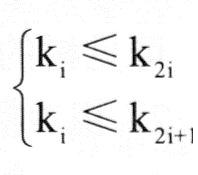|
|
|
|
|
二叉树(Binary Tree)是n(n≥0)个节点的有限集合,它或者是空树(n=0),或者是由一个根节点及两棵互不相交的、分别称为左子树和右子树的二叉树所组成。
|
|
|
|
|
|
.二叉树的节点的子树要区分左子树和右子树,即使在节点只有一棵子树的情况下也要明确指出该子树是左子树还是右子树。
|
|
|
|
.二叉树的节点的最大度为2,而树中不限制节点的度数。
|
|
|
|
|
|
二叉树的基本运算是遍历,其他运算可建立在遍历运算的基础上。
|
|
|
|
|
|
|
|
(1)二叉树第i层上的节点数目最多为2i-1(i≥1)个。
|
|
|
|
(2)深度为k的二叉树至多有2k-1(k≥1)个节点。
|
|
|
|
(3)在任意一棵二叉树中,若终端节点数为n0,度为2的节点数为n2,则n0=n2+1。
|
|
|
|
(4)具有n个节点的完全二叉树的深度为[log2n]+1。
|
|
|
|
(5)对一棵有n个节点的完全二叉树的节点按层次自左至右进行编号,则对任意节点i有以下性质。
|
|
|
.若i=1,则节点i是二叉树的根,无双亲;若i>1,则其双亲为 。 。
|
|
|
|
.若2i>n,则节点i无左孩子;否则其左孩子为2i。
|
|
|
|
.若2i+1>n,则节点i无右孩子;否则其右孩子为2i+1。
|
|
|
|
若深度为k的二叉树有2k-1个节点,则称其为满二叉树。
|
|
|
|
深度为k、有n个节点的二叉树,当且仅当其每一个节点都与深度为k的满二叉树编号从1至n的节点一一对应时,称之为完全二叉树。
|
|
|
|
|
|
|
|
用一组地址连续的存储单元存储二叉树中的数据元素,必须把节点排成一个适当的线性序列,并且节点在这个序列中的相互位置能反映出节点之间的逻辑关系。
|
|
|
|
顺序存储结构用于完全二叉树时既简单又节省空间,而对于一般二叉树则不适用。因为在顺序存储结构中,以节点在存储单元中的位置来表示节点之间的关系,那么对于一般的二叉树来说,也必须按照完全二叉树的形式存储,也就是要添上一些实际并不存在的"虚节点",这将造成空间的浪费。
|
|
|
|
|
|
由于二叉树中的节点包含有数据元素、左子树根、右子树根及双亲等信息,因此可以用三叉链表或二叉链表来存储二叉树,链表的头指针指向二叉树的根节点。
|
|
|
|
|
|
遍历是指按某种策略访问树中的每个节点,且仅访问一次。由于二叉树所具有的递归性质,一棵非空的二叉树可以看作由根节点、左子树和右子树三部分构成,因此若能依次遍历这三部分中的每个节点信息,也就遍历了整棵二叉树。按照遍历左子树要在遍历右子树之前进行的约定,根据访问根节点位置的不同,可得到二叉树的前序、中序和后序3种遍历方法。
|
|
|
|
遍历二叉树的基本操作就是访问节点,不论按照哪种次序遍历,对含有n个节点的二叉树,遍历算法的时间复杂度都为O(n)。在最坏情况下,二叉树是有n个节点且深度为n的单枝树,遍历算法的空间复杂度也为O(n)。
|
|
|
|
遍历二叉树的过程实质上是按一定规则,将树中的节点排成一个线性序列的过程,因此遍历操作得到的是树中节点的一个线性序列。在每一种序列中,有且仅有一个起始点和一个终节点,其余节点有且仅有唯一的直接前驱和直接后继。
|
|
|
|
对二叉树还可以进行层序遍历。层序遍历就是从树的根节点出发,首先访问第1层的树根节点,然后从左到右依次访问第2层上的节点,以此类推,自上而下、自左到右逐层访问树中各层上节点的过程。
|
|
|
|
|
|
若n个节点的二叉树采用链表作存储结构,则链表中含有n+1个空指针域,利用这些空指针域来存放指向节点的前驱和后继信息。线索链表的节点结构如下图所示。
|
|
|
|
|
|
|
|
若二叉树的二叉链表采用上图所示的节点结构,则相应的链表称为线索链表,其中指向节点前驱、后继的指针称为线索,加上线索的二叉树称为线索二叉树。对二叉树以某种次序遍历使其变为线索二叉树的过程称为线索化。
|
|
|
|
|
|
霍夫曼树又称最优二叉树,是一类带权路径长度最短的树。
|
|
|
|
路径:是指从树中一个节点到另一个节点之间的通路,路径上的分支数目称为路径长度。
|
|
|
|
树的路径长度:是从树根到每一个叶子的路径长度之和。节点的带权路径长度为从该节点到树根之间的路径长度与该节点权的乘积。
|
|
|
|
树的带权路径长度:指树中所有叶子节点的带权路径长度之和,记为
|
|
|
|
|
|
式中,n为带权叶子节点的数目;wi为叶子节点的权值;li为叶子节点到根的路径长度。
|
|
|
|
霍夫曼树是指权值为w1,w2,…,wn的n个叶子节点的二叉树中带权路径长度最小的二叉树。
|
|
|
|
|
|
(1)根据给定的n个权值w1,w2,…,Wn构成n棵二叉树的集合F={T1,T2,…,Tn},其中每棵二叉树Ti中只有一个带权为wi的根节点,其左右子树均空。
|
|
|
|
(2)在F中选取两棵根节点的权值最小的树作为左右子树,构造一棵新的二叉树,置新构造二叉树的根节点的权值为其左、右子树根节点的权值之和。
|
|
|
|
(3)从F中删除这两棵树,同时将新得到的二叉树加入到F中。
|
|
|
|
重复(2)、(3),直到F中只含一棵树时为止。这棵树便是霍夫曼树。
|
|
|
|
|
|
|
|
.树的双亲表示法:用一组地址连续的单元存储树的节点,并在每个节点中附设一个指示器,指示其双亲节点在该存储结构中的位置。显然这种表示对于求指定节点的双亲或祖先都十分方便,但对于求指定节点的孩子及后代则需要遍历整个数组。
|
|
|
|
.树的孩子表示法:在存储结构中用指针指示出节点的每个孩子,由于树中每个节点的子树数目不尽相同,因此在采用链式存储结构时可以考虑多重链表。
|
|
|
|
.树的孩子兄弟表示法:又称二叉链表表示法。在链表的节点中设置两个指针域分别指向该节点的第一个孩子和下一个兄弟。利用这种存储结构便于实现树的各种操作。
|
|
|
|
|
|
(1)树的遍历。树的遍历分为先根遍历和后根遍历两种。
|
|
|
|
.先根遍历:先访问树的根节点,然后依次先根遍历根的各棵子树。对树的先根遍历等同于对转换所得的二叉树进行先序遍历。
|
|
|
|
.后根遍历:先依次后根遍历树根的各棵子树,然后访问树根节点。树的后根遍历等同于对转换所得的二叉树进行中序遍历。
|
|
|
|
(2)森林的遍历。森林的遍历分为前序遍历和后序遍历两种。
|
|
|
|
.前序遍历森林:若森林非空,访问森林中第一棵树的根节点,前序遍历第一棵子树根节点的子树森林,再前序遍历除第一棵树之外剩余的树所构成的森林。
|
|
|
|
.后序遍历森林:若森林非空,后序遍历森林中第一棵树的子树森林,访问第一棵树的根节点,后序遍历除第一棵树之外剩余的树所构成的森林。
|
|
|
|
|
|
(1)树、森林转换为二叉树。利用树的孩子兄弟表示法可导出树与二叉树的对应关系,在树的孩子兄弟表示法中,从物理结构上看与二叉树的二叉链表表示法相同,因此就可以用这种同一存储结构的不同解释将一棵树转换为一棵二叉树。
|
|
|
|
将一个森林转换为一棵二叉树的方法是:先将森林中的每一棵树转换为二叉树,再将第一棵树的根作为转换后的二叉树的根,第一棵树的左子树作为转换后二叉树根的左子树,第二棵树作为转换后二叉树根的右子树,第三棵树作为转换后二叉树根的右子树的右子树,以此类推,森林就可以转换为一棵二叉树。
|
|
|
|
(2)二叉树转换为树和森林。若二叉树非空,则二叉树根及其左子树为第一棵树的二叉树形式,二叉树根的右子树又可以看作一个由森林转换后的二叉树,应用同样的方法,直到最后产生一棵没有右子树的二叉树为止,这样就得到了一个森林。为了进一步得到树,可用树的二叉链表表示的逆方法,即节点的右子树的根、右子树的右子树的根……找出原本是同一个双亲的兄弟。二叉树转换为树或森林是唯一的。
|
|
|
.jpg)
.jpg)
.jpg)

.jpg)