|
|
|
响应支持运维是运维人员针对服务请求或故障申报而进行的响应性支持服务,包括变更管理、故障管理等。响应支持运维过程中需要关注的要素如下表所示。
|
|
|
|
|
|
|
|
响应支持过程将形成无形和有形两种形式的成果,如下表所示。
|
|
|
|
|
|
|
|
响应支持作业根据响应的前提不同,分为事件驱动响应、服务请求响应和应急响应。
|
|
|
|
|
|
事件驱动响应是指由于不可预测原因导致服务对象整体或部分功能丧失、性能下降,触发将服务对象恢复到正常状态的服务活动。事件驱动响应的触发条件包括外部事件、系统事件和安全事件三种。外部事件指为信息系统设施运行提供支撑的、协议获得的、不可控的、非自主运维的资源,如互联网、租赁的机房等由服务中断引发的事件;系统事件指运维标的物范围内的、自主管理和运维的系统资源服务中断引发的事件;安全事件指安全边界破坏、安全措施或安全设施失效造成的安全等级下降和用户利益被非法侵害的事件。
|
|
|
|
|
|
|
|
(1)空调系统:故障排查,关闭部分机组以维持机房最低温/湿度指标等。
|
|
|
|
(2)供配电系统:故障排查,投入备用电源回路,关闭非重要回路等。
|
|
|
|
|
|
(4)UPS系统:故障排查,旁路系统,关闭非重要输出等。
|
|
|
|
(5)消防系统:故障排查,系统启动,报警联动,疏散警示等。
|
|
|
|
(6)安全系统:手动开启或关闭门禁系统,检查告警或监视记录等。
|
|
|
|
|
|
主要包括按预定义级别的网络通信相关故障发生所启动的响应支持,特定事件或时间所驱动的响应支持,信息系统变更所驱动的响应支持,信息系统故障所驱动的响应支持,灾难性事件所驱动的响应支持。
|
|
|
|
|
|
主要包括针对硬件设施故障引起的业务中断或运行效率无法满足正常运行要求等,例如:
|
|
|
|
|
|
(2)服务器通信模块故障导致业务通信中断(如网卡损坏)。
|
|
|
|
(3)服务器文件系统异常导致操作系统运行缓慢,从而引起业务交易超时。
|
|
|
|
(4)数据库软件异常导致数据库停止,从而引起业务交易中断。
|
|
|
|
(5)主机、存储光纤卡异常引起数据无法读/写,导致业务无法正常执行等。
|
|
|
|
|
|
主要包括针对基础软件故障引起的业务中断或运行效率无法满足正常运行要求,例如:
|
|
|
|
|
|
|
|
(3)主机、通信模块或网络设备故障导致数据库连接中断。
|
|
|
|
(4)主机硬盘、光纤卡或存储异常引起数据无法读/写,导致数据库宕机。
|
|
|
|
(5)主机CPU、磁盘、数据库表空间等资源耗尽导致数据库系统运行缓慢。
|
|
|
|
|
|
(7)数据库配置变更导致数据库系统异常或运行缓慢。
|
|
|
|
|
|
|
|
|
|
|
|
服务请求响应是指由于各类服务请求引发的针对服务对象、服务等级做出调整或修改的响应型服务。此类响应可能涉及服务等级变更、服务范围变更、技术资源变更、服务提供方式变更等。
|
|
|
|
|
|
|
|
|
|
(2)供配电系统:增减回路,增减供电类型(如直流、110V)等。
|
|
|
|
|
|
|
|
(5)消防系统:增减终端设备,检查及提供告警及监控记录,备份或清除记录等。
|
|
|
|
|
|
指对网络及网络设备的操作作业请求,如增加、降低网络接入的数量或速度,更改网络设备配置等进行的响应服务。
|
|
|
|
|
|
指对硬件设施的操作作业请求,如启动、关闭端口或服务;更换、更新或升级设备硬件等进行的响应服务,如设备搬迁、设备停机演练、设备清洁维护、系统参数调整和文件系统空间扩容等。
|
|
|
|
|
|
指针对基础软件,根据信息系统软件运行需要或相关方的请求而进行的响应服务。如数据库版本升级、数据库灾难恢复、数据库调优、数据库数据移植、数据清理、中间件服务器更换、中间件参数调整和软件版本升级等。
|
|
|
|
|
|
应急响应是指组织为预防、监控、处置和管理运维服务应急事件所采取的措施和行为。信息系统设施运维应急事件是指导致或即将导致信息系统设施运行中断、运行质量降低或需要实施重点时段保障的事件。当出现跨越预定的应急响应阈值的重大事件,或由于政府部门发出行政指令或对运维对象提出要求时,应当启动应急处理程序。
|
|
|
|
应急响应是信息系统设施运维中的一个重要组成部分,针对突发公共事件,国家和地方政府出台的各项总体预案和专项预案,从整体或专业角度,对预防与应急准备、监测与预警、应急处置与救援、事后恢复与重建等方面进行了规定。但在信息技术运维领域,与之相对应的应急响应规范尚未建立起来。
|
|
|
|
应急响应的管理是为了避免无序运维,提升应急状态下的运维响应能力,提前发现和解决问题,降低突发事件造成的不良影响,以合理的投入创造更大的效益。
|
|
|
|
应急响应过程包括应急准备、监测与预警、应急处置和总结改进四个主要环节,如下图所示。
|
|
|
|
|
|
|
|
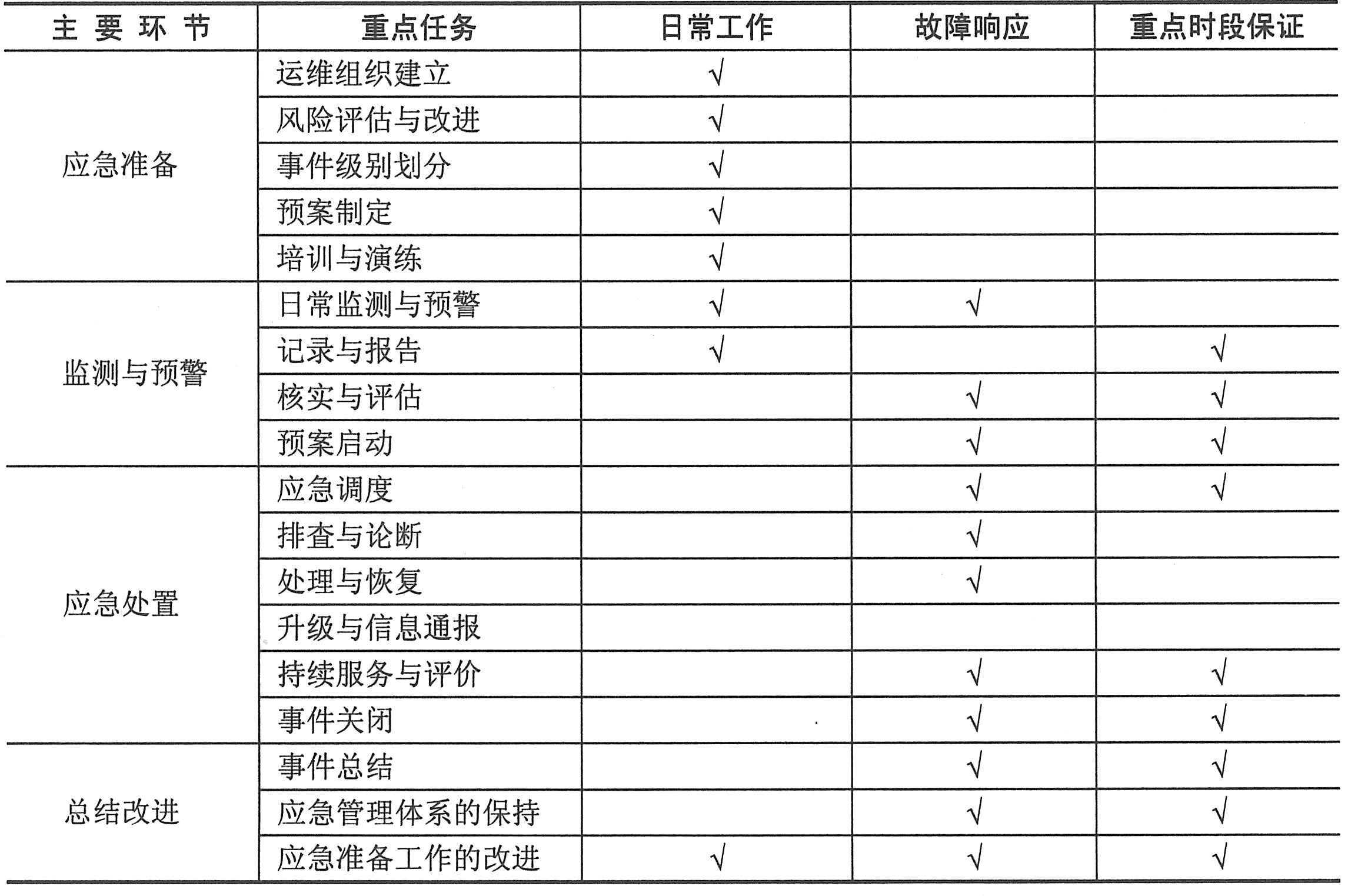
每个环节中包括若干重点任务,这些任务覆盖了日常工作、故障响应和重点时段保障等不同类型的活动。应急响应的活动与任务如下表所示。
|
|
|
|
|
|
|
|
|
|
(1)建立应急管理的组织和制度:建立应急管理组织,确保组建合适的组织以满足日常运维和应急响应的服务要求,明确应急响应组织中的角色及关系。应急管理组织建立后对应的应急管理制度包括负责制定应急响应方针(应急响应原则、范围等),明确应急响应的范围、要求、等级等。
|
|
|
|
(2)风险评估与改进:风险评估与改进的目的是系统地识别运维服务对象及运维活动中可能出现的风险并提前改进,包括风险识别与评估、风险应对。
|
|
|
|
运维人员从系统的角度识别风险要素,如运维对象、运维内容、组织及流程接口等。根据风险要素,应急响应组织按照一个确定的方法和流程来实施风险评估,明确其在其运维过程中的关键活动、所需资源、限制条件及组织面临的各种威胁,明确当威胁演变为应急事件时所产生的影响和后果,以及业务中断可能带来的损失。分析评估后应形成《风险评估报告》,报告应包括与服务水平目标相比较的运维要求、现状及趋势信息、风险要素、不符合项及问题等,并据此提出纠正措施建议,确认后的《风险评估报告》将作为风险应对预案。
|
|
|
|
对于识别出的各种风险,制定明确的应对策略,包括风险规避、风险转嫁、风险降低、风险接受等。根据《风险评估报告》,形成《系统改进方案》以降低风险,包括降低风险转变为应急事件的可能性,缩短应急事件的持续时间,限制应急事件的影响范围。
|
|
|
|
(3)应急事件级别划分:应急事件分级的主要参考要素为信息系统的重要程度、紧急程度、系统损失和社会影响。相关负责人按照以上要素对可能发生的事件进行评估。确定应急事件的级别。包括以下内容。
|
|
|
|
灾难事件(Ⅰ级):指由地震、火灾、恐怖袭击等原因造成主要IT设施毁灭性损坏,或者由于系统平台或业务数据遭受严重破坏,无法在短时间内恢复系统服务,造成核心业务服务中断超过48小时。
|
|
|
|
重大事件(Ⅱ级):指造成核心业务服务中断超过24小时,或重要业务数据丢失,或业务数据需要后退到上一备份状态。
|
|
|
|
严重事件(Ⅲ级):指造成核心业务服务中断超过12小时,或少量业务数据丢失。
|
|
|
|
一般事件(Ⅳ级):指造成核心业务服务中断超过4小时,或管理支撑系统服务中断超过24小时。
|
|
|
|
(4)预案制定:预案制定的目的是提供应对运维应急事件的操作性文件。
|
|
|
|
根据风险评估和事件级别划分制定《应急响应预案》。预案可以分为总体预案和针对某个核心系统的专项预案及其附则;预案中应该考虑到各种应急资源的调配和预置,主要包括人员、备品备件、资金、系统工具等。《应急响应预案》的内容包括应急响应预案的编制目的、依据和适用范围;具体的组织体系结构及人员职责;应急响应的监测和预警机制;应急响应的启动;应急响应的处置;应急响应的总结;应急响应的保障措施;应急预案的附则等。
|
|
|
|
经过评审确认的应急响应预案,由责任者或授权管理者负责预案的分发,同时建立预案的版本控制。
|
|
|
|
(5)培训与演练:培训需要制定应急响应培训计划,并组织相关人员参与,将应急响应预案作为培训的主要内容。培训应使得相关组织及人员明确其在应急响应过程中的责任范围、接口关系,明确应急处置的操作规范和操作流程。
|
|
|
|
应急响应演练的目的,一是为了验证预案是否能够真正满足实际的需求,二是为了检验应急响应小组成员之间相互配合的默契程度和对运维事件应对步骤的熟练程度。演练的方式分为工具测试演练和场景模拟演练。
|
|
|
|
为了检验预案的有效性,同时使相关人员了解运维预案的目标和流程,熟悉应急响应的操作规程,应急响应的演练应做到:预先制定演练计划,在计划中说明测试工具或演练的场景;演练的整个过程有详细的记录,并形成报告;演练不能对业务运行造成负面影响;按照约定周期,进行完整演练(可以有被委托的第三方机构参与),周期建议可以设定为季度、一年或三年。
|
|
|
|
|
|
(1)日常监测与预警:日常监测与预警负责保障运维服务的可用和连续,及时发现运维服务应急事件并有效预警。结合运维服务级别协议和应急响应预案,开展日常监测与预警活动,主要包括设立服务台并保持运营;确定监测项、监测时间间隔与阈值;确定活动中的人员、角色和职责。可以采用运维工具与人工相结合的方式开展日常监测与预警活动。
|
|
|
|
(2)记录与报告:建立监测、预警信息登记和报告制度。对日常监测结果进行记录,发现运维服务应急事件时,应提交单独的报告,报告内容应包括故障或预警发生及发现的时间和地点;表象及影响的范围;原因初步分析;报告人等。对运维应急事件要保持持续性跟踪。
|
|
|
|
(3)核实与评估:核实与评估负责对出现的运维服务应急事件进行有效识别。其中核实是指接到报告的责任者应对报告内容进行逐项核实,以判别运维服务应急事件是否属实;事件级别评估是指负责人应参见应急准备活动中的事件级别划分,确定应急事件所对应的事件级别,同时将事件级别置于动态调整控制中。
|
|
|
|
(4)预案启动:确保以规定的策略和程序启动预案,并保持对应急事件的跟踪。
|
|
|
|
建立、审议预案启动的策略和程序,以控制预案启动的授权和实施。对预案启动可能造成的影响进行评估,在相关方之间就启动何种类型预案达成一致,过程包括一旦事件升级,与之相对应的预案调整的方式,同时记录预案启动的过程和结果。
|
|
|
|
信息通报内容包括预案启动的原因、事件级别、事件对应的预案、要求采取的技术应对或处置的目标、实现目标所应采取的保障措施,如人员、物资、环境、资金等;对应急处置过程及结果的报告要求,如报告程序、报告内容、报告频率等;信息通报的方式可以是电话、邮件、电视、广播和文件等。相关方对收到的通报信息进行确认和反馈。
|
|
|
|
应急响应人员根据调整后的状态开展监测与预警活动,并按一致约定的程序和监测范围、监测频率提供报告。
|
|
|
|
|
|
(1)应急调度:在应急调度中明确应急调度手段,规范应急调度过程;在调度安排下,相关人员实施应急处置,责任者根据应急处置要求,对应急处置经费、应急处置人员、应急处置设施等统一调配和管理,并完成调度明细说明的整理和归档。应急调度的工作流程包括在规定时间要求内,迅速组织人员勘察、分析;通过网络、媒体、广播等多种手段快速获取应急事件的相关信息;及时组织并协调相关部门及人员召开应急处置工作会议;根据应急处置要求,对涉及应急处置组织下达调度命令;组织人员保护可追查的相关线索。
|
|
|
|
(2)排查与诊断:排查与诊断是基于已经启动的预案而开展的,在排查与诊断中,应建立多渠道的应急处置支持模式,如建立由服务商、供应商、生产制造商构成的应急处置支持模式。故障排查与诊断的流程包括:应急处置责任者调配处置人员进行现场故障排查;现场处置人员进行故障排查和诊断,必要时可寻求外协人员以现场或远程方式进行支持,在此过程中可借助各类排查、诊断、分析工具,如应用软件、电子分析工具、故障排查知识库等;现场处置人员应随时向处置责任者汇报故障排查情况、诊断信息、故障定位结果等;将排查与诊断的过程和结果信息进行整理与归档。
|
|
|
|
在实施应急处置过程中,各级责任者需要及时与相关利益方进行沟通,沟通的内容主要包括应急处置故障点、造成故障的原因、排查诊断等。及时完成对沟通信息及对应组织人员的核实与确认,同时对确认信息完成归档、上报、审批等事项。
|
|
|
|
(3)处理与恢复:负责对故障进行有效、快速的处理与恢复。应基于预案和知识库进行故障的处理与恢复,处理与恢复的原则应在满足相应服务级别协议要求的前提下,尽快恢复服务;采用的方法、手段不应造成新的事件发生。
|
|
|
|
必要时可启用备品备件、灾备系统等。对过程及结果信息进行记录,并及时告知相关方面和人员。责任者应组织对处理与恢复的结果进行初步确认。
|
|
|
|
(4)升级与信息通报:应急响应组织通过实施有效评审,实现对应急处置的升级与通报;故障处置责任者应组织相关人员对故障处置过程及结果情况进行评审;在评审中,参考服务级别协议中对事件处置内容情况的设定,同时结合应急故障处置的现场情况进行分析和比较。当应急故障现场处置的情况超过原应急预案中的事件处置级别要求时,应作为应急事件升级;建立、审议应急事件升级的策略和程序,以控制应急事件升级的授权和实施,就应急事件升级可能造成的影响进行评估;升级过程包含预案调整、人员调整、资金调整及相关设施调整,需要对应急事件升级的过程和结果信息进行整理与归档。信息通报内容包括事件升级的原因;事件升级后的级别;事件升级后与之对应的预案;根据升级事件处置的要求和目标,确定所需的技术应对措施;实现目标所应采取的保障措施,如人员、物资、环境、资金等;对升级事件处置过程及结果的报告,如报告程序、报告对象、报告内容、报告频率等;信息通报的范围和涉及接受者,信息通报的方式有电话、邮件、电视、广播和文件等形式。
|
|
|
|
(5)持续服务与评价:在完成对应急事件故障处置后,应组织运维人员提供持续性服务,同时应对持续性服务的效果进行评价。
|
|
|
|
(6)事件关闭:规范并明确应急处置的关闭流程,即申请关闭、核实、关闭通报。
|
|
|
|
关闭申请:建立、审议事件关闭的策略和程序,以控制事件关闭的授权和实施;对应急事件处置的过程文档和各评审/评价报告进行整理,由明确的责任者或授权管理者提出事件关闭申请,并提交相关文档资料。
|
|
|
|
关闭核实:接到事件关闭申请的责任者应逐项核实报告内容,以判别应急事件处置过程和结果信息是否属实。
|
|
|
|
关闭通报:建立、审议应急事件关闭通报制度,应急事件关闭的责任者向相关利益方通报信息,内容应包括应急事件的级别;事件对应的预案信息;应急事件处置的过程情况;事件的调整升级情况;持续性服务状况信息;事件处置评价信息;事件关闭申请的处理意见;关闭通报的范围和涉及接受者。
|
|
|
|
|
|
(1)应急事件总结:在事件关闭之后,组织相关人员对本次事件的原因、处理过程和结果进行分析,总结经验教训,并采取必要的后续措施。事件总结应包含事件发生的原因分析、应急事件的处理过程和结果;评估应急事件造成的影响;降低事件发生频率、减轻损害和避免再次发生的方法。
|
|
|
|
调查和收证:当一个事件涉及责任认定、赔偿或诉讼时,应收集、保留和呈递证据。证据可用于内部问题分析;用做有关可能违反合同或规章要求的法律取证;与供应商或其他组织谈判赔偿事宜。
|
|
|
|
(2)应急体系的保持:为保证应急体系的有效性和时效性,需要对应急体系进行不定期及定期的维护和审核,以确保组织具有足够的应急响应能力。
|
|
|
|
体系维护主要是指当组织战略、业务流程、客户要求等发生重大变化时,对现有的应急体系,尤其是风险评估和应急预案进行修改。体系维护应该是不定期进行的,是由事件驱动的。
|
|
|
|
体系审核主要是指对组织当前的应急响应能力和管理模式进行评审,以确保它们符合预定的标准和要求,同时明确组织在应急响应方面的主要不足和改进方向。体系审核应该是定期进行的,组织应该至少一年进行一次体系审核。
|
|
|
|
体系维护:组织建立明确的应急体系维护计划,确保任何影响到组织应急管理的重大变更都能被识别出来,同时采取必要的措施对这些变更进行分析,并对应急管理体系做出相应调整,这种调整可能涉及应急管理的方针策略、流程、应急预案和资源配置。
|
|
|
|
体系维护流程的结果应包括关于应急体系维护活动的文档记录;确保应急响应的相关人员都已经明确应急体系的调整内容,并接受必要的培训;当需要对风险评估、组织架构、人员配备进行调整时,保留必要的文档记录。
|
|
|
|
体系审核:相关责任者按照预定的时间间隔对应急管理体系进行审核,以确保体系具有持续的适用性和有效性。体系审核包括评估体系不足和改进建议。同时,体系审核的结果应正式存档并通知给相关责任者。
|
|
|
|
体系审核的输入信息主要包括相关利益方的要求和反馈;组织所采纳的,用于支持应急响应的各种技术、产品和流程;风险评估的结果及可接受的风险水平;应急预案的测试结果及实际执行效果;上次体系评审的后续跟踪活动;可能影响应急体系的各种业务变更;近期在处置应急事件过程中总结的经验和教训;培训的结果和反馈。
|
|
|
|
体系审核的输出结果主要包括应急体系的改进目标;如何改进应急体系的有效性和效率;所需的各种资源,包括人员、软硬件、资金等。
|
|
|
|
(3)应急准备工作的改进:应急时间总结、体系维护和体系审核的结果将作为应急准备阶段的重要输入信息,组织应根据应急时间总结报告中给出的建议项和体系评审结果来调整应急准备及风险应对的策略。
|
|
|