|
|
|
|
|
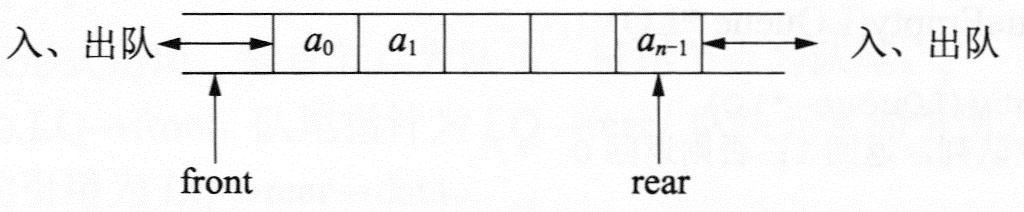
队列(queue)是一种只允许在一端进行插入,而在另一端进行删除的线性表,是一种操作受限的线性表。在表中只允许进行插入的一端称为队尾(rear),只允许进行删除的一端称为队头(front)。队列的插入操作通常称为入队列或进队列,而队列的删除操作则称为出队列或退队列。当队列中无数据元素时,称为空队列。
|
|
|
|
由队列的定义可知,队头元素总是最先进队列的,也总是最先出队列;队尾元素总是最后进队列,因而也是最后出队列。这种表是按照先进先出(First In First Out, FIFO)的原则组织数据的,因此,队列也被称为"先进先出"表。
|
|
|
|
下图是一个队列的进出示意图,通常用指针front指示队头的位置,用指针rear指向队尾的位置。
|
|
|
|
|
|
|
|
|
|
|
|
.InitQueue(&Q):初始化操作,构造一个队列Q。
|
|
|
|
.QueueEmpty(Q):若栈Q为空队列,返回1,否则返回0。
|
|
|
|
.EQueue(&Q, e):插入元素e到队列Q的尾部。
|
|
|
|
.OQueue(&Q,&e):删除Q的队首元素,并用e返回其值。
|
|
|
|
.GetQhead(Q,&e):用e返回Q的队首元素。
|
|
|
|
|
|
|
|
顺序存储结构采用一维数组(向量)实现,设队列头指针front和队列尾指针rear,并且假设front指向队头元素的前一位置,rear指向队尾元素。若不考虑队满,则入队操作语句为Q[rear++]=x;若不考虑队空,则出队操作语句为x=Q[++front]。当然,出队时,并不一定需要队头元素(与退栈类似)。
|
|
|
|
按上述的做法,有可能出现假溢出,即队尾已到达一维数组的高端,不能再入队,但因为连续出队,队列中元素个数并未达到最大值。解决这种问题,可用循环队列。在循环队列中,需要区分队空和队满:仍用front=rear表示队列空,在牺牲一个单元的前提下,用front==(rear+1)% MAX表示队列满。在这种约定下,入队操作的语句为:rear=(rear+1)%MAX, MAX, Q[rear]=x;出队操作语句为:front=(front+1)% MAX。
|
|
|
|
|
|
|
|
顺序队列定义为一个结构类型,该类型变量有3个数据域:data、front、rear。其中data为存储队中元素的一维数组。队头指针front和队尾指针rear定义为整型变量,取值范围是0~QueueSize-1。约定队尾指针指示队尾元素在一维数组中的当前位置,队头指针指示队头元素在一维数组中的当前位置的前一个位置,这种顺序队列说明如下。
|
|
|
|
.初始化时,设置SQ.front=SQ.rear=0。
|
|
|
|
.队头指针的引用为SQ.front,队尾指针的引用为SQ.rear。
|
|
|
|
.队空的条件为SQ.front==SQ.rear;队满的条件为SQ.front=(SQ.rear+1)% QueueSize。
|
|
|
|
.入队操作:在队列未满时,队尾指针先加1(要取模),再送值到队尾指针指向的空闲元素。出队操作:在队列非空时,队头指针先加1(要取模),再从队头指针指向的队头元素处取值。
|
|
|
|
.队列长度为(SQ.rear+QueueSize-SQ.front)% QueueSize。
|
|
|
|
特别应注意的是:在循环队列的操作中队头指针、队尾指针加1时,都要取模,以保持其值不出界。
|
|
|
|
|
|
1)初始化initqueue(SQueue *SQ)
|
|
|
|
|
|
2)判空QueueEmpty(SQueue SQ)
|
|
|
|
|
|
3)入队EQueue(SQueue *SQ, ElemType e)
|
|
|
|
|
|
4)出队OQueue(SQueue *SQ, ElemType *e)
|
|
|
|
|
|
5)取队首元素GetQhead(SQueue *SQ, ElemType *e)
|
|
|
|
|
|
6)清队列ClearQueue(SQueue *SQ)
|
|
|
|
|
|
|
|
队列的链接实现称为链队,链队实际上是一个同时带有头指针和尾指针的单链表。头指针指向队头节点,尾指针指向队尾节点即单链表的最后一个节点。为了简便,链队设计成一个带头节点的单链表。
|
|
|
|
|
|
|
|
|
|
.队列以链表形式出现,链首节点为队头,链尾节点为队尾。
|
|
|
|
.队头指针为LQ→front,队尾指针为LQ→rear,队头元素的引用为Q→front→data,队尾元素的引用为LQ→rear→data。
|
|
|
|
.初始化时,设置LQ→front=LQ→rear=NULL。
|
|
|
|
.进队操作与链表中链尾插入操作一样;出队操作与链表中链首删除操作一样。
|
|
|
|
.队空的条件为LQ→front==NULL。理论上,只要系统内存足够大,链队是不会满的。
|
|
|
|
|
|
1)队列初始化InitQueue(LQueue *LQ)
|
|
|
|
|
|
2)入队EQueue(LQueue *LQ, ElemType e)
|
|
|
|
|
|
3)出队OQueue(LQueue *LQ, ElemType *e)
|
|
|
|
|
|
4)判空QueueEmpty(LQueue *LQ)
|
|
|
|
|
|
5)取队首元素GetQhead(LQueue *LQ, ElemType *e)
|
|
|
|
|
|
6)清队列ClearQueue(LQueue *LQ)
|
|
|
|
|
|
|
|
判别循环队列的"空"或"满"不能以头尾指针是否相等来确定,一般是通过以下几种方法:一是另设一个布尔变量来区别队列的空和满;二是少用一个元素的空间,每次入队前测试入队后头尾指针是否会重合,如果会重合就认为队列已满;三是设置一个计数器记录队列中元素总数,不仅可判别空或满,还可以得到队列中元素的个数。
|
|
|
|
|
|
双端队列是限定插入和删除操作在线性表的两端进行,可将其看成是栈底连在一起的两个栈,但其与两个栈共享存储空间是不同的。共享存储空间中的两个栈的栈顶指针是向两端扩展的,因而每个栈只需一个指针;而双端队列允许两端进行插入和删除元素,因而每个端点必须设立两个指针,如下图所示。
|
|
|
|
|
|
|
|
在实际应用中,可对双端队列的输出进行限制(即一个端点允许插入和删除,另一个端点只允许插入),也可对双端队列的输入进行限制(即一个端点允许插入和删除,另一个端点只允许删除)。可见,采用双端队列可增加应用中的灵活性。
|
|
|