|
|
|
MongoDB是10gen公司开发的以高性能和可扩展性为特征的文档型数据库,也是NoSQL文档存储模式数据库中的重要一员。MongoDB的最大特点就是无表结构。在保存数据和数据结构的时候,会把数据和数据结构都完整地以BSON的形式保存起来(BSON是JSON的二进制编码格式,但比JSON支持更加复杂的格式,在空间利用上更加高效,支持的数据类型如下表所示),并把它作为值和特定的键进行关联。正是由于这种设计,使得它不需要表结构,而被称为文档型数据库。
|
|
|
|
|
|
|
|
|
|
这里说的文档,是一种可以嵌套的数据集合。从关系数据库的范式的概念来说,嵌套是明显的反范式设计。范式设计的好处是消除了依赖,但是增加了关联,查询需要通过关联两张或者多张表来获得所需要的全部数据,但是更改操作是原子的,只需要修改一个地方即可。反范式则是增加了数据冗余来提升查询性能,但更新操作可能需要更新冗余的多处数据,需要注意一致性的问题。
|
|
|
|
由于MongoDB最大的特点就是无表结构,无论是定义还是使用,所以,对于任何关键字,它都可以像关系型数据库那样进行复杂的查询。此外,MongoDB拥有比关系型数据库更快的速度,而且,可以像关系型数据库那样通过添加索引来进行高速处理。
|
|
|
|
根据它的特点,可以通过“添加字段”“查询数据”这两个操作看出MongoDB与传统的关系型数据库相比的优势与不足,如下表所示。
|
|
|
|
|
|
|
|
因此,在实际应用中,我们要根据MongoDB的特点灵活使用:在最初的设计时就避免join查询的使用,当然,可以在最开始的时候就将必要的数据嵌入到文档中去,这可以实现同样的功能。
|
|
|
|
除此之外,MongoDB有它自己的通信协议,有几种语言的socket驱动。MongoDB还有强大的查询语言可以和SQL相媲美,它的查询语言同样支持Map/reduce函数。此外,MongoDB的分区方法采用的是“读写分离”,以主从模式对数据进行复制和修改。
|
|
|
|
|
|
(1)高性能:提供JSON、XML等可嵌入数据快速处理功能;提供文档的索引功能,相对传统数据库而言,大大提高查询速度。
|
|
|
|
(2)丰富的查询语言:为数据聚合、结构文档、地理空间提供丰富的查询功能。
|
|
|
|
(3)高可用性:提供数据冗余处理和故障自动转移的功能。
|
|
|
|
(4)水平扩展能力:通过集群将数据分布到多台机器,而不是只提升单个节点的性能,具体处理分为主从和权衡两种处理模式。
|
|
|
|
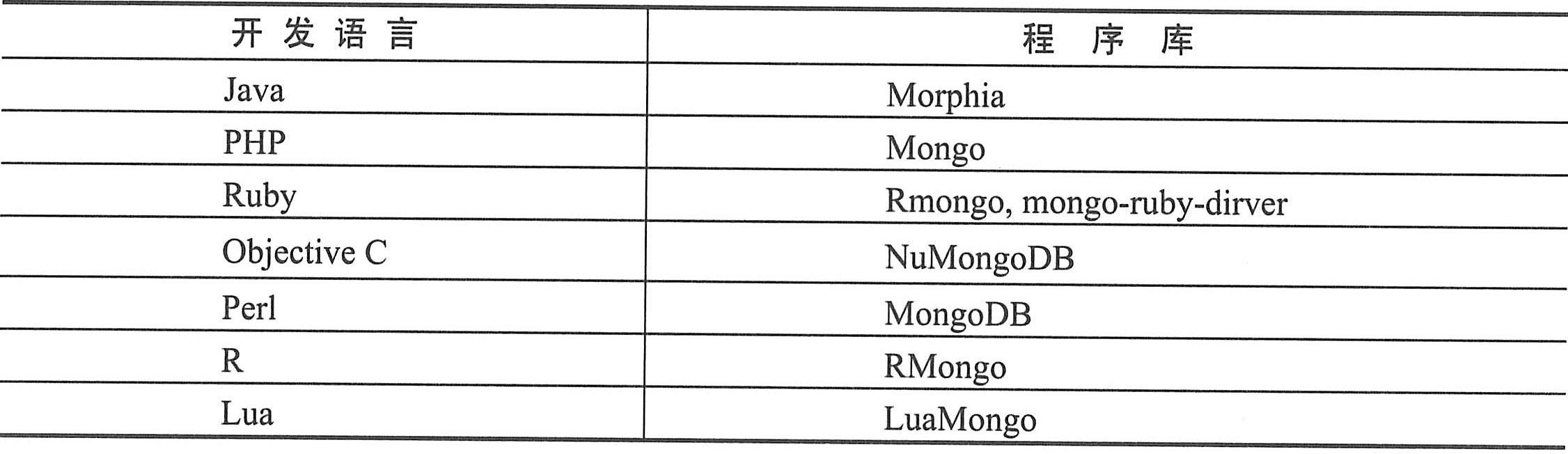
MangoDB为C、C#、.NET、Java、PHP等各种开发语言提供了程序库,如下表所示。
|
|
|
|
|
|
|
|
Java驱动程序是MongoDB最早的驱动,它已经使用多年,而且非常稳定,是企业级开发的首选。下面使用Java驱动程序来举一个各种汽车信息统计的搜索引擎的例子,每种汽车收集的信息都不同,本例子的目的是使得这些信息都能被搜索到。
|
|
|
|
|
|
|
|
MangoDB能存放任意数量、任意属性的被统计信息,这样应用就能轻易扩展,但目前还不能对当前的格式进行有效的索引。MangoDB索引可以将数组的每一个元素进行涵盖,所以可以将想要索引的属性放到一个保护常用键名的数组中。例如,对于宝马汽车,可以为索引添加一个数组,将全部属性放到数组中:
|
|
|
|
|
|
|
|
|
|
现在只要创建一个“index.name”和“index.value”的复合索引就行了。使用Java代码举例,使用ensureIndex函数建复合索引:
|
|
|
|
|
|
|
|
|
|
只要实现了java.util.List,就可以用来表示数组,所以用java.tuil.ArrayList来存放表示汽车不同属性信息的内嵌文档。
|
|
|