中SP为栈顶指针,Si为状态,Xi为文法符号。ACTION[Si,a]=Sj规定了栈顶状态为Si且遇到输入符号a时应执行的动作。状态转换表GOTO[Si,X]=Sj表示当状态栈顶为Si且文法符号栈顶为X时应转向状态Sj。
|
|
|
|
LR分析器的工作过程以格局的变化来反映。格局的形式为(栈,剩余输入,动作)。分析是从某个初始格局开始的,经过一系列的格局变化,最终达到接受格局,表明分析成功;或者达到出错格局,表明发现一个语法错误。因此,开始格局的剩余输入应该是全部的输入序列,而接受格局中的剩余输入应该为空,任何其他格局或者出错格局中的剩余输入应该是全部输入序列的一个后缀。
|
|
|
|
|
|
(1)移进(shift)。当ACTION[Si,a]=Sj时,把a移进文法符号栈并转向状态Sj。
|
|
|
|
(2)归约(reduce)。当在文法符号栈顶形成句柄β时,把β归约为相应产生式A→β的非终结符A。若β的长度为r(即|β|=r),则弹出文法符号栈顶的r个符号,然后将A压入文法符号栈中。
|
|
|
|
(3)接受(accept)。当文法符号栈中只剩下文法的开始符号S,并且输入符号串已经结束时(当前输入符是“#”),分析成功。
|
|
|
|
(4)报错(error)。当输入串中出现不该有的文法符号时,就报错。
|
|
|
|
LR分析器的核心部分是分析表的构造,这里不再详述。
|
|
|