|
|
|
NoSQL数据库并没有统一的模型,而且是非关系型的。常见的NoSQL数据库通过存储方式划分,可分为文档存储、键值存储、列存储和图存储,其具体分类和特点如下表所示。两种不同的NoSQL的数据库之间的差异程度,远远超过两种关系型数据库之间的不同。一个优秀的NoSQL的数据库必然适合某些场合或者某种应用。
|
|
|
|
|
|
|
|
|
|
在传统的数据库中,数据被分割成离散的数据段,而文档存储则是以文档为存储信息的基本单位。文档存储一般用类似json的格式存储,存储的内容是文档型的。面向文档的数据库具有以下特征:即使不定义表结构,也可以像定义了表结构一样来使用。另外,面向文档的数据库可以通过复杂的查询条件来获取数据。虽然不具备事务处理和join等关系型数据库所具有的处理能力,但其他的处理基本都可以实现。
|
|
|
|
在文档存储中,文档可以很长,很复杂,无结构,可以是任意结构的字段,并且数据具有物理和逻辑上的独立性,这就和具有高度结构化的表存储(关系型数据库的主要存储结构)有很大的不同,而最大的不同则在于它不提供对参数完整性和分布事物的支持;不过,它们之间也并不排斥,可以进行数据的交换。鉴于以上特点一些术语也发生了变化,如下表所示。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
MongoDB是10gen公司开发的以高性能和可扩展性为特征的文档型数据库,也是NoSQL文档存储模式数据库中的重要一员。MongoDB的最大特点就是无表结构。在保存数据和数据结构的时候,会把数据和数据结构都完整地以BSON的形式保存起来(BSON是JSON的二进制编码格式,但比JSON支持更加复杂的格式,在空间利用上更加高效,支持的数据类型如下表所示),并把它作为值和特定的键进行关联。正是由于这种设计,使得它不需要表结构,而被称为文档型数据库。
|
|
|
|
|
|
|
|
|
|
这里说的文档,是一种可以嵌套的数据集合。从关系数据库的范式的概念来说,嵌套是明显的反范式设计。范式设计的好处是消除了依赖,但是增加了关联,查询需要通过关联两张或者多张表来获得所需要的全部数据,但是更改操作是原子的,只需要修改一个地方即可。反范式则是增加了数据冗余来提升查询性能,但更新操作可能需要更新冗余的多处数据,需要注意一致性的问题。
|
|
|
|
由于MongoDB最大的特点就是无表结构,无论是定义还是使用,所以,对于任何关键字,它都可以像关系型数据库那样进行复杂的查询。此外,MongoDB拥有比关系型数据库更快的速度,而且,可以像关系型数据库那样通过添加索引来进行高速处理。
|
|
|
|
根据它的特点,可以通过“添加字段”“查询数据”这两个操作看出MongoDB与传统的关系型数据库相比的优势与不足,如下表所示。
|
|
|
|
|
|
|
|
因此,在实际应用中,我们要根据MongoDB的特点灵活使用:在最初的设计时就避免join查询的使用,当然,可以在最开始的时候就将必要的数据嵌入到文档中去,这可以实现同样的功能。
|
|
|
|
除此之外,MongoDB有它自己的通信协议,有几种语言的socket驱动。MongoDB还有强大的查询语言可以和SQL相媲美,它的查询语言同样支持Map/reduce函数。此外,MongoDB的分区方法采用的是“读写分离”,以主从模式对数据进行复制和修改。
|
|
|
|
|
|
(1)高性能:提供JSON、XML等可嵌入数据快速处理功能;提供文档的索引功能,相对传统数据库而言,大大提高查询速度。
|
|
|
|
(2)丰富的查询语言:为数据聚合、结构文档、地理空间提供丰富的查询功能。
|
|
|
|
(3)高可用性:提供数据冗余处理和故障自动转移的功能。
|
|
|
|
(4)水平扩展能力:通过集群将数据分布到多台机器,而不是只提升单个节点的性能,具体处理分为主从和权衡两种处理模式。
|
|
|
|
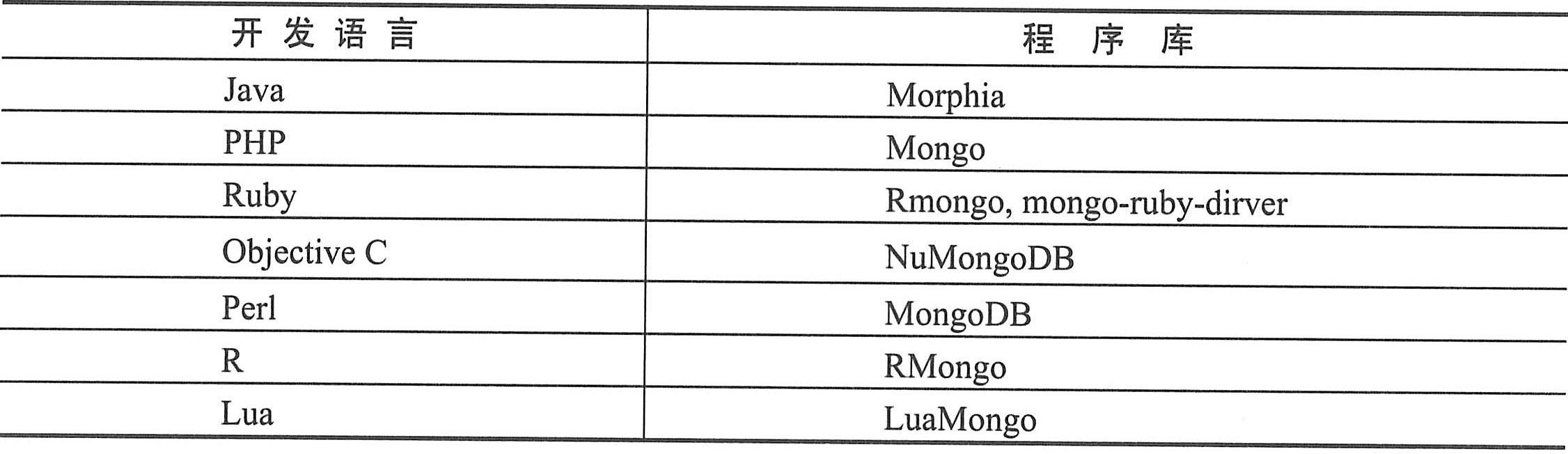
MangoDB为C、C#、.NET、Java、PHP等各种开发语言提供了程序库,如下表所示。
|
|
|
|
|
|
|
|
Java驱动程序是MongoDB最早的驱动,它已经使用多年,而且非常稳定,是企业级开发的首选。下面使用Java驱动程序来举一个各种汽车信息统计的搜索引擎的例子,每种汽车收集的信息都不同,本例子的目的是使得这些信息都能被搜索到。
|
|
|
|
|
|
|
|
MangoDB能存放任意数量、任意属性的被统计信息,这样应用就能轻易扩展,但目前还不能对当前的格式进行有效的索引。MangoDB索引可以将数组的每一个元素进行涵盖,所以可以将想要索引的属性放到一个保护常用键名的数组中。例如,对于宝马汽车,可以为索引添加一个数组,将全部属性放到数组中:
|
|
|
|
|
|
|
|
|
|
现在只要创建一个“index.name”和“index.value”的复合索引就行了。使用Java代码举例,使用ensureIndex函数建复合索引:
|
|
|
|
|
|
|
|
|
|
只要实现了java.util.List,就可以用来表示数组,所以用java.tuil.ArrayList来存放表示汽车不同属性信息的内嵌文档。
|
|
|
|
|
|
除了应用比较多的MangoDB文档数据库之外,另外还有如下一些在应用中使用比较多的文档型数据库:
|
|
|
|
BaseX是一个非常轻巧和高性能的XML数据库系统和Xpath/Xquery处理。包含了对W3C Update和FullText扩展的全面支持。一个可交互和友好的GUI前台操作界面,可以用Xquery查询相关数据库的XML文件,也可动态展示XML文件层次和结点关系的图。它具有高度的交互可视性,可实时执行和可进行Xquery编辑的特点。
|
|
|
|
CouchDB也是一种面向文档的非关系型数据库,用Erlang编写,它主要致力于健壮性、高并发性和容错性。它与其他NoSQL数据库最大的不同在于它的双流向增加副本。CouchDB的文件也是基于JSON,但同样也有二进制的设置,它的API基于REST,用标准的动词GET、PUTPOST和DELETE。可以用JavaScript来操作CouchDB,用户可以通过Map/reduce函数来生成自己的视图。
|
|
|
|
Lotus Notes也是目前较为流行的文档数据库系统之一。作为群件系统,它利用自身强大的功能使其在企业、政府办公自动化方面的应用越来越广。它实现了业务流程化,并且在全文检索、复制、集成开发环境和7层安全机制等方面都有自己独特的定义。但是其结构也决定了它不适于传统的关系型数据库所擅长的事务处理方面的工作。
|
|
|
|
|
|
键值存储模型是最简单,也是最方便使用的数据模型,它支持简单的键对值的键值存储和提取。根据一个简单的字符串(键)能够返回一个任意类型的数据(值)。键值存储最大的好处是不用为值指定一个特定的数据类型,这样就能在值里存储任意类型的数据。系统将这些信息按照BLOB大对象进行存储,当收到检索请求时,返回同样的BLOB。由应用来决定被使用的数据是什么类型,如字符串、图片和XML文件等。键值存储数据库的主要特点是具有极高的并发读写性能。
|
|
|
|
|
|
键值存储中的键是很灵活的,可以是图片名称、网页URL或者文件路径名,它们指向那些图片、网页和对应的文档。键可以用很多种格式来表示:
|
|
|
|
|
|
|
|
|
|
|
|
值也很灵活,并且可以是任何BLOB数据,如字符串、图片、网页或视频。下表是一个键值存储的示例。
|
|
|
|
|
|
|
|
|
|
键值存储中存在三种操作:put、get和delete。这三种操作规定了程序员与键值存储交互的基本方式。应用开发者使用put、get和delete函数访问和操作键值存储:
|
|
|
|
(1)put($key as xs:string,$value as item())对表添加一个新的键值对,并且当键存在时,更新键对应的值。
|
|
|
|
(2)get($key as xs:string)as item()根据给出的任意键返回键对应的值,如果键值存储中没有该键,将返回一个错误信息。
|
|
|
|
(3)delete($key as xs:string)将键和对应的值从表中删除,如果键值存储中没有该键,将返回一个错误信息。
|
|
|
|
|
|
键值存储的数据库根据数据的保存方式可以分为临时性、永久性和两者兼具三种。
|
|
|
|
|
|
临时性的保存有可能丢失数据。这类数据库一般把数据都保存在内存中,这样读和写的速度都非常快,但是当数据库停止或者机器重启后,数据就不存在了。由于数据保存在内存中,所以也无法操作超过内存容量的数据,旧的数据会丢失。特点可以总结如下:
|
|
|
|
|
|
|
|
|
|
|
|
永久性的保存不会丢失数据。这类数据库一般不把数据保存在内存中,而是把数据保存在硬盘上。与临时性在内存中读和写数据比较起来,由于牵扯到对硬盘的I/O操作,所以性能上的差距是显而易见的。但是它的最大优势是不会丢失数据。特点可以总结如下:
|
|
|
|
|
|
|
|
|
|
|
|
这类数据库兼具临时性保存和永久性保存的优点。比如典型的Redis系统,它首先把数据保存在内存中,平时都在内存中进行读和写操作。在满足特定条件(缺省是15分钟一次以上,5分钟10个以上或1分钟1000个以上的键发生变化)时,将数据写入到硬盘上保存。这样既确保了内存中数据处理的高速性,又通过写入硬盘来保证数据的永久性。这种类型的数据库特别适合处理数组类型的数据,特点可以总结如下:
|
|
|
|
|
|
|
|
|
|
|
|
键值存储产品主要有亚马逊的Memcached、Redis、Dynamo、Project Voldemort、Tokyo Tyrant、Riak、Scalaries这几个数据库,这里主要介绍一下Memcached和Redis。
|
|
|
|
|
|
Memcached属于前面分类中的临时性保存类型,是高性能的分布式内存对象缓存系统。一般的使用目的是,通过缓存数据库查询结果,减少数据库访问次数,以提高动态Web应用的速度、提高可扩展性。它和共享内存、APC等本地缓存的区别在于Memcached是分布式的,也就是说它不是本地的。它基于网络连接方式完成服务,本身它是一个独立于应用的程序或守护进程。
|
|
|
|
Memcached使用libevent库实现网络连接服务,理论上可以处理无限多的连接,但是它和Apache不同,它更多的时候是面向稳定的持续连接的,所以它实际的并发能力是有限制的。Memcached内存使用方式也和APC不同。后者是基于共享内存和MMAP的,Memcached有自己的内存分配算法和管理方式,它和共享内存没有关系,也没有共享内存的限制。
|
|
|
|
正如所有的NoSQL数据库一样,Memcached也有其特定的应用场合。Memcached常作为数据库前段Cache使用。因为它比数据库少了很多SQL解析、磁盘操作等开销,而且它是使用内存来管理数据的,所以它可以提供比直接读取数据库更好的性能。另外,Memcached也常作为服务器直接数据共享的存储媒介,例如SSO系统中保持系统单点登录状态的数据就可以保持在Memcached中,被多个应用共享。
|
|
|
|
在实际应用中,通常会把数据库查询的结果集保存到Memcached中,下次访问时直接从Memcached中获取,而不再做数据库查询操作,这样可以在很大程度上减轻数据库的负担。通常会将SQL语句md5()之后的值作为唯一标识符key。下边是一个利用Memcached来缓存数据库查询结果集的示例(此代码片段紧接上边的示例代码):
|
|
|
|
|
|
可以看出,使用Memcached之后,可以减少数据库连接、查询操作,数据库负载下来了,脚本的运行速度也提高了。
|
|
|
|
|
|
Redis是一种主要基于内存存储和运行,能够快速响应的键值数据库,属于临时和永久兼具类型,有点像Memcached,整个数据库统统加载在内存当中进行操作,但是通过定期异步操作把数据库数据flush到硬盘上进行保存。因为是纯内存操作,Redis的性能非常出色,每秒可以处理超过10万次读写操作。
|
|
|
|
Redis的出色之处不仅仅是性能,Redis最大的魅力是支持保存List链表和Set集合的数据结构,而且还支持对List进行各种操作。此外单个value的最大限制是1GB,不像Memcached只能保存1MB的数据。其主要缺点是数据库容易受到物理内存的限制,不能用作海量数据的高性能读写,并且它没有原生的可扩展机制,不具有扩展能力,要依赖客户端来实现分布式读写,因此Redis适合的场景主要局限在较小数据量的高性能操作和运算上。
|
|
|
|
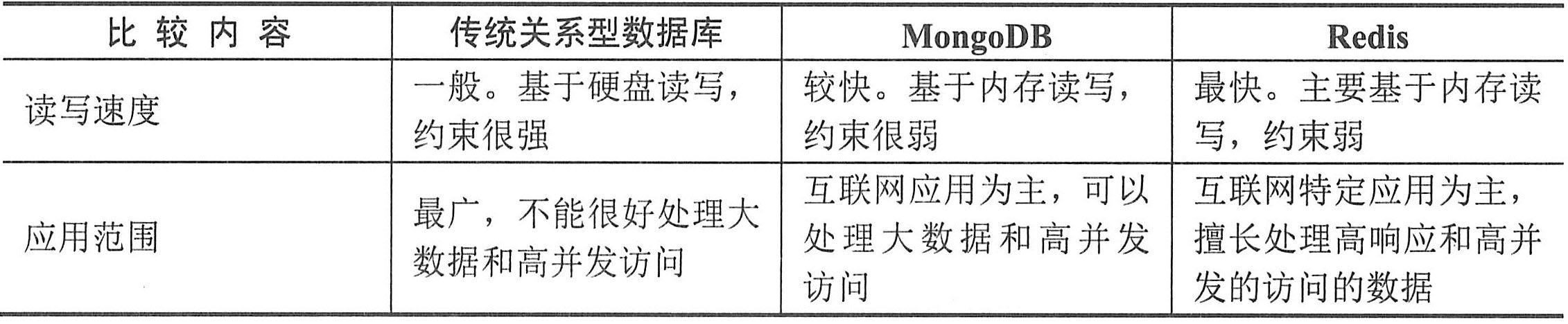
将传统关系型数据库、MongoDB和Redis的特点做一个简单对比。如下表所示,读写响应性能上,传统关系型数据库一般,MongoDB类似于磁盘读写的NoSQL数据库速度较快,基于内存存储的Redis数据库最快。但是传统关系型数据库应用范围广泛,后两者以互联网应用为主。在当前互联网环境下,许多大型网站需要这种处理高并发和高响应的内存数据应用。
|
|
|
|
|
|
传统关系型数据库和MongoDB、Redis的比较
|
|
|
|
Redis的数据库存储模式,是基于键值(Key-Value)基本存储原理,进行细化分类,构建了具有自身特点的数据结构类型。像MySQL这样的关系型数据库,表的结构比较复杂,会包含很多字段,可以通过SQL语句,来实现非常复杂的查询需求。而Redis客户只包含“键”和“值”两部分,只能通过“键”来查询“值”。正是因为这样简单的存储结构,也让Redis的读写效率非常高。键的数据类型是字符串,但是为了丰富数据存储的方式,方便开发者使用,值的数据类型很多,它们分别是字符串、列表、字典、集合、有序集合。在对数据进行各种命令操作之前,首先要掌握Redis的数据结构类型特点。
|
|
|
|
字符串是Redis数据库最简单的数据结构,形式如下表所示,字符串值的内容是二进制的,意味着可以把数字、文本、图片、视频等都赋给这个值,最大长度不能超过512MB。键名的命名要容易阅读,方便系统维护;键名不要太长,否则会影响数据库执行效率。
|
|
|
|
|
|
|
|
列表由若干插入顺序的字符串组成,支持存储一组数据。这种数据类型对应两种实现方法,一种是压缩列表,另一种是双向循环链表。列表中存储的数据量比较小的时候,列表就可以采用压缩列表的方式实现。压缩列表由Redis自己设计实现,类似于数组,通过一片连续的内存空间存储数据,在读写操作时只能从其两头开始(由链表的寻址方式所决定)。不过,它跟数组不同的一点是Redis允许存储的数据大小不同。如下表所示,将700010看作表头的第一个结点字符串数据,结尾是700012字符串。值的内容允许重复出现。列表可用于聊天记录、博客评论等无需调整字符串顺序但又需要快速响应的场景。
|
|
|
|
|
|
|
|
集合是由不重复且无序的字符串元素组成的整体,结构如下表所示,集合与列表最主要的区别是,集合里面所有字符串是唯一的;所有字符串的读写顺序是任意的,不存在从两头操作的问题。
|
|
|
|
|
|
|
|
散列表可以存储多个键值对的映射,是无序的一种数据集合。只有在数据存储数据量比较小的情况下,Redis才使用散列表进行操作,如下表所示。键的内容必须是唯一的,不能重复,且字符串不宜过长,以免占用过多内存,影响执行效率。使用“:”等隔离符号增加可读性,并给使用者提供更大的存储空间。值可以是字符串类型也可以是数字型。散列表特别适用于存储一个对象,会占更少的内存,并且方便存取整个对象。
|
|
|
|
|
|
|
|
有序集合的键被称为成员(member),每个成员都是各不相同的。有序集合的值则被称为分值(score),分值必须为浮点数。有序集合是Redis里面唯一一个既可以根据成员访问元素,又可以根据分值以及分值的排列顺序访问元素的结构,如下表所示。有序集合的值自动进行排序,键字符串必须唯一,值可以重复。由于采用自动值排序,在数据量较多的情况下,检索速度比散列表快。
|
|
|
|
|
|
|
|
|
|
传统的关系型数据库都是以行为单位来进行数据的存储的,擅长进行以行为单位的数据处理,比如特定条件数据的获取。因此,关系型数据库也被称为面向行的数据库。相反,面向列的数据库是以列作为单位来进行数据的存储的,擅长进行以列为单位的数据处理。下表所示为面向行和面向列的数据库的比较。
|
|
|
|
|
|
|
|
面向列的数据库具有高扩展性,即使数据增加也不会降低相应的处理速度,所有它主要应用于需要处理大量数据的情况。另外,利用面向列的数据库的优势,把它作为批处理程序的存储器来对大量数据进行更新也是非常有用的。
|
|
|
|
列存储数据库,主要产品有Google的Bigtable、由Bigtable衍生的Hypertable和HBase、Cassandra这几个数据库。
|
|
|
|
|
|
在过去数年中,Google为在PC集群上运行的可伸缩计算基础设施设计建造了三个关键部分。第一个关键的基础设施是Google File System(GFS),这是一个高可用的文件系统,提供了一个全局的命名空间。它通过跨机器的文件数据复制来达到高可用性,并因此免受传统文件系统无法避免的许多失败的影响,比如电源、内存和网络端口等失败。第二个基础设施是名为Map-Reduce的计算框架,它与GFS紧密协作,帮助处理收集到的海量数据。第三个基础设施就是Bigtable,它是传统数据库的替代。Bigtable让你可以通过一些主键来组织海量数据,并实现高效的查询。Bigtable的具体细节在9.2.3节中已有所叙述,在此不再赘述。
|
|
|
|
|
|
Hypertable是一个开源、高性能、可伸缩的数据库,是Bigtable的一个开源实现,它采用与Google的Bigtable相似的模型。
|
|
|
|
|
|
HBase,即Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
|
|
|
|
HBase同Hypertable一样,是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable利用Chubby作为协同服务,HBase利用Zookeeper作为对应。
|
|
|
|
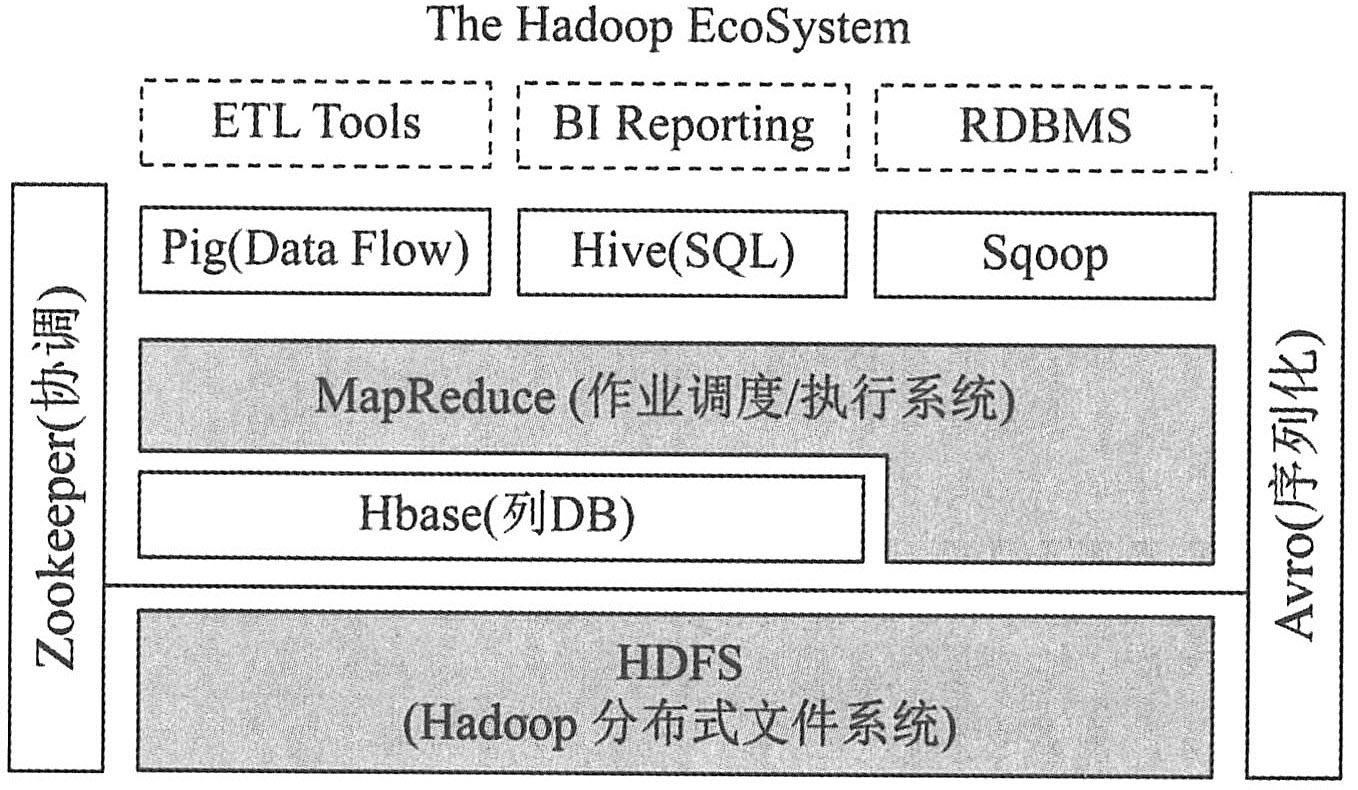
下图描述了Hadoop EcoSystem中的各层系统,其中HBase位于结构化存储层。
|
|
|
|
|
|
|
|
HDFS为HBase提供了高可靠性的底层存储支持,Hadoop MapReduce为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定服务和failover机制。另外,Pig和Hive为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变得非常简单。Sqoop则为HBase提供了方便的RDBMS数据导入功能,使得传统数据库数据向HBase中迁移变得非常方便。
|
|
|
|
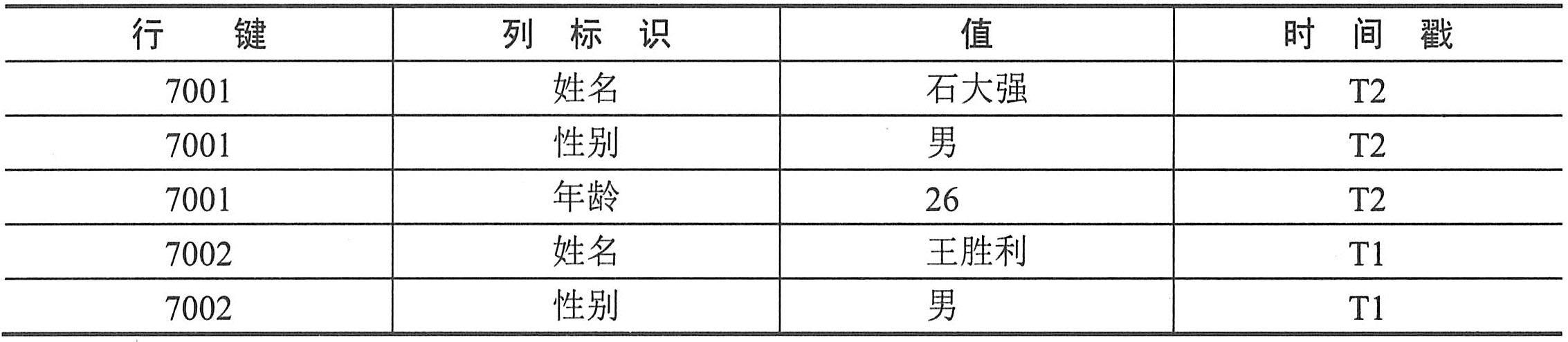
表是Hbase中数据的逻辑组织方式,从用户视角,HBase表的逻辑模型如下表所示。HBase中一个表有若干行,每一行有多个列族,每个列族中包含多个列,列中的值有多个版本。下表展示的是HBase中员工信息表,有三行记录和两个列族,行键分别是7001、7002和7003,两个列族分别是Info和Salary,每一族中含有若干列,如列族Info中包含姓名、性别和年龄三列,列族Salary中包括一月、二月和三月三列。在Hbase中,列不是固定的表结构,在创建表时,不用预先定义列名,可以在插入数据时临时创建。
|
|
|
|
|
|
|
|
从上表的逻辑模型来看,HBase表与关系型数据库中的表结构之间似乎没有太大差异,只不过多了列族概念。但实际上是有很大差别的,关系型数据库中表的结构需要预先定义,如列名及其数据类型和值域等内容。如果需要添加新列,则需要修改表结构,这会对已有的数据产生很大影响。同时,关系型数据库中的表为每个列预留了存储空间,即上表中的空白单元格数据在关系型数据库中以“Null”值占用存储空间。因此,对稀疏数据来说,关系型数据库表中就会产生很多“Null”值,消耗大量的存储空间。
|
|
|
|
在HBase中,如上表的空白单元格在物理上是不占用存储空间的,即不会存储空白的键值对。因此,若一个请求为获取行键为7002在T1时间的Info:年龄的值时,其结果为Null。类似地,若一个请求为获取行键为7003在T2时间的Salary:二月的值时,其结果也为空。与面向行存储的关系型数据库不同,HBase是面向列存储的,且在实际的物理存储中,列族是分开存储的,即上表中的员工信息表将被存储为Info和Salary两个部分。且空白单元格是没有被存储下来的。下表展示了Info这个列族的实际物理存储方式,列族Salary的存储与之类似。从下表可以看出“Null”是没有被存储下来的。
|
|
|
|
|
|
|
|
|
|
Cassandra最初由Facebook开发,用于存储特别大的数据,是一套开源的分布式数据库,结合了Dynamo的键值与Bigtable的面向列的特点。它是一个混合型的NoSQL数据库,其主要功能比键值存储Dynamo更丰富,但支持力度却并不如文档存储MongoDB。它的主要特性是:分布式、基于column的结构化、高扩展性。
|
|
|
|
Cassandra是一个网络社交云计算方面理想的数据库。以Amazon专有的完全分布式的Dynamo为基础,结合了Google Bigtable基于列族的数据模型,P2P去中心化的存储。故很多方面都可以称之为Dynamo 2.0。
|
|
|
|
Cassandra的主要特点就是它不是一个数据库,而是由一堆数据库节点共同构成的一个分布式网络服务,对Cassandra的一个写操作,会被复制到其他节点上去,对Cassandra的读操作,也会被路由到某个节点上面去读取。对于一个Cassandra群集来说,扩展性能是比较简单的事情,只管在群集里面添加节点就可以了。和其他数据库比较,其突出特点是:模式灵活、真正的扩展性、多数据中心识别、范围查询、列表数据结构、分布式写操作。
|
|
|
|
Cassandra的目的是满足大数据量、大量随机的读写操作应用场景下的数据存储需求,更是用于实时事务处理和提供交互型数据的应用。
|
|
|
|
|
|
图存储在那些需要分析对象之间的关系或者通过一个特定的方式访问图中所有节点的应用中尤为重要。图存储针对有效存储图节点和联系进行了优化,让你可以对这些图结构进行查询。图数据库对于那些对象之间具有复杂关系的业务问题很有用,如社交网路、规则引擎、生成组合和那些需要快速分析复杂网络结果并从中找出模式的图系统。
|
|
|
|
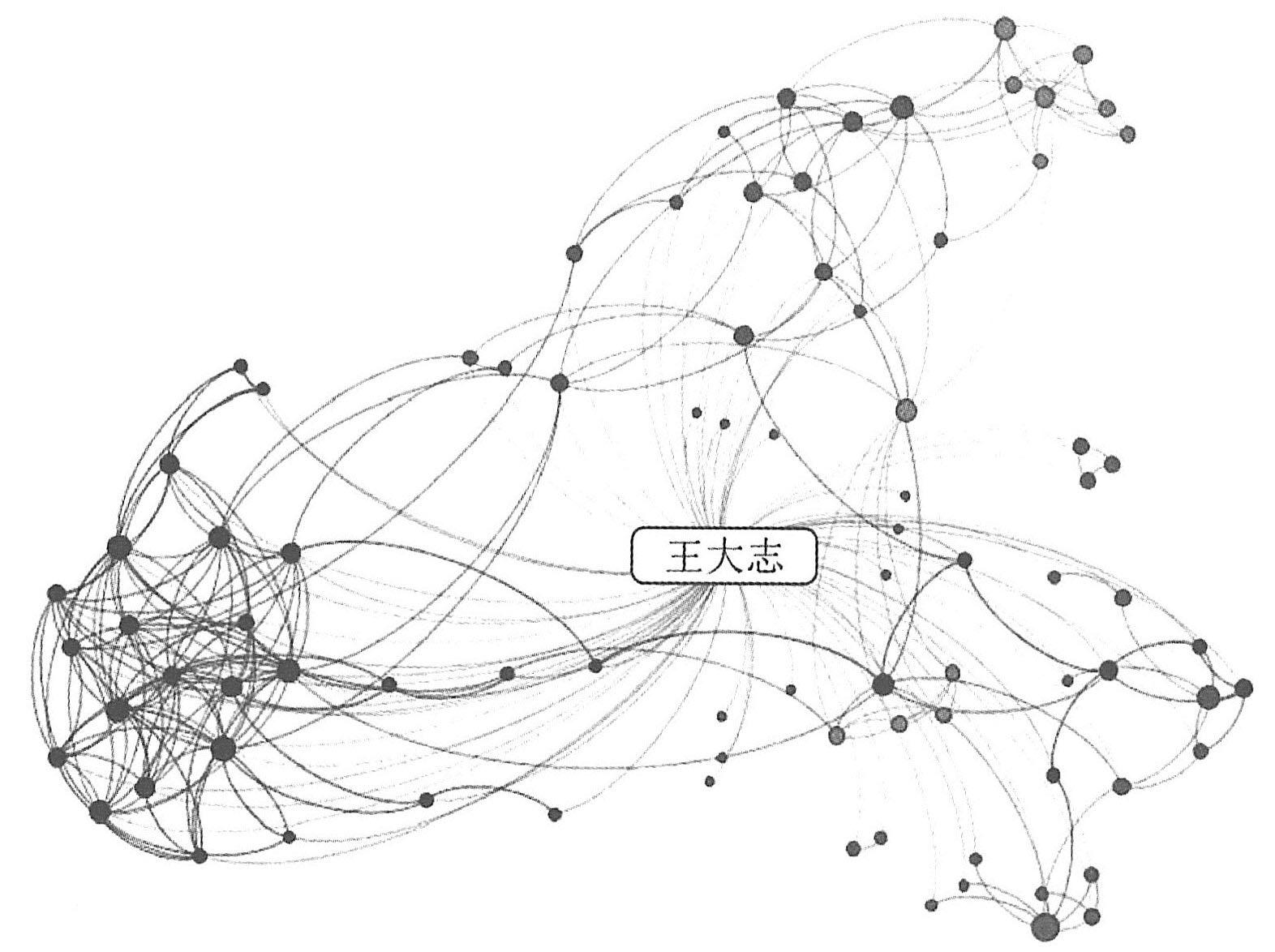
图存储是一个包含一连串的节点和关系的系统,当它们结合在一起时,就构成了一个图。图存储有三个字段:节点、关系和属性。图节点通常是现实世界中对象的表现,如人名、组织、电话号码、网页或计算机节点。而关系可以被认为是这些对象之间的联系,通常被表示为图中两个节点之间连接线。如下图是“王大志”这个人的社交网络示意图,从图中可以看出与他建立直接或者间接联系的朋友的数量,以及不同朋友之间的紧密程度。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
如果图存储的节点众多、关系复杂、属性很多,那么传统的关系型数据库将要建很多大型的表,并且表的很多列可能是空的,在查询时还极有可能进行多重SQL语句的嵌套。可是图存储就可以很优异,基于图的很多高效的算法可以大大提高执行效率。
|
|
|
|
现总结一下图数据库和传统的关系型数据库在一些问题处理上的不同,如下表所示。
|
|
|
|
|
|
|
|
在很长一段时间里,图数据库只局限在学术圈子中,直到电子商务的业务模型逐渐成熟,挖掘用户的潜在喜好商品,并大量使用相关的挖掘算法,才使得图数据库逐渐“走出来”。目前常见的一些图数据库如下表所示。
|
|
|
|
|
|
|
|
其中,比较成熟的是Twitter的FlockDB。FlockDB是一个分布式的图数据库,但是它并没有优化遍历图的操作。它优化的操作包括:超大规模邻接矩阵查询,快速读写和可分页查询;它主要是要解决可伸缩性的问题,通俗点说就是通过增加服务器就能解决用户量上升造成的访问压力,而不需要在软件上做大的变动。FlockDB将图存储为一个边的集合,每条边用两个代表顶点的64位整数表示。对于一个社会化网络图,这些顶点ID即用户ID,但是对于“收藏”推文这样的边,其目标顶点(destination id)则是一条推文的ID。每一条边都被一个64位的位置信息标识,用于排序。(Twitter在“关注”类的边上用了时间戳标识,所以如果你的关注者列表是按时间排序的,那么总是最新的在最前面。)
|
|
|
|
对于一条复杂的查询,通常会被分解成一些单用户查询,并很快响应。数据根据节点分块,所以这些查询能分别在各自的数据块,通过一个索引过的范围查询得到结果。类似地,遍历一个长结果集是用位置作为游标,而不是用LIMIT/OFFSET,所有页的数据均被索引,访问一样快。
|
|
|
|
Neo4j也是一个典型的图数据库。它提供了大规模可扩展性,在一台机器上可以处理数十亿节点/关系/属性的图像,可以扩展到多台机器并行运行。相对于关系数据库来说,图数据库善于处理大量复杂、互连接、低结构化的数据,这些数据变化迅速,需要频繁的查询。在关系数据库中,这些查询会导致大量的表连接,因此会产生性能上的问题。Neo4j重点解决了拥有大量连接的传统RDBMS在查询时出现的性能衰退问题。通过围绕图进行数据建模,Neo4j会以相同的速度遍历节点与边,其遍历速度与构成图的数据量没有任何关系。此外,Neo4j还提供了非常快的图算法、推荐系统和OLAP风格的分析,而这一切在目前的RDBMS系统中都是无法实现的。
|
|
|
|
|
|
NoSQL数据库除了文档存储、键值存储、列存储和图存储四种主流的存储方式外,还有其他类型的数据库,在此做简要的介绍。
|
|
|
|
|
|
多值数据库系统是分布式数据库系统的重要分支。它速度快,体积小,比关系数据库便宜,很快得到了认可。它提供了一个通用的数据集成与访问平台,屏蔽了现有各数据库系统不同的访问方法和用户界面,给用户呈现出一个访问多种数据库的公共接口。多值数据库系统使用的多个异构的数据源之间可以共享它们相互依赖的数据,并具有相互操作的能力。这种技术将在电子政务、电子商务、企业信息集成、军事指挥、金融证券、办公自动化、远程教育、远程医疗等领域发挥巨大的支撑作用。
|
|
|
|
常见的多值数据库有Rocket U2、Extensible Storage Engin(ESE/NT)、OpenInsight和OpenQM等。
|
|
|
|
其中,Rocket U2包含了UniData和UniVerse两个扩充型关系型数据库,采用多键值存储,支持嵌入式实体,虚拟元数据,具有.NET、socket和Java的API,具有针对快速、经济、垂直应用开发的集成式开发环境。
|
|
|
|
ESE是一种非关系型嵌入式数据库引擎,适用于那些需要高性能、较小存储空间支出的应用。ESENT已经应用于Windows Desktop Search、Windows Live Mail等多个微软产品中。它有高并发的数据库访问,灵活的元数据定义(表、列、索引),支持整形、浮点型、字符型、二进制列的索引等特点。
|
|
|
|
OpenInsight采用TCP/IP协议、命名管道的体系结构,支持远程登录,采用关系的或多键值存储,支持嵌套实体,在关系型的存储结构中,表的行和大小可动态改变。
|
|
|
|
OpenQM的商业版本支持Windows、Linux(RedHat、Fedora、Debian、Ubuntu)、FreeBSD、Mac OS X和Windows Mobile等,商业版本包括一个GUI管理界面和终端模拟器,但开源版本仅包括核心多值数据库引擎,主要是为开发人员准备的。OpenQM支持嵌套数据,能够高度自动化地分配表空间,通过多种锁机制来控制并行计算,采用QMBasic(集成了面向对象的编程机制)来进行快速开发。
|
|
|
|
|
|
时间序列数据库是指具有处理时间序列数据,能对时间数据数组建立索引的优化数据库系统。时序数据与每个人存在紧密联系。如电商系统获取每笔订单交易金额和支付金额的价格曲线,随时间变化的温度轨迹,能量消耗的负荷消耗断面轮廓等。这些曲线、轨迹、轮廓被统称为时间序列。
|
|
|
|
流数据库又被称为实时数据库,这是一种使用实时处理数据的方式来处理状态不断变化的数据库系统。对时间序列的数据库提出实时的处理要求,那么时间数据库就是流数据库。例如股票的价格、自动驾驶汽车的数据曲线等都需要实时计算处理,此时流数据库发挥巨大作用。
|
|
|
|
归结起来,业务场景选择时间序列与流数据库这类NoSQL数据库而非通用的数据库有两个核心原因:
|
|
|
|
(1)规模:时间序列的数据积累速度很快。在当前的物联网时代,一辆联网的汽车每小时产生的数据达到几百GB。关系型数据库处理这种大型数据集的效果糟糕,而针对时间序列数据微调过后的数据库能够很好地处理规模数据。时间数据库将时间作为最高优先级处理,通过提高区间数据实时查询效率来处理这种大规模数据,并带来性能的提升,包括:每秒的写入速度,能够支撑的设备指标量,读取数据的速率和高存储压缩比。
|
|
|
|
(2)可用性:时间序列数据库有一些特有的功能和操作,如数据保留策略、连续查询、灵活的时间聚合等。并且其具有很好的扩展性,如时序数据插值计算,降精度计算,聚合计算等,在非时序数据库中都不具备这种能力。
|
|
|
|
企业开发人员越来越多地采用时间序列数据库,并将它们用于各种使用场景。这里介绍两种常见的时间序列数据库InfluxDB、OpenTSDB。
|
|
|
|
InfluxDB是一款专业的时序数据库,只存储时序数据,因此在数据模型的存储上可以针对时序数据做非常多的优化工作。为了保证写入的高效,InfluxDB也采用LSM(Log-Structured Merge Tree)结构,这种结构的核心思想是放弃部分的读能力,换取写入的最大化能力。数据先写入内存,当内存容量达到一定阈值之后更新到文件。这种设计是将时间序列数据按照时间线挑出来,同一数据源的标签不再冗余存储,另一方面给定数据源和时间范围的数据查找,实现了倒排索引增强了多维条件查询的功能,拥有强大的聚合功能,可以非常高效地进行查找。
|
|
|
|
OpenTSDB基于HBase存储时序数据,以metric为单位,metric就是1个监控项,譬如服务器的话,会有CPU使用率、内存使用率这些metric,并且数据存储支持到秒级别。OpenTSDB支持数据永久存储,即保存的数据不会主动删除,并且原始数据会一直保存(有些监控系统会将较久之前的数据聚合之后保存)。
|
|
|
|
|
|
网格和云数据库(Grid&Cloud Database)是基于网格计算或者云计算的数据库。云计算是一种随需计算或者效用计算,允许用户无需了解底层IT基础设施架构,就能通过互联网访问各种基于IT资源的服务。网格计算可以理解为“虚拟超级计算机”,以松耦合的方式将大量的计算资源连接在一起提供单个计算资源无法完成的计算能力。二者的意义在于,即使本地资源有限,个人和企业开发者也可通过网络进行复杂运算,这个计算过程后端实现是透明的。
|
|
|
|
四类主流的数据库提供基于云服务的能力,满足个人和企业基于云平台部署的业务发展需要,如最新的文档存储MongoDB、Amazon DynamoDB。但是这里的网格和云数据库与这四类数据库有两个显著区分特点:第一个特点,网格和云数据库有明显的网格计算或者云计算特征,如基于大数据的计算、实时数据流的计算和分布式计算等;第二个特点,网格数据库和云数据库天生是为了网格计算或云计算而产生的,它们是绝对的专业户,而基于云平台提供服务的数据库只能算是可以在云平台上正常使用的某类数据库,即普通用户。目前,主流的数据库产品有GridGain和CrateDB。
|
|
|
|
CrateDB是开源的大规模可伸缩的数据存储系统,提供强大的搜索功能。它使用SQL处理各种表格数据、非结构化数据和二进制对象,并且支持高可用性和实时大规模并行访问和处理。
|
|
|
|
GridGain内存数据库可支撑OLTP、OLAP或者混合事务/分析处理使用场景,服务器集群中分发数据集,为此能比基于磁盘的数据库快千倍;而分布式SQL功能可以使用标准数据库命令通过ODBC/JDBC接口读取和写入数据库,提供巨大的数据库可扩展性。
|
|
|